概率论与数理统计小结3 - 一维离散型随机变量及其Python实现
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了概率论与数理统计小结3 - 一维离散型随机变量及其Python实现相关的知识,希望对你有一定的参考价值。
注:上一小节对随机变量做了一个概述,这一节主要记录一维离散型随机变量以及关于它们的一些性质。对于概率论与数理统计方面的计算及可视化,主要的Python包有scipy, numpy和matplotlib等。
以下所有Python代码示例,均默认已经导入上面的这几个包,导入代码如下:
import numpy as np from scipy import stats import matplotlib.pyplot as plt
0. Python中调用一个分布函数的步骤
scipy是Python中使用最为广泛的科学计算工具包,再加上numpy和matplotlib,基本上可以处理大部分的计算和作图任务。下面是wiki对scipy的介绍:
SciPy是一个开源的Python算法库和数学工具包。SciPy包含的模块有最优化、线性代数、积分、插值、特殊函数、快速傅里叶变换、信号处理和图像处理、常微分方程求解和其他科学与工程中常用的计算。与其功能相类似的软件还有MATLAB、GNU Octave和Scilab。SciPy目前在BSD许可证下发布。它的开发由Enthought资助。
上面的介绍中没有提到stats模块,这个模块中包含了概率论及统计相关的函数。
参考相关主页:https://docs.scipy.org/doc/scipy/reference/stats.html
下面是调用一个分布函数的常用方法(以最常见的正态分布为例):
- 初始化一个分布函数(也叫作冻结的分布);
- 调用该分布函数的方法或计算其数值特征;
1 import numpy as np 2 from scipy import stats 3 import matplotlib.pyplot as plt 4 5 6 norm_dis = stats.norm(5, 3) # 利用相应的分布函数及参数,创建一个冻结的正态分布(frozen distribution) 7 x = np.linspace(-5, 15, 101) # 在区间[-5, 15]上均匀的取101个点 8 9 10 # 计算该分布在x中个点的概率密度分布函数值(PDF) 11 pdf = norm_dis.pdf(x) 12 13 # 计算该分布在x中个点的累计分布函数值(CDF) 14 cdf = norm_dis.cdf(x) 15 16 # 下面是利用matplotlib画图 17 plt.figure(1) 18 # plot pdf 19 plt.subplot(211) # 两行一列,第一个子图 20 plt.plot(x, pdf, ‘b-‘, label=‘pdf‘) 21 plt.ylabel(‘Probability‘) 22 plt.title(r‘PDF/CDF of normal distribution‘) 23 plt.text(-5.0, .12, r‘$\\mu=5,\\ \\sigma=3$‘) # 3是标准差,不是方差 24 plt.legend(loc=‘best‘, frameon=False) 25 # plot cdf 26 plt.subplot(212) 27 plt.plot(x, cdf, ‘r-‘, label=‘cdf‘) 28 plt.ylabel(‘Probability‘) 29 plt.legend(loc=‘best‘, frameon=False) 30 31 plt.show()
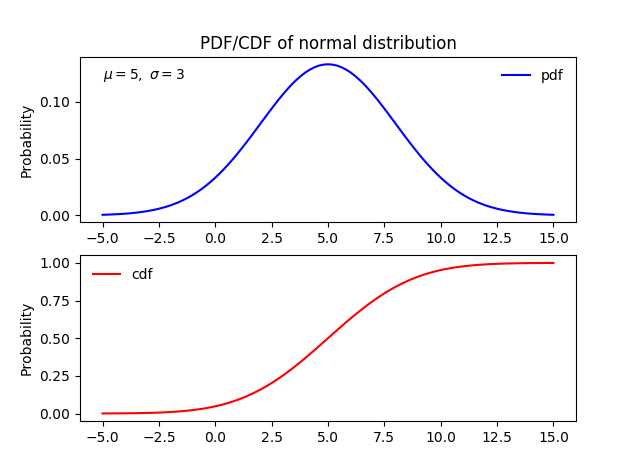
图0-1:正态分布$N(5, 3^2)$的概率密度函数和累计分布函数
1. 伯努利分布
伯努利分布应该是所有分布里面最简单的分布,也是二项分布的基本单元。其样本空间中只有两个点,一般取为$ \\{0, 1\\} $。不同的伯努利分布只是取到这两个值的概率不同。
1.1 定义
伯努利分布(英语:Bernoulli distribution,又名两点分布或者0-1分布,是一个离散型概率分布,为纪念瑞士科学家雅各布·伯努利而命名。)若伯努利试验成功,则伯努利随机变量取值为1。若伯努利试验失败,则伯努利随机变量取值为0。记其成功概率为$ p (0{\\le}p{\\le}1) $,失败概率为$ q=1-p $。则其概率质量函数(PMF)为:
\\begin{equation}
\\nonumber P_X(x) = \\left\\{
\\begin{array}{l l}
p& \\quad \\text{for } x=1\\\\
1-p & \\quad \\text{ for } x=0\\\\
0 & \\quad \\text{ otherwise }
\\end{array} \\right.
