决策树应用
Posted xlandll
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了决策树应用相关的知识,希望对你有一定的参考价值。
上一篇讲了ID3决策树原理,现在开始拿一个例子进行实战
一、python机器学习库
scikit-learn。sklearn是一个Python第三方提供的非常强力的机器学习库,它包含了从数据预处理到训练模型的各个方面。在实战使用scikit-learn中可以极大的节省我们编写代码的时间以及减少我们的代码量,使我们有更多的精力去分析数据分布,调整模型和修改超参。sklearn基本包含了所有机器学习的方式,如
- Classification 分类,如SVM
- Regression 回归 ,如LR
- Clustering 非监督分类,如聚类
- Dimensionality reduction 数据降维,如PCA
- Model Selection 模型选择
- Preprocessing 数据预处理
sklearn包含了所有的机器学习算法,例如本文将用到sklearn中的ID3算法。
在python环境中可以通过 from sklearn.XXXX import XXXX的形式导入sklearn包,例如,本例要使用sklean中决策树将以from sklearn import tree的形式在python环境中导入决策树算法。
二、实战演练
1、项目说明
本例数据将用上一篇文章电脑销售数据,运用ID3决策树的算法对数据进行分类,即用python编程,得到最终的决策树,数据如下,我将数据放入excel表格里面,是为了方面python读取数据。
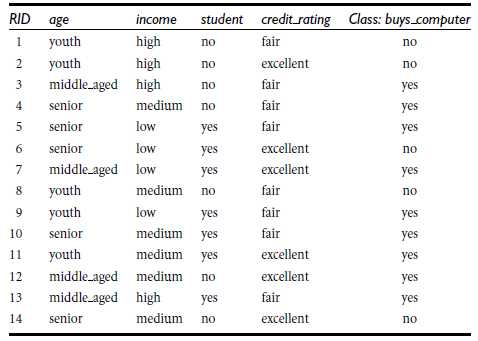
2、数据预处理
这里要说明,sklearn提供的tree类,只接受数值型的数据,不接受文本数据,所以需要对数据进行预处理,在本例中需要对数据转化成虚拟变量(dummy variable)。
(1)虚拟变量(dummy variable)
虚拟变量又称虚设变量、名义变量或哑变量,用以反映质的属性的一个人工变量,是量化了的质变量,通常取值为0或1,一般地,在虚拟变量的设置中:基础类型、肯定类型取值为1;比较类型,否定类型取值为0。这些概念往往让人看不懂,其实说白了就是将数据都变成1或者0,但具体怎么转化?拿本例的age属性来说,age有三个取值{youth,senior,middle_aged}现在将age的取值转化为dummy variable,将youth转化为[1,0,0] ,即1代表youth,后面两个0代表senior和middle_aged,同理,将senior转化为[0,1,0],将middle_aged转化为[0,0,1]。再拿student属性来说,student有两个属性{yes,no},现在将student的取值转化为dummy variable,将yes转化为[1,0],将no转化为[0,1]。按照同样的原理将整个表的数据都转化成dummy variable。
在sklearn中有个DictVectorizer类可以直接将数据转化为dummy variable,但DictVectorizer需要接受字典的形式,所以本次数据预处理的步骤有:
1、将数据转为字典形式,如表中编号1数据,转化为字典形式为:[{‘age‘:‘youth‘},{‘income‘:‘high‘},{‘student‘:‘no‘},{‘credit_rating‘:‘fair‘},{‘buys‘_computer:‘no‘}],同理其他数据也要转化呈这种形式,最后将这些字典放在一个列表当中。
2、将上一步所得的列表传入DictVectorizer中,将数据转化为dummy variable。
(2)代码实现预处理过程
1 import pandas as pd 2 3 data=pd.read_excel(‘./data/决策树1.xls‘) 4 data=pd.DataFrame(data) 5 6 valuedata=data.values#表里面的数据 7 header=list(data.columns)[1:6]#表头 8 9 featureList=[]#这个列表用于存放处理后得到的字典 10 labelList=data[‘Class_buys_computer‘]#存放表中Class_buys_computer属性的数据 11 for value in valuedata: 12 featureDict={} 13 for i in range(4): 14 featureDict[header[i]]=value[i+1] 15 featureList.append(featureDict) 16
以上的代码是将数据变成字典的过程,输出的featureList为:

