分布式强化学习基础概念(Distributional RL )
Posted The Blog of Xiao Wang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分布式强化学习基础概念(Distributional RL )相关的知识,希望对你有一定的参考价值。
分布式强化学习基础概念(Distributional RL)
from: https://mtomassoli.github.io/2017/12/08/distributional_rl/
1. Q-learning
在 Q-learning 中,我们想要优化如下的 loss:
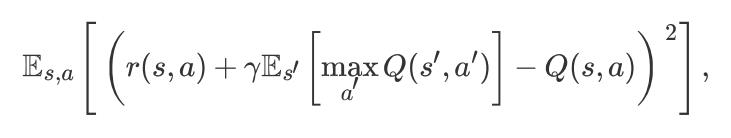
Distributional RL 的主要思想是:to work directly with the full distribution of the return rather than with its expectation.
假设随机变量 Z(s, a) 是获得的回报(return),那么:Q(s, a) = E(Z(s, a)) ; 并非像公式(1)中所要最小化的误差那样,也就是 期望的距离。
我们可以直接最小化这两个分布之间的距离,which is a distance between full distribution:
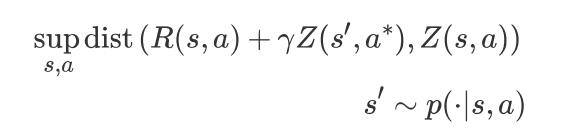
其中,R(s, a) 是即刻奖赏的随机变量,sup 是函数值的上界的意思,英文解释为:supremum。并且:
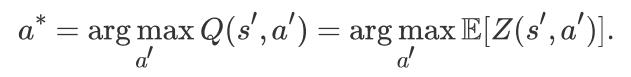
注意的是,我们依然用的是 Q(s, a),但是,此处我们尝试优化 distributions,而不是这些分布的期望。
2. Policy Evaluation:
Reference Paper:
1. https://arxiv.org/pdf/1707.06887.pdf
2. https://arxiv.org/pdf/1710.10044.pdf
以上是关于分布式强化学习基础概念(Distributional RL )的主要内容,如果未能解决你的问题,请参考以下文章
快速了解前沿知识:区块链/机器学习/回归算法/人工神经网络/支持向量机/强化学习/网络空间安全/云计算/雾计算/深度学习/卷积神经网络/生成对抗网络的一些基础概念