\\end{equation}
where $0 < p < 1$.
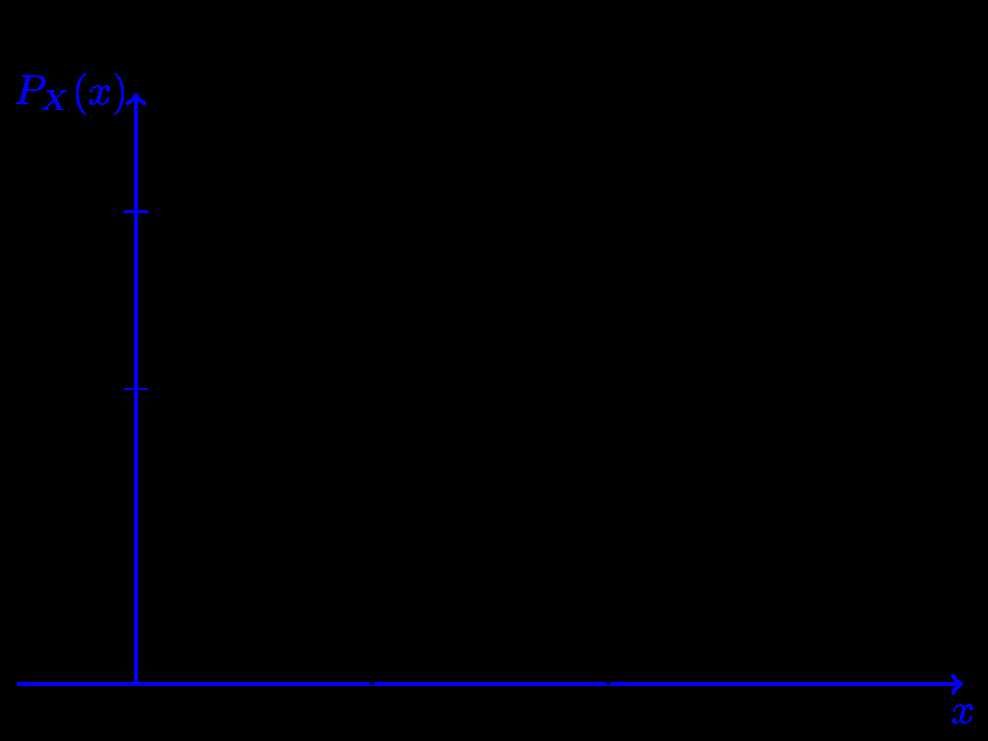
图1-1:参数为p的伯努利分布的概率质量函数
伯努利分布只有一个参数p,记做$X \\sim Bernoulli(p)$,或$X \\sim B(1, p)$,读作X服从参数为p的伯努利分布。
1.2 主要用途
每种分布都是一种模型,都有其适用的实例。伯努利分布适合于试验结果只有两种可能的单次试验。例如抛一次硬币,其结果只有正面或反面两种可能;一次产品质量检测,其结果只有合格或不合格两种可能。
1.3 Python的实现
- 使用柱状图表示伯努利分布的概率质量分布函数
1 def bernoulli_pmf(p=0.0): 2 """ 3 伯努利分布,只有一个参数 4 https://docs.scipy.org/doc/scipy/reference/generated/scipy.stats.bernoulli.html#scipy.stats.bernoulli 5 :param p: 试验成功的概率,或结果为1的概率 6 :return: 7 """ 8 ber_dist = stats.bernoulli(p) 9 x = [0, 1] 10 x_name = [‘0‘, ‘1‘] 11 pmf = [ber_dist.pmf(x[0]), ber_dist.pmf(x[1])] 