强化学习入门
Posted Jie Qiao
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了强化学习入门相关的知识,希望对你有一定的参考价值。
文章目录
- 基本概念
- state value function
- state-action value function(Q-function)
- Optimal Value Function
- 强化学习分类
- Model-based
- Model-free
- 参考资料
基本概念

Agent : 是程序里面的决策者,他们需要根据环境交互来做出决策.
Environment :agent会在里面交互.
State : 环境中的状态,比如agent的位置,时间等等。不同的action会有不同的reward.
环境有些是可观测的(比如reward),有些是不可观测的。强化学习的任务就是优化累计reward。
state value function
强化学习最重要的就是计算累计的reward,我们希望能够找到一个平均累计reward最优的policy,而Value Function正是一种用于计算期望累计reward的函数。而state value function刻画了,在给定某个policy下,如果当前状态为s,那么一直到最后结束的期望累计reward是多少:
V π ( s ) ≐ E π [ G t ∣ S t = s ] = E π [ ∑ k = 0 ∞ γ k R t + k + 1 ∣ S t = s ] , for all s ∈ S V^\\pi (s)\\doteq E_\\pi [G_t |S_t =s]=E_\\pi [\\sum _k=0^\\infty \\gamma ^k R_t+k+1 |S_t =s],\\text for all s\\in S Vπ(s)≐Eπ[Gt∣St=s]=Eπ[k=0∑∞γkRt+k+1∣St=s], for all s∈S
在这里 γ \\displaystyle \\gamma γ是折扣系数,这是考虑了未来的时间其reward可能没有当前的重要,并且每一个时间步t都会根据给定的策略 π \\displaystyle \\pi π来决定每一步的action:
π ( a ∣ s ) = P ( A t = a ∣ S t = s ) \\pi (a|s)=P(A_t =a|S_t =s) π(a∣s)=P(At=a∣St=s)
从公式来看, V π ( s ) \\displaystyle V^\\pi (s) Vπ(s)测量了在当前state=s,使用policy π \\displaystyle \\pi π下,未来的累积reward的期望值。
需要注意的是,在这里,初始状态的action都是通过policy得到的,而如果初始状态的action是给定的话这个value function 将被称为state-action value function (Q-function)。举个例子,假设一个游戏每走一步的reward是-1,现在还差一步就要结束了,并且我们使用的是最优的polocy,如果使用state value function,我们的 V π ( s ) = − 1 \\displaystyle V^\\pi (s)=-1 Vπ(s)=−1,选择直接选择结束游戏(因为还差一步),但如果指定一个action a \\displaystyle a a且这个action往外回了一步(-1),那么走到终点需要再走两步,于是 Q π ( s , a ) = − 3 \\displaystyle Q^\\pi (s,a)=-3 Qπ(s,a)=−3,这就是state-value function与state-action value function的区别。
我们考虑一个计算reward的例子:
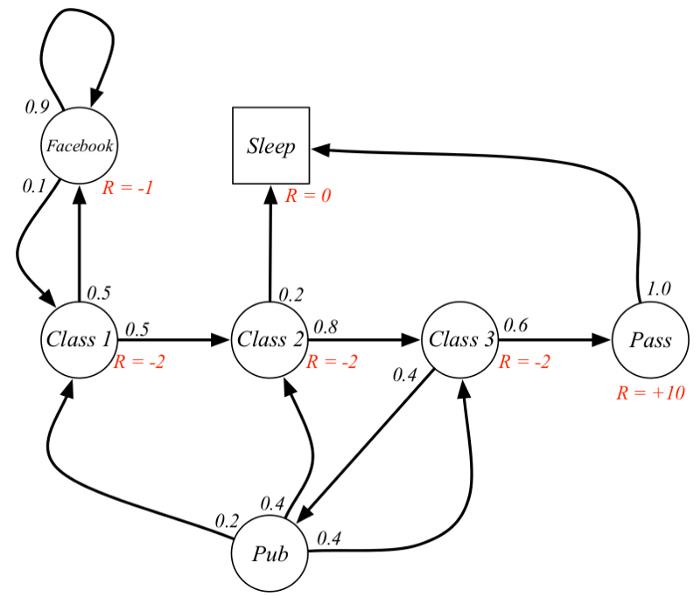
