HDFS操作实验
Posted ginkgo-
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HDFS操作实验相关的知识,希望对你有一定的参考价值。
HDFS实验
学习了中国MOOC上的《大数据技术原理与应用》,然后找到实验开始学习。我认为这门课被认为是入门的专业课是可以的,很多地方都只是一个简单的描述一下体系结构,工作方式等等,这就足够了,多了也听不懂。学习完了这门课,就是深似海的感觉,对讲的内容总是一知半解,可能自己理论确实不太行趴++
但是,厦门大学(非本校)的这个数据库实验网站还是非常不错的,开源网站吹爆,我也想去林子雨老师那里读研究生了(本科菜鸡一枚),贴出链接,大家一起学习趴
实验部分
1~11题既需要使用shell语言,又需要使用java语言。我在写的过程,可能前面的语法有一些繁琐,毕竟是在学习过程中,希望大家能加强趴++
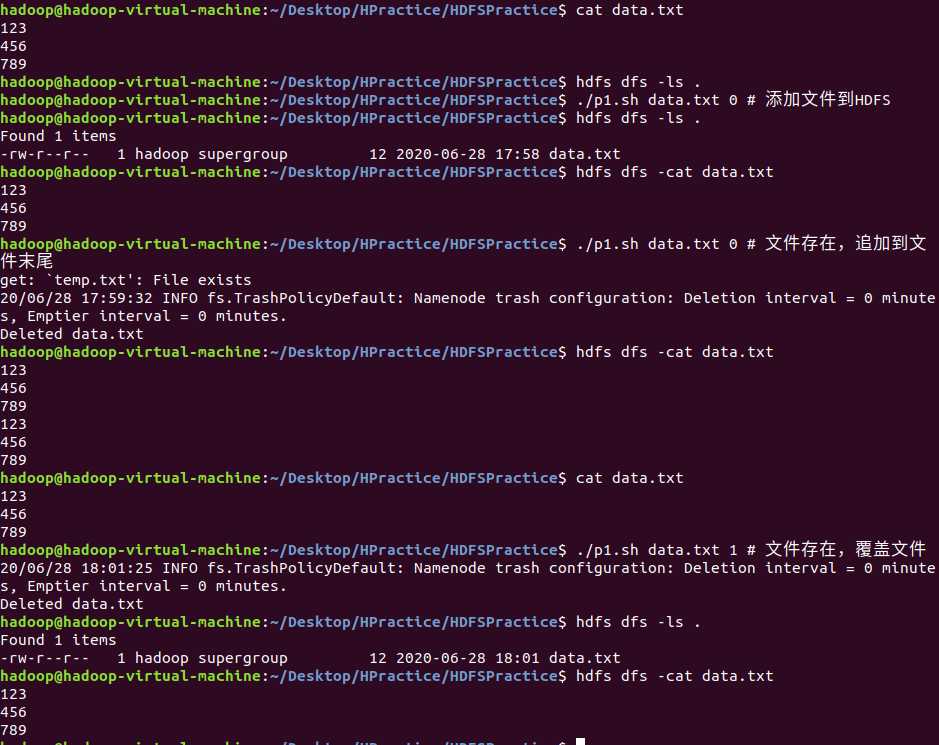
1.向HDFS中上传任意文本文件,如果指定的文件在HDFS中已经存在,由用户指定是追加到原有文件末尾还是覆盖原有的文件;
shell:
#!/bin/bash
hdfs dfs -test -e $1
if [ $? -eq 0 ] ;then
if [ $2 -eq 0 ] ;then # 表示追加到原有文件
hdfs dfs -get $1 temp.txt
cat $1 temp.txt >> temp.txt.template
hdfs dfs -rm $1
hdfs dfs -put temp.txt.template $1
rm temp.txt.template
rm temp.txt
else
hdfs dfs -rm $1
hdfs dfs -put ./$1 $1
fi
else
hdfs dfs -put ./$1 $1
fi
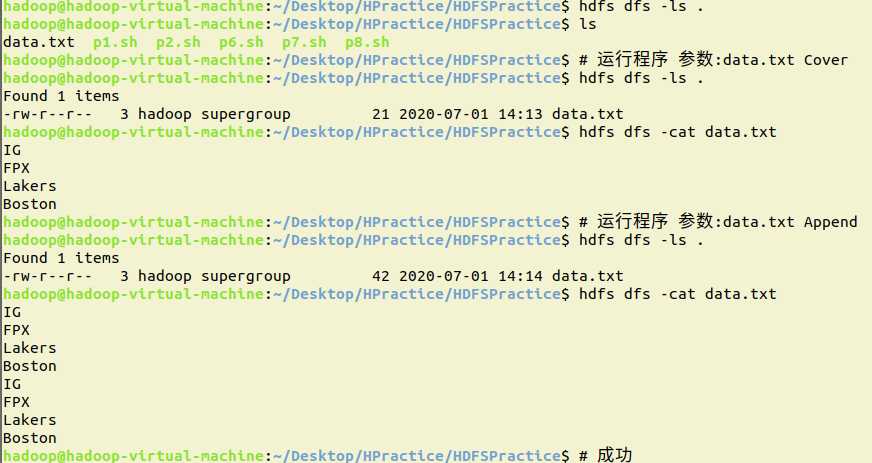
java:
追加文件不需要再create之后再使用append,写文件是create,读文件是open,追加文件内容是append
import java.io.BufferedInputStream;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
import java.util.Scanner;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class Prac1 {
public static void main(String[] args) {
Scanner input = new Scanner(System.in);
System.out.println("input filename and if it exists in hdfs,Cover or Append");
String filename = input.next();
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://localhost:9000");
conf.set("fs.hdfs.impl", "org.apache.hadoop.hdfs.DistributedFileSystem");
conf.setBoolean("dfs.support.append", true);
conf.set("dfs.client.block.write.replace-datanode-on-failure.policy", "NEVER");
conf.setBoolean("dfs.client.block.write.replace-datanode-on-failure.enabled", true);
try {
FileSystem fs = FileSystem.get(conf);
FSDataOutputStream fos;
FileInputStream is = new FileInputStream(
