强化学习——入门
Posted xxxxxxxxx
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了强化学习——入门相关的知识,希望对你有一定的参考价值。
强化学习:
强化学习作为一门灵感来源于心理学中的行为主义理论的学科,其内容涉及 概率论、统计学、逼近论、凸分析、计算复杂性理论、运筹学 等多学科知识,难度之大,门槛之高,导致其发展速度特别缓慢。
一种解释:
人的一生其实都是不断在强化学习,当你有个动作(action)在某个状态(state)执行,然后你得到反馈(reward),尝试各种状态下各种动作无数次后,这几点构成脑中的马尔可夫模型,使你知道之后的行为什么为最优。
另一种解释:
强化学习最重要的几个概念:agent,environment,reward,policy,action。environment 通常利用马尔可夫过程来描述,agent 通过采取某种 policy 来产生action,和 environment 交互,产生一个 reward。之后 agent 根据 reward 来调整优化当前的 policy。
强化学习和有监督学习的区别
有监督学习的训练样本是有标签的,而强化学习没有标签,它是通过环境给的奖惩来进行学习;我们会发现,强化学习和监督学习以及无监督学习最大的不同就是不需要大量的数据来“喂养”,而是通过自己不停的尝试来学会某些技能;
有监督学习的学习过程是静态的,而强化学习的学习过程是动态的;这里的动态和静态指的是:是否和环境进行交互;有监督学习中给什么样本就学什么,而强化学习要与环境进行交互,再根据交互所给出的奖惩来学习;
有监督学习解决的更多是感知问题,比如深度学习,而强化学习解决的主要是决策问题;因此有监督学习像是五官,而强化学习更像是大脑;举个栗子:面对一只老虎的时候,如果只有监督学习就会反映出老虎两个字,如果有了强化学习,我们就可以决定是逃跑还是战斗。
只要问题中包含了决策和控制,就可以使用强化学习!
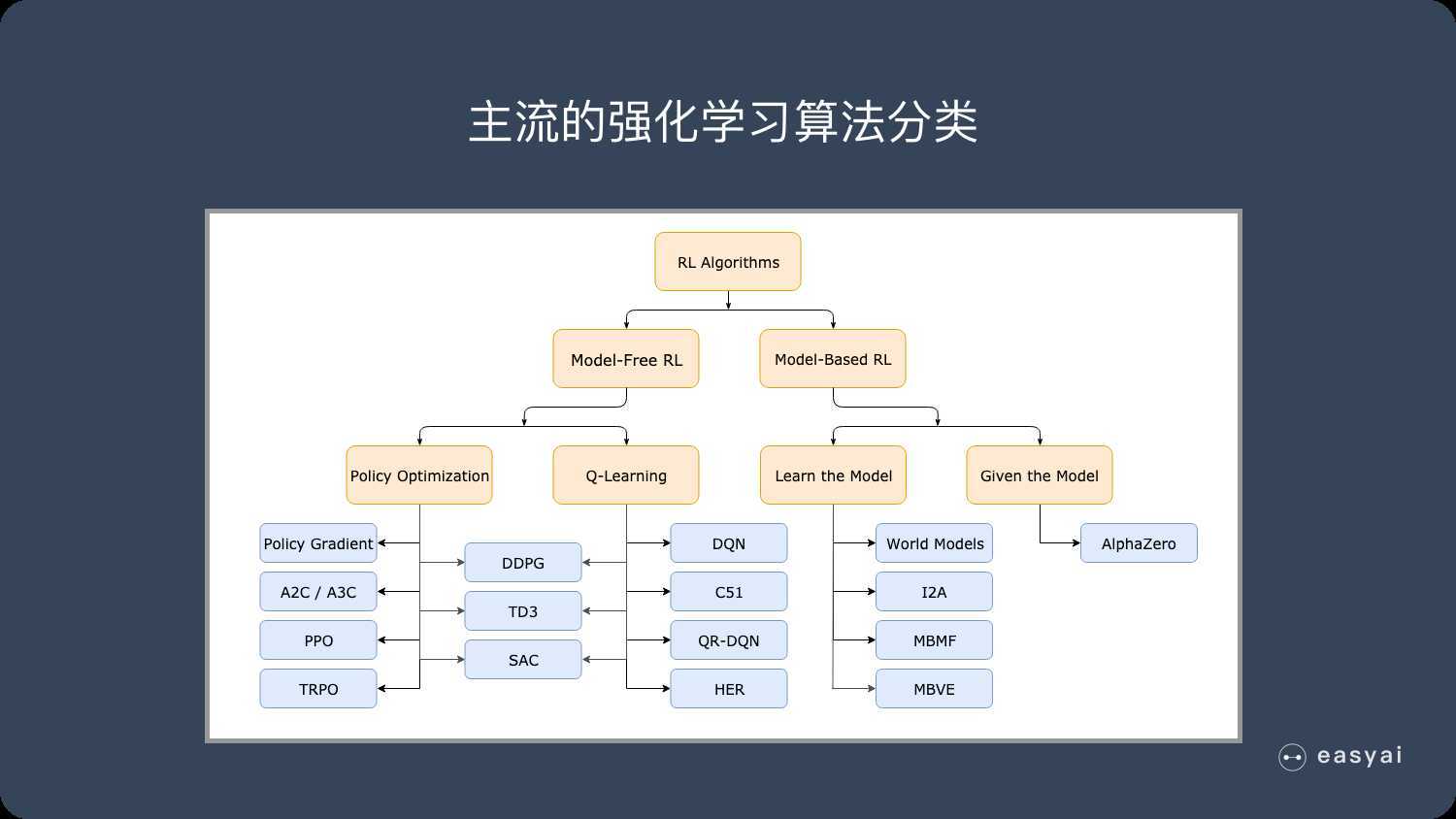
强化学习的主流算法
免模型学习(Model-Free) VS 有模型学习(Model-Base)
主要差异:智能体是否能完整了解或学习到所在环境的模型
有模型学习:优点是对环境有提前认知,可以提前考虑和规划;缺点是如果模型和真实世界不一致,那么在实际使用场景下不会有太好的表现;
免模型学习:缺点是放弃了模型学习,使得效率不如前者;优点是这种方式更容易实现,也容易在真实场景下调整到很好的状态。
因此,免模型学习更受欢迎,得到更加广泛的支持和研究。
为什么强化学习会很慢?
