基础知识十六强化学习
Posted AYE89
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基础知识十六强化学习相关的知识,希望对你有一定的参考价值。
一、任务与奖赏
我们执行某个操作a时,仅能得到一个当前的反馈r(可以假设服从某种分布),这个过程抽象出来就是“强化学习”。
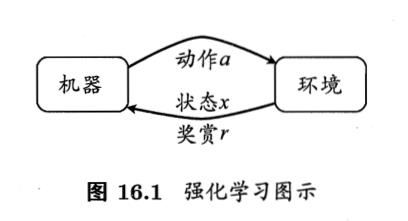
强化学习任务通常用马尔可夫决策过程MDP来描述:
强化学习任务的四要素
E = <X, A, P, R>
E:机器处于的环境
X:状态空间
A:动作空间
P:状态转移概率
R:奖赏函数
学习目的:
“策略”:机器要做的是不断尝试学得一个“策略” π,根据状态x就能得到要执行的动作 a = π(x)
策略的评价:
长期累积奖赏,常用的有“T步累积奖赏”
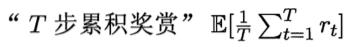
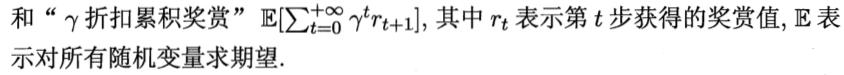
强化学习与监督学习的差别
“策略”实际相当于监督学习中的“分类器”(或“回归器”)
“动作”对应于“标记”
不同的是,强化学习没有监督学习中的“示例-标记”对
二、K-摇臂赌博机
一般地,一个动作的奖赏值是来自于一个概率分布。
1. 探索与利用
探索:将所有尝试机会平均分配给每个摇臂——用于估计每个动作带来的奖赏
利用:按下目前最优的(即到目前为止平均奖赏最大的)摇臂,若有多个摇臂同为最优,则从中随机选取一个——用于执行奖赏最大的动作
面临“探索-利用窘境”
2. ε-贪心
以ε的概率进行探索,以 1-ε的概率进行利用
若摇臂奖赏的不确定性较大,例如概率分布较宽时,需要较大的ε值;
3.softmax
基于当前已知的摇臂平均奖赏来对探索和利用进行折中:若某些摇臂的平均奖赏明显高于其他摇臂,则它们被选取的概率也明显更高
三、多步强化学习任务
有模型学习:
解决方法:策略迭代与值迭代
1. “状态评估算法”(基于T步累积奖赏的策略评估算法),用于求状态值函数V(.),进而可以求出状态-动作函数Q(.)
2. “策略迭代”——初始策略,策略评估,然后策略改进……不断迭代
“值迭代”——策略改进与值函数的改进是一致的,因此可以将策略改进视为值函数的改善(于是可以得到“值迭代”算法)
免模型学习:
蒙特卡罗强化学习
时序差分学习
四、值函数近似
前面一直假定强化学习任务是在有限状态空间上进行的,每个状态可用一个编号来指代;值函数是关于有限状态的“表格值函数”,即值函数能表示为一个数组
如果强化学习的状态空间是连续的,有无穷多个状态,如何处理?——“值函数近似”
即直接对连续状态空间的值函数进行学习
五、模仿学习
现实任务中,往往能得到“人类专家的决策过程范例”,从这样的范例中学习,称为“模仿学习”。
1. 直接模仿学习
可将所有轨迹上的所有“状态-动作对”抽取出来,构造出一个新的数据集合D,
即把状态作为特征,动作作为标记,对新构造出来的数据集合D使用分类(对于离散动作)学得策略模型
学得的这个策略模型可作为机器进行强化学习的初始策略,再通过强化学习方法基于环境反馈进行改进,获得更好的策略。
2. 逆强化学习
设计奖赏函数往往相当困难(正向),反过来从人类专家提供的范例数据中反推出奖赏函数(逆向),有助于问题解决
#补充:
1. 时序差分TD学习,著名应用是跳棋,达到人类世界冠军水平
2. 模仿学习被认为是强化学习提速的重要手段
3. 运筹学与控制论领域,强化学习被称为“近似动态规划”
以上是关于基础知识十六强化学习的主要内容,如果未能解决你的问题,请参考以下文章