"/home/hadoop/Desktop/HPractice/HDFSPractice/"+filename);
Path path = new Path(filename);
String cmd = input.next();
if((fs.exists(path))&&(cmd.equals("Append")))
fos = fs.append(path);
else
fos = fs.create(path);
if(fos!=null)
{
byte[] bytes = new byte[1024];
int len;
while((len=is.read(bytes))!=-1)
fos.write(bytes,0,len);
System.out.println("上传成功");
}
else {
System.out.println("Error");
}
fs.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
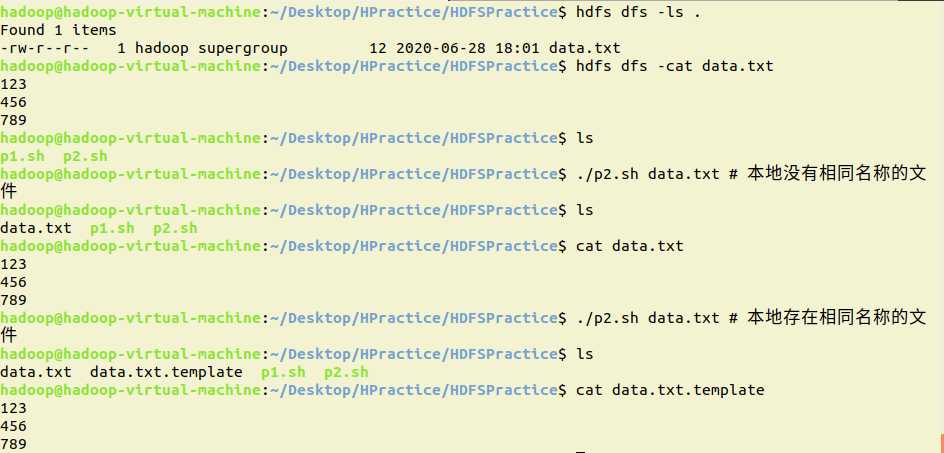
2.从HDFS中下载指定文件,如果本地文件与要下载的文件名称相同,则自动对下载的文件重命名
shell:
#~/bin/bash
test -e $1
if [ $? -eq 0 ]
then
hdfs dfs -get $1 ${1}.template
else
hdfs dfs -get $1 $1
fi
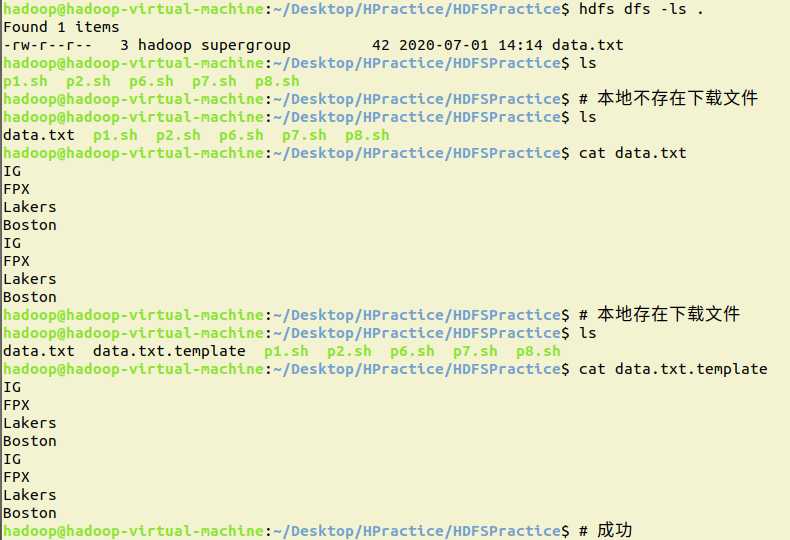
java:
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.util.Scanner;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class Prac2 {
public static void main(String[] args) {
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://localhost:9000");
conf.set("fs.hdfs.impl","org.apache.hadoop.hdfs.DistributedFileSystem" );
try {
FileSystem fs = FileSystem.get(conf);
FSDataInputStream fis;
FileOutputStream os ;
System.out.println("请输入下载的文件名:");
Scanner input = new Scanner(System.in);
String filename = input.next();
fis = fs.open(new Path(filename));
File localFile = new File("/home/hadoop/Desktop/HPractice/HDFSPractice/"+filename);
if(localFile.exists())
os = new FileOutputStream(localFile+".template");
else
os = new FileOutputStream(localFile);
byte[] bytes = new byte[1024];
int len;
while((len=fis.read(bytes))!=-1)
os.write(bytes,0,len);
System.out.println("下载成功");
fis.close();
fs.close();
os.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
3.将HDFS中指定文件的内容输出到终端中;
shell:
hdfs dfs -cat data.txt

java:
import java.io.IOException;