增量式的参数更新: 最初的算法,从输入的周围环境,到输出的AI动作之间,是靠梯度下降来完成映射的。在这个过程中,每个增量都需要非常小,才不至于让新学到的信息,把之前学到的经验覆盖了 (这叫做“灾难性干扰”) 。如此一来,学习过程便十分缓慢。
解决方法:情节性深度强化学习 (Episodic DRL)弱归纳偏置: 任何学习过程,都要面临“偏见-方差权衡”。所谓偏见,就是一开始限定好一些可能的结果,AI从里面找出自己想要的那一种。限定越窄,AI就可以只考虑为数不多的可能性,更快地得出结果。弱归纳偏置,就需要考虑更多的可能性,学习也就慢一些。
解决方法:首先限定好一个狭窄的范围,再让AI去探索。可怎么知道应该限定在哪里?答案是,借鉴过去的经验。Note:具体讲解参考引用中量子位的回答
强化学习与深度学习的结合(DRL,Deep Reinforcement Learning)
强化学习从根本上打破了以前利用处理数据、选取算法模型、训练与测试来解决问题的这种思维,而是从 策略、值函数、模型等角度 进行解决问题。为了能够利用数学进行通用表达,以序列决策问题为典型的马尔科夫决策过程被广泛的使用。此外,动态规划、蒙特卡罗、时序控制三种方法作为探索马尔科夫序列最佳策略的重要方法而被广泛使用,并从控制的角度教智能体如何在有限的状态下进行探索和利用。
在以上的基础上,策略梯度及神经网络被广泛的应用于策略和值函数的逼近过程中。使用神经网络逼近一定程度上避免了表格存储序列空间大,查询慢等令人窒息的诟病,成为了强化学习发展的新的方向。
通常情况下,人类的学习是在真实环境下,但强化学习目前还不能普及到高复杂、具有逻辑推理与情感分析的阶段,所以拥有一个仿真环境是强化学习学习的重要基础,这也是DRL区别于其他AI算法的独特点。可以说强化学习的成功来自于其在游戏领域的成功,因为游戏只涉及策略的决策,而不需要复杂的逻辑推理 (围棋计算落子概率) 以及情感分析。
- 深度学习的学习基础是:数据,算法模型,计算力;
- 深度强化学习的学习基础是:仿真模拟环境,算法模型和计算力
在强化学习原理与基础、强化学习的仿真模拟环境以及深度强化学习算法基础上,真正的深度强化学习算法是什么样的?它是如何训练地?如何确定模型以及如何调整超参数等一系列的问题接踵而来。 DQN (Deep Q Network) 是里程碑式的一个 DRL 算法。
References:
? [1] 强化学习的主流算法
? [2] 强化学习是什么? - 量子位的回答 - 知乎
? [3] 强化学习是什么? - 海晨威的回答 - 知乎
以上是关于强化学习——入门的主要内容,如果未能解决你的问题,请参考以下文章