12 plt.bar(x, pmf, width=0.15) 13 plt.xticks(x, x_name) 14 plt.ylabel(‘Probability‘) 15 plt.title(‘PMF of bernoulli distribution‘) 16 plt.show() 17 18 bernoulli_pmf(p=0.3)
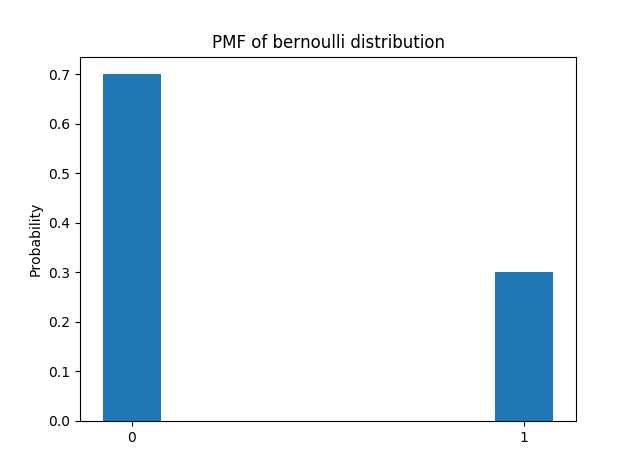
图1-2:柱状图表示的伯努利分布$B(1, 0.3)$的PMF
2. 二项分布
如果把一个伯努利分布独立的重复n次,就得到了一个二项分布。二项分布是最重要的离散型概率分布之一。随机变量$X$要满足这个分布有两个重要条件:
- 各次试验的条件是稳定的;
- 各次试验之间是相互独立的。
2.1 定义
二项分布有两个参数——试验次数$n$和每次试验成功的概率$p$. 其概率质量函数为:
\\begin{equation}
\\nonumber P_X(k) = \\left\\{
\\begin{array}{l l}
{n \\choose k}p^k(1-p)^{n-k}& \\quad \\text{for } k=0,1,2,\\cdots,n\\\\
0 & \\quad \\text{otherwise}
\\end{array} \\right.
\\end{equation}
where $0 < p < 1$.