假设当前状态是class 2,于是根据策略,其中一个agent选择了一个决策序列为 class 2→class 3→pass→sleep,假设discount=0.5那么我们的reward为:
− 2 + ( − 2 ∗ 0.5 ) + 10 ∗ 0. 5 2 + 0 = − 0.5 -2+(-2*0.5)+10*0.5^2 +0=-0.5 −2+(−2∗0.5)+10∗0.52+0=−0.5
然而这只是其中的一个样本,有没有什么方法可以直接得出这个期望的解析解呢?这时候我们就要介绍bellman equation, 我们可以改写公式1为一个迭代的形式:
V π ( s ) ≐ E π [ R t + 1 + γ V π ( S t + 1 ) ∣ S t = s ] V^\\pi (s)\\doteq E_\\pi [R_t+1 +\\gamma V^\\pi (S_t+1 )|S_t =s] Vπ(s)≐Eπ[Rt+1+γVπ(St+1)∣St=s]
即当前的reward加上,下一个state下的累积reward,通过这样的分解,我们有:
V π ( s ) = E π [ R t + 1 ∣ S t = s ] + γ ∑ s ′ ∈ S p ( s ′ ∣ s ) V π ( s ′ ) V^\\pi (s)=E_\\pi [R_t+1 |S_t =s]+\\gamma \\sum _s'\\in S p(s'|s)V^\\pi (s') Vπ(s)=Eπ[Rt+1∣St=s]+γs′∈S∑p(s′∣s)Vπ(s′)
考虑不同的状态 s 1 , . . . , s n \\displaystyle s_1 ,...,s_n s1,...,sn我们可以写成矩阵的形式:
( V π ( s 1 ) V π ( s 2 ) ⋮ V π ( s n ) ) ⏟ v = ( E π [ R t + 1 ∣ S t = s 1 ] E π [ R t + 1 ∣ S t = s 2 ] ⋮ E π [ R t + 1 ∣ S t = s n ] ) ⏟ R + γ ( p ( s 1 ∣ s 1 ) p ( s 2 ∣ s 1 ) p ( s n ∣ s 1 ) p ( s 1 ∣ s 2 ) p ( s 1 ∣ s 2 ) p ( s 1 ∣ s 2 ) p ( s 1 ∣ s n ) p ( s 1 ∣ s n ) p ( s 1 ∣ s n ) ) ⏟ P ( V π ( s 1 ) V π ( s 2 ) ⋮ V π ( s n ) ) ⏟ v \\underbrace\\beginpmatrix V^\\pi (s_1 )\\\\ V^\\pi (s_2 )\\\\ \\vdots \\\\ V^\\pi (s_n ) \\endpmatrix_v =\\underbrace\\beginpmatrix E_\\pi [R_t+1 |S_t =s_1 ]\\\\ E_\\pi [R_t+1 |S_t =s_2 ]\\\\ \\vdots \\\\ E_\\pi [R_t+1 |S_t =s_n ] \\endpmatrix_R +\\gamma \\underbrace\\beginpmatrix p(s_1 |s_1 ) & p(s_2 |s_1 ) & & p(s_n |s_1 )\\\\ p(s_1 |s_2 ) & p(s_1 |s_2 ) & & p(s_1 |s_2 )\\\\ & & & \\\\ p(s_1 |s_n ) & p(s_1 |s_n ) & & p(s_1 |s_n ) \\endpmatrix_P\\underbrace\\beginpmatrix V^\\pi (s_1 )\\\\ V^\\pi (s_2 )\\\\ \\vdots \\\\ V^\\pi (s_n ) \\endpmatrix_v v ⎝⎜⎜⎜⎛Vπ(s1)Vπ(s2以上是关于强化学习入门的主要内容,如果未能解决你的问题,请参考以下文章