文献阅读02期:Real-time Personalization using Embeddings for Search Ranking at Airbnb
Posted RaZLeon
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了文献阅读02期:Real-time Personalization using Embeddings for Search Ranking at Airbnb相关的知识,希望对你有一定的参考价值。
[ 文献阅读 ] Outline:Real-time Personalization using Embeddings for Search Ranking at Airbnb
推荐理由:该文获得了 KDD 2018 Applied Data Science Track 的 Best Paper,主要介绍了 Embedding 技术在 Airbnb 房源搜索排序中的应用。Airbnb是目前全世界最大的民宿短租平台,整篇文章与Airbnb自身业务特点紧密结合,非常具有工程实践价值。
关键词: Search Ranking; User Modeling; Personalization;搜索排序;用户模型;个性化;定制化
食用建议:需要掌握NLP中Word Embedding等相关知识。
1.摘要&简介
- 对于求租者与房东们的需求,从模型上来看是有一定差异的,如何用一套系统求解两套问题非常关键。
- 将房东的“拒绝”行为作为一个“Negative word”加入训练集。
- 本文提供了一套以Airbnb为背景的Listing与User Embedding技术。
- 本文针对搜索排序(Search Ranking)以及(Similar Listing Recommendations),提出一套实时的定制化列表方案(Real-time Personalization)。
- 可以满足不同用户的长租或短租需求。
2.研究方法&模型
2.1.列表Embedding(Listing Embeddings)
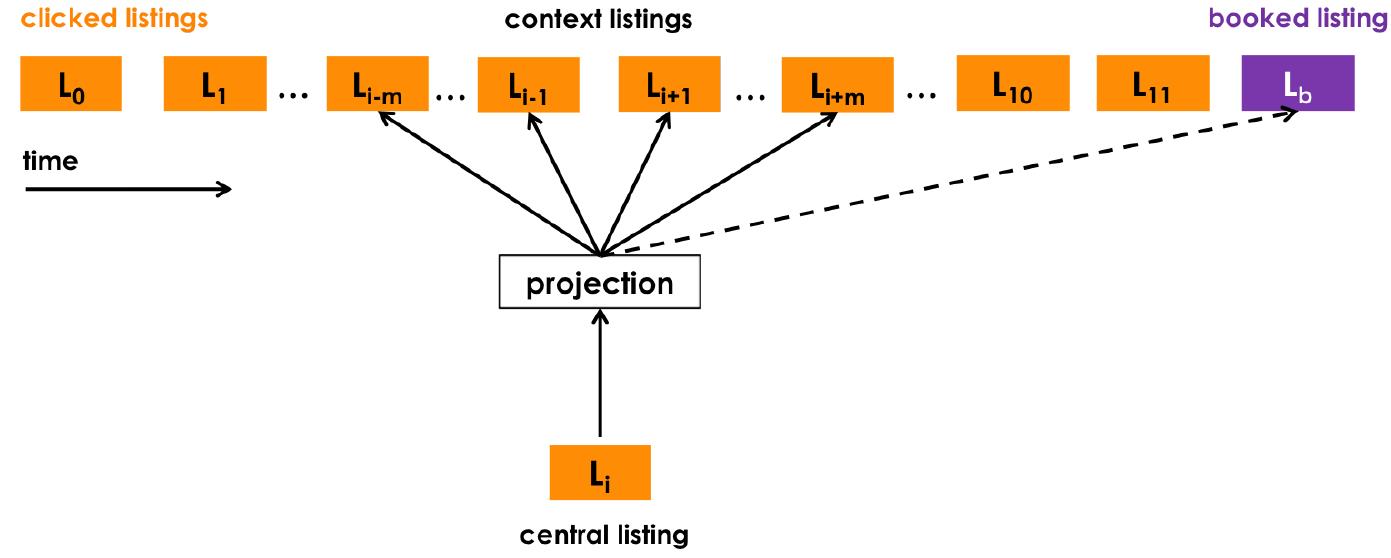
- 假定有一个用户集合 N N N,其中用户点击页面产生了点击集合 S S S(Click Sessions)。
- 其中Click Sessions可以表述为: s = ( l 1 , … , l M ) ∈ S s=\\left(l_{1}, \\ldots, l_{M}\\right) \\in \\mathcal{S} s=(l1,…,lM)∈S,其中为M个用户点击过的不间断id
- 如果点击间断超过30分钟,则会开始一个新的记录Click Session
- 在以上给定数据的背景下,本文的目标是学习一个d维实数值表达:即每个独立的列表 l i l_i li可以表达为: v l i ∈ R d \\mathbf{v}_{l_{i}} \\in \\mathbb{R}^{d} vli∈Rd
- btw. v l i \\mathbf{v}_{l_{i}} vli由Wrod Embedding产生,相近点击的List在Embedding空间当中距离也理应较近。
- 具体来说,本文Embedding的方式为skip-gram[2],但本文的目标函数为下式:
L = ∑ s ∈ S ∑ l i ∈ s ( ∑ − m ≥ j ≤ m , i ≠ 0 log P ( l i + j ∣ l i ) ) (1) \\mathcal{L}=\\sum_{s \\in \\mathcal{S}} \\sum_{l_{i} \\in s}\\left(\\sum_{-m \\geq j \\leq m, i \\neq 0} \\log \\mathbb{P}\\left(l_{i+j} \\mid l_{i}\\right)\\right)\\tag{1} L=s∈S∑li∈s∑⎝⎛−m≥j≤m,i=0∑logP(li+j∣li)⎠⎞(1)