一个随机变量$X$服从参数为$n$和$p$的二项分布,记做$X \\sim Binomial(n,p)$,或$X \\sim B(n, p)$
2.2 主要用途
现实生活中有许多现象程度不同地符合这些条件,例如经常用来举例子的抛硬币,掷骰子等。如果每次试验条件都相同,那么硬币正面朝上的次数以及某一个点数出现的次数都是非常典型的符合二项分布的随机变量。均匀硬币抛1000次,则正面朝上的次数$X \\sim Binomial(1000, 0.5)$;有六个面的骰子,掷100次,则6点出现的次数$X \\sim Binomial(100, \\frac{ 1 }{ 6 })$
2.3 Python的实现
下面的代码用来模拟抛一枚不均匀的硬币20次,其中正面朝上的概率为0.6
1 def binom_dis(n=1, p=0.1): 2 """ 3 二项分布,模拟抛硬币试验 4 :param n: 实验总次数 5 :param p: 单次实验成功的概率 6 :return: 试验成功的次数 7 """ 8 binom_dis = stats.binom(n, p) 9 simulation_result = binom_dis.rvs(size=5) # 取5个符合该分布的随机变量 10 print(simulation_result) # [ 7 11 13 8 13], 每次结果会不一样 11 prob_10 = binom_dis.pmf(10) 12 print(prob_10) # 0.117 13 14 binom_dis(n=20, p=0.6)
上面定义了一个$n=20, p=0.6$的二项分布,意思是说每次试验抛硬币(该硬币正面朝上的概率大于背面朝上的概率)20次并记录正面朝上的次数。
第9行"size=5"表示这样的试验重复了5次;第10行是试验结果(第一次试验,正面朝上出现了7次;第二次试验,正面朝上出现了11次...);第11行表示计算正面朝上的次数为10的概率,由于每次试验抛硬币20次,因此试验结果从0到20都有可能,只是概率不同而已。下面是该分布的概率质量分布函数图:
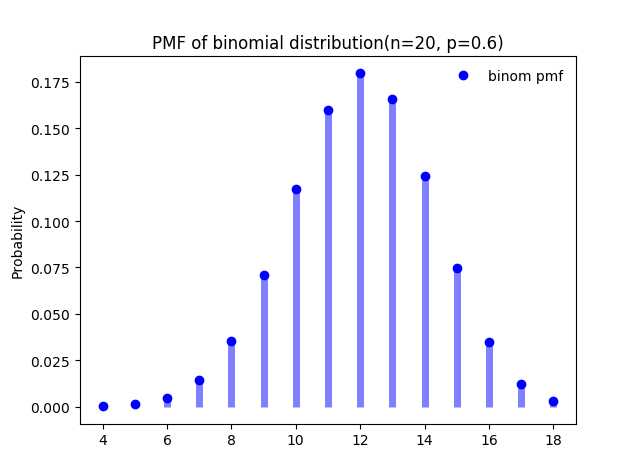
图2-1, 二项分布$B(20, 0.6)$的PMF
从图2-1中可以明显看到该分布的概率质量分布函数图明显向右边偏移,在$x=12$处取到最大概率。这是因为这个硬币正面朝上的概率大于反面朝上的概率。
上面PMF分布图的代码实现:
1 def binom_pmf(n=1, p=0.1): 2 """ 3 二项分布有两个参数 4 https://docs.scipy.org/doc/scipy/reference/generated/scipy.stats.binom.html#scipy.stats.binom 5 :param n:试验次数 6 :param p:单次实验成功的概率 7 :return: 8 """ 9 binom_dis = stats.binom(n, p) 10 x = np.arange(binom_dis.ppf(0.0001), binom_dis.ppf(0.9999)) 11 print(x) # [ 0. 1. 2. 3. 4.] 12 fig, ax = plt.subplots(1, 1) 13 ax.plot(x, binom_dis.pmf(x), ‘bo‘, label=‘binom pmf‘) 14 ax.vlines(x, 0, binom_dis.pmf(x), colors=‘b‘, lw=5, alpha=0.5) 15 ax.legend(loc=‘best‘, frameon=False) 16 plt.ylabel(‘Probability‘) 17 plt.title(‘PMF of binomial distribution(n={}, p={})‘.format(n, p)) 18 plt.show() 19 20 binom_pmf(n=20, p=0.6)
3. 泊松分布
日常生活中,大量事件的发生是有固定频率的。例如某医院平均每小时出生3个婴儿,某网站平均每分钟有2次访问等。它们的特点就是,我们可以预估这些事件在某个时间段内发生的总次数,但是没法知道具体的发生时间。已知平均每小时出生3个婴儿,请问下一个小时,会出生几个?