import java.util.Scanner;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class Prac3 {
public static void main(String[] args) {
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://localhost:9000");
conf.set("fs.hdfs.impl", "org.apache.hadoop.hdfs.DistributedFileSystem");
try {
FileSystem fs = FileSystem.get(conf);
Scanner input = new Scanner(System.in);
System.out.print("请输入HDFS中的文件:");
String filename = input.next();
FSDataInputStream fis;
if(!fs.exists(new Path(filename))) {
System.out.println("不存在该文件");
System.exit(0);
}
fis = fs.open(new Path(filename));
byte[] bytes = new byte[1024];
int len;
while((len=fis.read(bytes))!=-1)
System.out.print(new String(bytes));
System.out.println("
结束传输");//刷新缓冲区
fis.close();
fs.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}

总体代码:
接下就写switch语句里面的函数了,不再重复写赘余的部分
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.util.Scanner;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.LocatedFileStatus;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.fs.RemoteIterator;
public class Prac4_last {
static Configuration conf = new Configuration();
static FileSystem fs;
static FSDataInputStream fis;
static FSDataOutputStream fos;
static FileInputStream is;
static FileOutputStream os;
static Scanner input;
static Path filename;
public static void main(String[] args) {
try {
conf.set("fs.defaultFS", "hdfs://localhost:9000");
conf.set("fs.hdfs.impl", "org.apache.hadoop.hdfs.DistributedFileSystem");
fs = FileSystem.get(conf);
int cmd=4;
switch(cmd)
{
//。。。
}
fs.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
4.显示HDFS中指定的文件的读写权限、大小、创建时间、路径等信息
shell:
hdfs dfs -ls -h /user/hadoop

java:
private static void Prac4() throws IOException
{
System.out.print("请输入HDFS文件名:");
input = new Scanner(System.in);
filename = new Path(input.next());
