强化学习基础
Posted 哇咔咔FF
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了强化学习基础相关的知识,希望对你有一定的参考价值。
强化学习
强化学习概念
强化学习(RL)就是智能体Agent与环境交互从而进行学习的一种机器学习方法。Agent执行一个动作后,会从环境中画的反馈,这个反馈就是环境对这个动作做出的评价(这个可以理解为当你拿100分时,你妈妈会给你一顿大餐的反馈,而当你拿0分时,你妈妈会给你一个耳光的反馈),这是一个试错的过程。
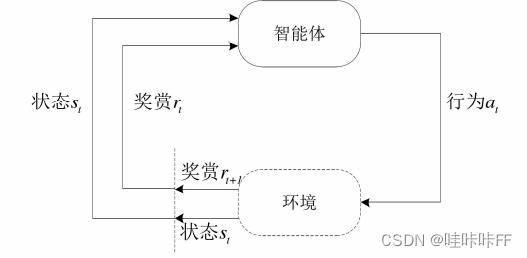
强化学习的目标是使每执行一个动作以后都能得到最大的立即奖赏,我们要做的就是要训练Agent让他知道在什么状态下做什么动作可以获得最好的反馈。
综上可知,强化学习方法的学习过程是一种试探过程,通过试探不断增大最优动作被选中的概率,从而寻找到一组最优解。
强化学习组成
Agent在所处的环境进行探索学习就构成了强化学习系统,奖赏函数可以知道Agent进行学习,值函数记录Agent学到的经验,动作选择策略权衡探索和利用两者的关系,为的是不让智能体陷入局部最优策略。
奖赏函数
奖赏函数会给予Agent所做的动作一个评价,评价执行这个动作后对最终结果的影响,数值越大表示效果越好,反之表示效果不好。由于强化学习是一个马尔科夫决策过程,所以他要实现的目标是找到一组动作序列,使得累计奖赏最大。
(1)连续性奖赏函数:
R
n
=
f
(
s
t
,
i
t
)
\\beginalign R_n=f(s_t,i_t) \\endalign
Rn=f(st,it)
连续性奖赏函数通过建立一个状态和环境反馈之间的一个函数,使得智能体在每个状态都能获得环境的评价。
(2)离散型奖赏函数
R t = 1 执行最优动作 − 1 执行最差动作 0 其他情况 \\beginalign R_t=\\left\\ \\beginaligned 1 & & 执行最优动作 \\\\ -1 & & 执行最差动作 \\\\ 0 & & 其他情况 \\endaligned \\right. \\endalign Rt=⎩ ⎨ ⎧1−10执行最优动作执行最差动作其他情况
值函数
奖赏函数给出的是Agent做出动作之后的立即奖赏,而值函数是计算的当前状态下做出的动作对完成目标任务的影响,侧重于实现整体策略的最大化。随着训练的进行,值函数不断优化达到收敛,在每一个状态通过策略
π
∗
=
a
r
g
m
a
x
V
π
(
s
)
π^*=argmaxV^π(s)
π∗=argmaxVπ(s)选择动作,既保证了每个动作获得的最大奖赏都是最大的,又可以使整个策略获得的累计折扣奖赏最大。
(1)有限非折扣累积奖赏值函数:
V
π
(
s
t
)
=
∑
t
=
0
h
r
t
\\beginalign V^π(s_t)=\\displaystyle\\sum_t=0^h r_t \\endalign
Vπ(st)=t=0∑hrt
其中
r
t
r_t
rt为Agent再t时刻获得立即奖赏,累计奖赏是起始状态到目标状态的所获得的立即奖赏的累加。
(2)无限折扣奖赏值函数:
V
π
(
s
t
)
=
∑
i
=
0
∞
γ
i
r
t
+
i
,
0
≤
γ
≤
1
\\beginalign V^π(s_t)=\\displaystyle\\sum_i=0^\\infty\\gamma^ir_t+i,0\\leq\\gamma\\leq1 \\endalign
Vπ(st)=i=0∑∞γirt+i,0≤γ≤1
γ
\\gamma
γ为折扣因子,
0
≤
γ
≤
1
0\\leq\\gamma\\leq1
0≤γ≤1。他代表的是累计奖赏中未来奖赏所占的比例。
γ
\\gamma
γ越小代表越看重当前动作的奖赏,
γ
\\gamma
γ越大越看重未来的奖赏。
(3)平均奖赏值函数:
V
π
(
s
t
)
=
lim
h
→
∞
(
1
h
∑
t
=
0
h
r
t
)
\\beginalign V^π(s_t)=\\lim_h \\to \\infty(\\frac1h\\displaystyle\\sum_t=0^hr_t) \\endalign
Vπ(st)=h→∞lim(h1t=0∑hrt)
平均奖赏值函数是对Agent所获得的所有奖赏值取平均值。
动作选择策略
通俗的来理解就是Agent在什么状态下应该选择什么动作去执行,这里很多人认为我每次执行反馈最好的动作不就好了吗,但其实不是这样的,这样很有可能会陷入局部最优,就是说我现在有一个比较好的反馈动作了,但这个动作可能不是最好的,我依然需要去探索,去试试其他动作好还是不好。
(1)greedy动作选择策略
greedy动作选择策略只会选择当前最优的动作,而这个动作可能不是最好的。从而用这个动作选择策略可能会隐藏该动作空间中最优动作。
π
∗
=
a
r
g
m
a
x
V
π
(
s
)
\\beginalign π^*=argmaxV^π(s) \\endalign
π∗=argmaxVπ(s)
(2)
ϵ
\\epsilon
ϵ-greedy动作选择策略
π
∗
=
a
r
g
m
a
x
V
π
(
s
)
1
−
ϵ
r
a
n
d
(
a
)
ϵ
\\beginalign π^*=\\left\\ \\beginaligned argmaxV^π(s) & & 1-\\epsilon\\\\ rand(a)& & \\epsilon \\endaligned \\right. \\endalign
π∗=argmaxVπ(s)rand(a)1−ϵϵ
在学习的初期Agent会通过
ϵ
\\epsilon
ϵ的概率再动作空间中随机选择动作进行探索,通过
1
−
ϵ
1-\\epsilon
1−ϵ的概率选择当前状态下已知的最有动作。
(3)softmax动作选择策略
p
(
a
i
∣
s
)
=
k
V
i
/
T
∑
a
∈
A
k
V
i
/
T
\\beginalign p(a_i|s)=\\frack^V_i/T\\displaystyle\\sum_a\\inA^k^V_i/T \\endalign
p(ai∣s)=a∈A∑kVi/TkVi/T
T为温度控制系数,刚开始T值很大所以
V
i
V_i
Vi造成的影响就不是很大,各个动作基本可以以同等概率被选到,训练后期T值逐渐减小,
V
i
V_i
Vi的权重也就增大,即最优动作被选中的概率明显提升。
强化学习经典算法
动态规划算法
动态规划算法选择最优策略的方法是使用值函数进行迭代,但要求环境中的状态转移概率和奖赏函数是已知的,然后利用动作策略与环境进行交互,在训练中优化最优值函数 V π ∗ V^π^* Vπ∗和最优策略 π ∗ π^* π