有可能一下子出生6个,也有可能一个都不出生。这是我们没法知道的。
如果某事件以固定强度$\\lambda$,随机且独立地出现,该事件在单位时间内出现的次数(个数)可能看出是服从泊松分布。
3.1 定义
泊松分布有一个参数$\\lambda$(有的地方表示为$\\mu$),表示单位时间(或单位面积)内随机事件的平均发生次数,其PMF表示为:
\\begin{equation}
\\nonumber P_X(k) = \\left\\{
\\begin{array}{l l}
\\frac{e^{-\\lambda} \\lambda^k}{k!}& \\quad \\text{for } k \\in R_X\\\\
0 & \\quad \\text{ otherwise}
\\end{array} \\right.
\\end{equation}
一个随机变量$X$服从参数为$\\lambda$的泊松分布,记做$X \\sim Poisson(\\lambda)$,或$X \\sim P(\\lambda)$
3.2 主要用途
泊松分布适合于描述单位时间内随机事件发生的次数的概率分布。如某一服务设施在一定时间内受到的服务请求的次数,电话交换机接到呼叫的次数、汽车站台的候客人数、机器出现的故障数、自然灾害发生的次数、DNA序列的变异数、放射性原子核的衰变数、激光的光子数分布等等。
下面是参数$\\mu = 8$时的泊松分布的概率质量分布图(在scipy中将泊松分布的参数表示为$\\mu$):
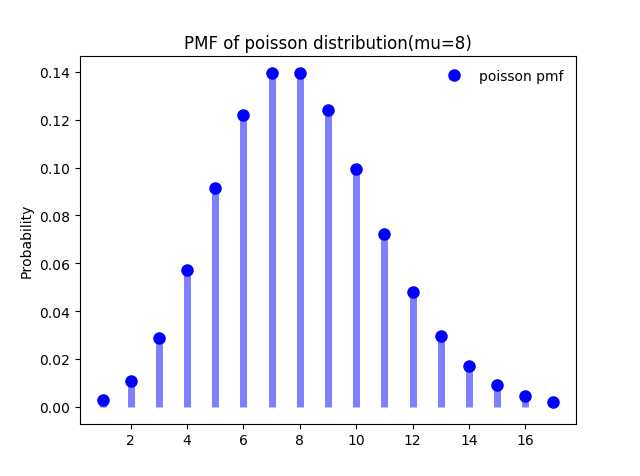
图3-1:,泊松分布$P(8)$的PMF
代码与上面相同,折叠了:


1 def poisson_pmf(mu=3): 2 """ 3 泊松分布 4 https://docs.scipy.org/doc/scipy/reference/generated/scipy.stats.poisson.html#scipy.stats.poisson 5 :param mu: 单位时间(或单位面积)内随机事件的平均发生率 6 :return: 7 """ 8 poisson_dis = stats.poisson(mu) 9 x = np.arange(poisson_dis.ppf(0.001), poisson_dis.ppf(0.999)) 10 print(x) 11 fig, ax = plt.subplots(1, 1) 12 ax.plot(x, poisson_dis.pmf(x), ‘bo‘, ms=8, label=‘poisson pmf‘) 13 ax.vlines(x, 0, poisson_dis.pmf(x), colors=‘b‘, lw=5, alpha=0.5) 14 ax.legend(loc=‘best‘, frameon=False) 15 plt.ylabel(‘Probability‘) 16 plt.title(‘PMF of poisson distribution(mu={})‘.format(mu)) 17 plt.show() 18 19 poisson_pmf(mu=8)
4. 泊松分布与二项分布的关系
如果仅仅是看二项分布与泊松分布的概率质量分布图,也可以发现它们的相似度非常高。事实上这两个分布内在联系十分紧密。泊松分布可以作为二项分布的极限得到。一般来说,若$X \\sim B(n, p)$,其中$n$很大,$p$很小,而$np = \\lambda$不太大时,则X的分布接近于泊松分布$P(\\lambda)$.