其中 P ( l i + j ∣ l i ) \\mathbb{P}\\left(l_{i+j} \\mid l_{i}\\right) P(li+j∣li)是一种soft-max形式的上下文临近概率,数学表达如下:
P ( l i + j ∣ l i ) = exp ( v l i ⊤ v l i + j ′ ) ∑ l = 1 ∣ V ∣ exp ( v l i ⊤ v l ′ ) (2) \\mathbb{P}\\left(l_{i+j} \\mid l_{i}\\right)=\\frac{\\exp \\left(\\mathbf{v}_{l_{i}}^{\\top} \\mathbf{v}_{l_{i+j}}^{\\prime}\\right)}{\\sum_{l=1}^{|\\mathcal{V}|} \\exp \\left(\\mathbf{v}_{l_{i}}^{\\top} \\mathbf{v}_{l}^{\\prime}\\right)}\\tag{2} P(li+j∣li)=∑l=1∣V∣exp(vli⊤vl′)exp(vli⊤vli+j′)(2)
其中 v l {v}_{l} vl和 v l ′ {v}^{'}_{l} vl′是列表 l l l的输入输出的向量形式表达。超参数 m m m是前后观察上下文(Clicked Lists, 近邻)的长度。 - 在计算梯度 ∇ L \\nabla \\mathcal{L} ∇L的过程中,计算时间会随着列表数量 ∣ V ∣ |\\mathcal{V}| ∣V∣的增加而增加。对于有上百万个点击Lists的训练而言,这几乎是个不可能完成的任务,所以引文[2]中所提出的“负采样”(Negative Sampling)方法将被本文采用,以减少计算复杂度。
- 负采样的具体实施:集合
D
p
\\mathcal{D}_{p}
Dp代表正相关组Positive Pairs
(
l
,
c
)
(l,c)
(l,c)其中
c
c
c为列表
l
l
l的上下文列表(也叫做临近列表);集合
D
n
\\mathcal{D}_{n}
Dn代表负相关组Negative Pairs
(
l
,
c
)
(l,c)
(l,c)其中
c
c
c为列表
l
l
l的上下文列表(也叫做临近列表);基于此,优化目标可以表述为:
argmax θ ∑ ( l , c ) ∈ D p log 1 1 + e − v c ′ v l + ∑ ( l , c ) ∈ D n log 1 1 + e v c ′ v l (3) \\underset{\\theta}{\\operatorname{argmax}} \\sum_{(l, c) \\in \\mathcal{D}_{p}} \\log \\frac{1}{1+e^{-\\mathrm{v}_{c}^{\\prime} \\mathbf{v}_{l}}}+\\sum_{(l, c) \\in \\mathcal{D}_{n}} \\log \\frac{1}{1+e^{\\mathrm{v}_{c}^{\\prime} \\mathbf{v}_{l}}}\\tag{3} θargmax(l,c)∈Dp∑log1+e−vc′vl1+(l,c)∈Dn∑log1+evc′vl1(3) - 采用随机梯度下降
2.1.1.
以上是关于文献阅读02期:Real-time Personalization using Embeddings for Search Ranking at Airbnb的主要内容,如果未能解决你的问题,请参考以下文章