《概率统计》多元随机变量
Posted traditional
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《概率统计》多元随机变量相关的知识,希望对你有一定的参考价值。
楔子
前两篇我们讨论的离散型和连续型随机变量都是单一变量,然而在现实当中,一个试验常常会涉及到多个随机变量。所谓多个随机变量是指在同一个试验结果之下产生的多个随机变量。这些随机变量的取值是由试验结果确定的,因此它们的取值会存在相互关联。这里我们先以离散型随机变量为例,将离散型随机变量的分布列和期望推广到多个随机变量的情况,并且进一步在此基础上讨论多元随机变量条件和独立的重要概念。
好了,此刻我们假设试验中不再只有一个随机变量,而是两个随机变量 X 和 Y,同时描述他们俩的取值概率,我们用什么方式?
联合分布列
基于之前讲过的离散型随机变量分布列的概念,这里为多元随机变量引入联合分布列,用 PX,Y 对其进行表示。设 (x,y) 是随机变量 X 和 Y 的一组可能取值。因此对应的 (x,y) 的概率质量就定义为事件 {X=x,Y=y} 的概率:
PX,Y?= P({X = x, Y = y}),也就是同时满足事件{X = x}和{Y = y}的概率。那么首先,来实际看一个联合分布列的表示。很明显,我们可以用一个二维表格来表示随机变量 X 和 Y 的联合分布列:
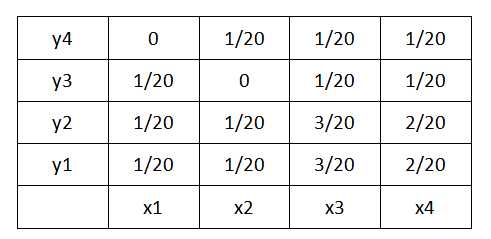
从这张表出发,就可以把联合分布列中所有的知识点都梳理一遍:
第一,可以从图中获得随机变量 X 和 Y 的任意一组取值的联合概率,例如:PX,Y(x3,y2) = P(X=x3,Y=y2)=3/20
第二,对于由随机变量 X 和 Y 构成的任意事件集合也是一样的,例如定义事件集合 A={(x1,y2),(x3,y2),(x4,y4)},那么很显然,我们直接就能从联合分布列中计算出事件集合的总概率:P((X,Y)∈A)=∑(x,y)∈APX,Y(x,y) = 1/20+3/20+1/20=5/20
第三,也是最朴实的一点,我们把二维表中所有的联合概率进行相加,得到的结果必然是 1,这也满足概率的归一性。
边缘分布列
如果我们把事件集合再设置的讲究一些,例如把事件集合 A 设置为表中的第一列,即 A={(x1,y1),(x1,y2),(x1,y3)},此时我们计算出来的事件集合 A 的总概率也就是概率 P(X=x1),对于这个概率,我们把它称为边缘概率:
P(X=x1) = 1/20 + 1/20 + 1/20 + 0 = 3/20
当然,更进一步,如果我们把随机变量 X 所有取值的边缘概率都计算出来,就能得到随机变量 X 的边缘分布列:
PX(x) = P(X=x) = ∑yP(X=x,Y=y) = ∑yPX,Y(x,y)
简单点,我们先求随机变量 X 每一个取值的边缘概率,就是把对应列的联合概率全部相加,然后再把 X=xi 的所有边缘概率放在一起,就是随机变量 X 的边缘分布列。
当然,随机变量 Y 的边缘分布也是类似的,这里我们就不再赘述了。
边缘概率和边缘分布列的 “边缘” 是什么含义?一句话描述就是,随机变量 X 的边缘分布列及其任意一个边缘概率的取值,都是只与自己有关,而与其他的随机变量(这里是随机变量 Y)无关了。
而对应的联合分布列和联合概率中的联合二字,意思也很明显,这里面的取值需由所有的随机变量,即由随机变量 X 和 Y 共同决定。
条件分布列
在前面我们学习了,条件可以给某些事件提供补充信息,由于随机变量的取值也是一种事件。同样的,条件也可以对随机变量取某些值提供补充信息。因此我们是不是能引入随机变量的条件分布列呢?当然是可以的。
条件可以指某个事件的发生,当然也可以包含其他随机变量的取值。还是来看一张图:
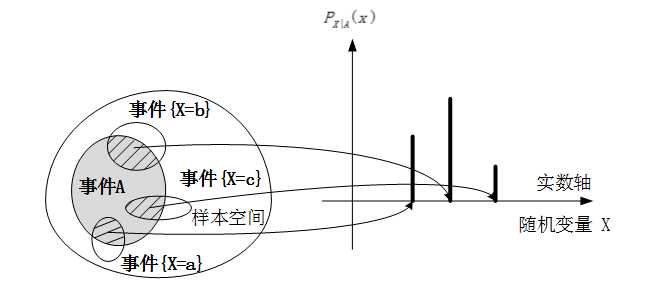
可以发现,在某个事件 A 发生的情况下,随机变量 X 发生的条件分布列很容易给出,还记得条件概率的表达式么,把它拿过来直接套用过来就可以了。
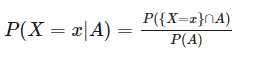
P(X = x|A)表示在事件A发生的前提下,X=x的概率,也可以写成PX|A(x),感觉是不是很熟悉?但是有些关键点我还是要再提一下,首先对于随机变量 X 不同的取值 x1,x2,x3,...,xn,{X=x}∩A 彼此之间互不相容,并且他们的并集是整个事件 A。
以上是关于《概率统计》多元随机变量的主要内容,如果未能解决你的问题,请参考以下文章