从下图中可以非常直观的看到两者的关系:
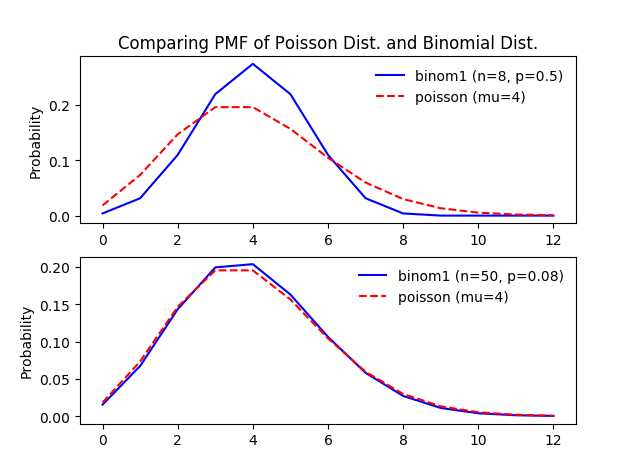
图4-1:同一个泊松分布与参数不同的二项分布的比较
图4-1中,上面的图中二项分布的参数$n$比较小,$p$比较大,与参数为$\\mu = np$的泊松分布差异很大;下面的图中二项分布的参数$n$比较大,两者的PMF图已经非常相似了。
从去取值范围上来说:
- 二项分布的取值范围内为$[0, n]$;
- 泊松分布的取值范围为$[0, +\\infty]$;
当二项分布的参数$n \\to +\\infty$时,在$np$不变的情况下,单位长度上发生的概率降低了。
上面的图实现的代码如下:
1 def compare_binom_poisson(mu=4, n1=8, n2=50): 2 """ 3 二项分布与泊松分布的比较 4 :param mu: 泊松分布的参数,保持mu不变 5 :param n1: 第一个二项分布中的实验次数,n比较小 6 :param n2: 第二个二项分布中的实验次数,n比较大 7 :return: 8 """ 9 # 为了具有可比性, 利用mu = n * p, 计算p 10 p1 = mu/n1 # 二项分布中的参数,单次实验成功的概率 11 p2 = mu/n2 12 poisson_dist = stats.poisson(mu) # 初始化泊松分布 13 binom_dist1 = stats.binom(n1, p1) # 初始化第一个二项分布 14 binom_dist2 = stats.binom(n2, p2) # 初始化第二个二项分布 15 16 # 计算pmf 17 X = np.arange(poisson_dist.ppf(0.0001), poisson_dist.ppf(0.9999)) 18 y_po = poisson_dist.pmf(X) 19 print(X) 20 print(y_po) 21 y_bi1 = binom_dist1.pmf(X) 22 y_bi2 = binom_dist2.pmf(X) 23 24 # 作图 25 # First group 26 # 当n比较小,p比较大时,两者差别比较大 27 plt.figure(1) 28 plt.subplot(211) 29 plt.plot(X, y_bi1, ‘b-‘, label=‘binom1 (n={}, p={})‘.format(n1, p1)) 30 plt.plot(X, y_po, ‘r--‘, label=‘poisson (mu={})‘.format(mu)) 31 plt.ylabel(‘Probability‘) 32 plt.title(‘Comparing PMF of Poisson Dist. and Binomial Dist.‘) 33 plt.legend(loc=‘best‘, frameon=False) 34 35 # second group 36 # 当n比较大,p比较小时,两者非常相似 37 plt.subplot(212) 38 plt.plot(X, y_bi2, ‘b-‘, label=‘binom1 (n={}, p={})‘.format(n2, p2)) 39 plt.plot(X, y_po, ‘r--‘, label=‘poisson (mu={})‘.format(mu)) 40 plt.ylabel(‘Probability‘) 41 plt.legend(loc=‘best‘, frameon=False) 42 plt.show()