将得到的featureList传送给sklearn中的DictVectorizer的对象,最后将数据转化为dummy variable。
1 from sklearn.feature_extraction import DictVectorizer 2 from sklearn import preprocessing 3 4 vec=DictVectorizer() 5 dummyX=vec.fit_transform(featureList).toarray() 6 lb=preprocessing.LabelBinarizer() 7 dummyY=lb.fit_transform(labelList)
preprocessing是sklearn中的预处理模块,而preprocessing.LabelBinarizer()是专门将标签变量进行二值化,比如本例,将Class_buys_computer中的取值yes和no转化为1和0
打印dummyX和dummyY的结果为:

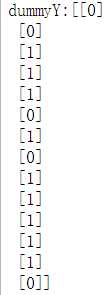
3、建立决策树
from sklearn import tree from sklearn.externals.six import StringIO clf=tree.DecisionTreeClassifier(criterion=‘entropy‘) clf=clf.fit(dummyX,dummyY)
在python环境中通过from sklearn import tree导入决策树模块,调用tree.DecisionTreefier()建立决策树模型,在参数中criterion是选择决策树中的类型,
entropy代表信息熵,所以选择ID3模型。再调用fit()函数对预处理得到的dummyX,和dummyY进行训练。将得到的clf打印出来结果为:

可以看到,我们建立ID3决策树的具体参数配置,具体参数的意义,可以自行查阅。现在需要对最后的模型进行可视化,决策树的可视化需要另外安装Graphviz环境,他的下载地址为
http://www.graphviz.org/,下载安装完后,需要加入环境变量,具体下载安装过程网上有很多。这里不再赘述。
with open("allElectronicsInformationGainOri.dot",‘w‘) as f: f=tree.export_graphviz(clf,feature_names=vec.get_feature_names(),out_file=f)
它会在本目录下生成一个叫,allElecrionInformationGainOri.dot文件,里面的内容为:

这种dot文件都是文字叙述,看起来有点乱,但Graphviz可以将dot文件转化为pdf格式,内容为最后的决策树形状
但需要执行一个命令,就是先打开windows的命令窗口, 转化dot文件至pdf可视化决策树语句:dot -Tpdf iris.dot -o outpu.pdf,再本目录里面会得到一个pdf文件
里面是最终的决策树:
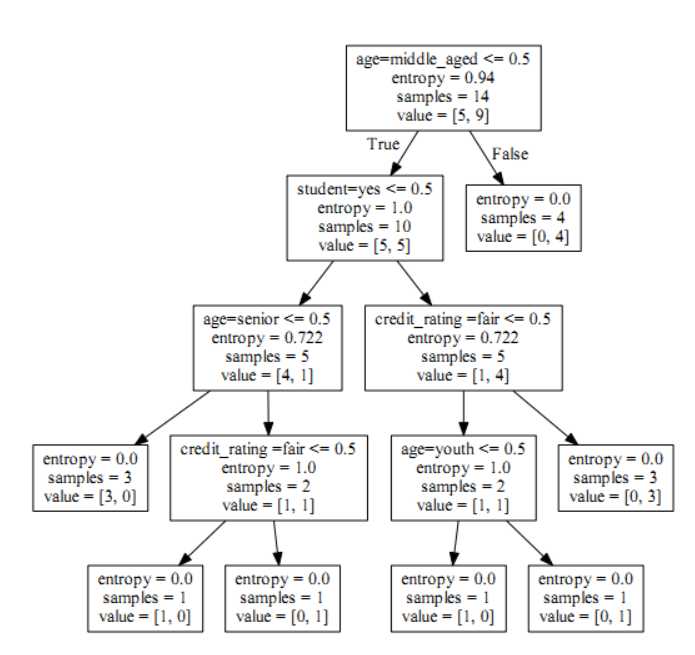
这个决策树跟我们手工算出得出的形状不太一样,这是sklearn将决策树进行了优化,优化的手段有“剪枝”等处理,这将会在后续文章,进行讲解。
至此整个应用到此完毕,请读者手动去实践一下吧。
下一篇文章: 决策树原理(二)
以上是关于决策树应用的主要内容,如果未能解决你的问题,请参考以下文章