5. 自定义分布函数以及经验分布函数
从本质上讲,只要满足"概率密度(质量)函数的性质"的函数都可以作为分布函数,对于离散型随机变量就是:
- 所有可能取值被取到的概率不小于0;
- 所有以上概率的和等于1。
根据上面的条件,我们完全可以自定义无数个不同与上述三类分布的离散型随机变量。
5.1 自己定义分布函数
下面定义了一个取值范围为$\\{0, 1, 2, 3, 4, 5, 6\\}$的离散型分布以及该分布的PMF图:
1 def custom_made_discrete_dis_pmf(): 2 """ 3 https://docs.scipy.org/doc/scipy/reference/generated/scipy.stats.rv_discrete.html 4 :return: 5 """ 6 xk = np.arange(7) # 所有可能的取值 7 print(xk) # [0 1 2 3 4 5 6] 8 pk = (0.1, 0.2, 0.3, 0.1, 0.1, 0.0, 0.2) # 各个取值的概率 9 custm = stats.rv_discrete(name=‘custm‘, values=(xk, pk)) 10 11 fig, ax = plt.subplots(1, 1) 12 ax.plot(xk, custm.pmf(xk), ‘ro‘, ms=8, mec=‘r‘) 13 ax.vlines(xk, 0, custm.pmf(xk), colors=‘r‘, linestyles=‘-‘, lw=2) 14 plt.title(‘Custom made discrete distribution(PMF)‘) 15 plt.ylabel(‘Probability‘) 16 plt.show() 17 18 custom_made_discrete_dis_pmf()
下面是该分布的PMF图:
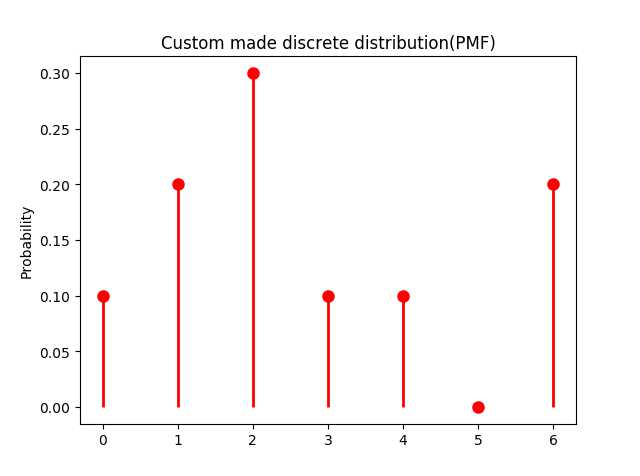
图5-1:自定义的离散型随机变量的概率质量分布图
5.2 经验分布函数
该分布的取值就是0-6这7个数字,但是取到这几个数字的概率是不同的,其中取到2的概率最大(p(2) = 0.3),而取到5的概率为0(也就是说几乎不可能取到5)。我们利用上面的概率分布,取20个数(即从该分布中进行抽样,没抽一次样就相当于做了一次试验),结果如下:
[2 2 4 0 2 2 2 1 6 1 3 0 2 2 1 2 2 6 6 6]
观察上面的结果可以发现:
- p(0) = 2/20 = 0.1;
- p(1) = 3/20 = 0.15;
- p(2) = 9/20 = 0.45;
- p(3) = 1/20 = 0.05;
- p(4) = 1/20 = 0.05;
- p(5) = 0/20 = 0;
- p(6) = 4/20 = 0.2.
上面各个数取到的概率是通过具体的试验结果计算出来的,同时也符合"概率质量函数的性质",因此叫做经验分布函数。从计算结果来看,经验分布函数各个结果取到的概率和其抽样的分布函数(自定义的分布函数)给定的概率几乎相同。但由于抽样次数只有20次,因此与原分布中的概率还是有差异。下面对不同抽样次数得到的经验分布与原分布进行一下比较:
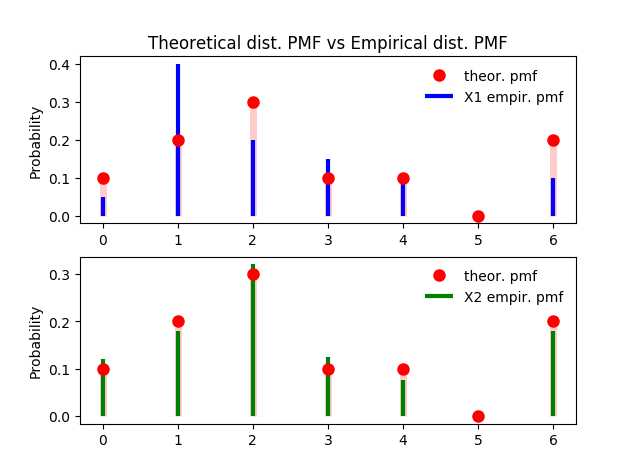
图5-1:不同抽样次数得到的经验分布PMF与理论分布PMF的计较(上面取样20次,下面取样200次,每次得到的结果可能不同)
从上图可以看到,取样较少的情况下,经验分布与理论分布的差异比较大;但当取样较多时,经验分布就与理论分布非常相似了。对于这个现象也很好解释:我们从原分布中取到的样本越多,收集到的样本集也就越能代表原来真实的分布。
下面是实现的代码:
def sampling_and_empirical_dis():
xk = np.arange(7) # 所有可能的取值
print(xk) # [0 1 2 3 4 5 6]
pk = (0.1, 0.2, 0.3, 0.1, 0.1, 0.0, 0.2) # 各个取值的概率
custm = stats.rv_discrete(name=‘custm‘, values=(xk, pk))
X1 = custm.rvs(size=20) # 第一次抽样
X2 = custm.rvs(size=200) # 第二次抽样
# 计算X1&X2中各个结果出现的频率(相当于PMF)
val1, cnt1 = np.unique(X1, return_counts=True)
val2, cnt2 = np.unique(X2, return_counts=True)
pmf_X1 = cnt1 / len(X1)
pmf_X2 = cnt2 / len(X2)
plt.figure(1)
plt.subplot(211)
plt.plot(xk, custm.pmf(xk), ‘ro‘, ms=8, mec=‘r‘, label=‘theor. pmf‘)
plt.vlines(xk, 0, custm.pmf(xk), colors=‘r‘, lw=5, alpha=0.2)
plt.vlines(val1, 0, pmf_X1, colors=‘b‘, linestyles=‘-‘, lw=3, label=‘X1 empir. pmf‘)
plt.legend(loc=‘best‘, frameon=False)
plt.ylabel(‘Probability‘)
plt.title(‘Theoretical dist. PMF vs Empirical dist. PMF‘)
plt.subplot(212)
plt.plot(xk, custm.pmf(xk), ‘ro‘, ms=8, mec=‘r‘, label=‘theor. pmf‘)
plt.vlines(xk, 0, custm.pmf(xk), colors=‘r‘, lw=5, alpha=0.2)
plt.vlines(val2, 0, pmf_X2, colors=‘g‘, linestyles=‘-‘, lw=3, label=‘X2 empir. pmf‘)
plt.legend(loc=‘best‘, frameon=False)
plt.ylabel(‘Probability‘)
plt.show()
sampling_and_empirical_dis()
Reference
《概率论与数量统计》,陈希孺,中国科学技术大学出版社,2009年2月第一版
中国大学MOOC:浙江大学,概率论与数理统计
https://zh.wikipedia.org/zh/%E4%BC%AF%E5%8A%AA%E5%88%A9%E5%88%86%E5%B8%83
https://stackoverflow.com/questions/25273415/how-to-plot-a-pmf-of-a-sample
https://stackoverflow.com/questions/12848837/scipy-cumulative-distribution-function-plotting
https://zh.wikipedia.org/wiki/SciPy
https://docs.scipy.org/doc/scipy/reference/stats.html
https://www.probabilitycourse.com/chapter3/3_1_5_special_discrete_distr.php
http://www.ruanyifeng.com/blog/2015/06/poisson-distribution.html
https://stackoverflow.com/questions/25273415/how-to-plot-a-pmf-of-a-sample
以上是关于概率论与数理统计小结3 - 一维离散型随机变量及其Python实现的主要内容,如果未能解决你的问题,请参考以下文章