FileStatus[] fileStatus = null;
if(fs.exists(filename))
fileStatus = fs.listStatus(filename);
else {
System.out.println("HDFS不存在该文件");
System.exit(1);
}
FileStatus status = fileStatus[0];
System.out.println(status.getPermission()+" "
+status.getBlockSize()+" "
+status.getAccessTime()+" "
+status.getPath()+" ");
}
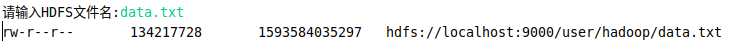
5.给定HDFS中某一个目录,输出该目录下的所有文件的读写权限、大小、创建时间、路径等信息,如果该文件是目录,则递归输出该目录下所有文件相关信息
shell:
hdfs dfs -ls -R /user/hadoop

java:
private static void Prac5() throws IOException
{
System.out.print("请输入HDFS目录名:");
input = new Scanner(System.in);
filename = new Path(input.next());
if((!fs.isDirectory(filename))&&(!fs.exists(filename))) {
System.out.println("错误,请检查输入的是否是目录名或者是存在的目录名");
System.exit(1);
}
RemoteIterator<LocatedFileStatus> fileStatus = fs.listFiles(filename,true);
//listFiles将文件找到,如果是目录也会去找里面的文件
while(fileStatus.hasNext()) {
FileStatus status = fileStatus.next();
System.out.println(status.getPermission()+" "
+status.getBlockSize()+" "
+status.getAccessTime()+" "
+status.getPath()+" ");
}
}

6.提供一个HDFS内的文件的路径,对该文件进行创建和删除操作。如果文件所在目录不存在,则自动创建目录
shell:
#!/bin/bash
# $1是目录 $2是文件
hdfs dfs -test -e $1
if [ $? -eq 0 ];then
echo "Directory exists"
else
hdfs dfs -mkdir $1
echo "Create the directory"
fi
path=$1$2
hdfs dfs -test -e $path
if [ $? -eq 0 ];then
echo -n "File exists,delete or not (y):"
read ans
if [ "$ans" = "y" ];then
hdfs dfs -rm $path
fi
else
echo -n "File doesn‘t exist,create or not(y):"
read ans
if [ "$ans" = "y" ];then
touch $2
hdfs dfs -put $2 $path
rm $2
fi
fi
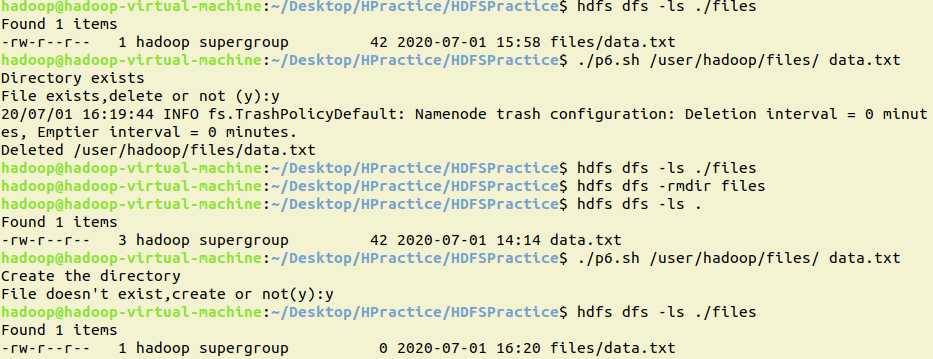
private static void Prac6() throws IOException
{
System.out.println("请输入文件完整路径和是否愿意保留该文件?");
Scanner input = new Scanner(System.in);
String file = input.next();
String[] p = file.split("/");
String cmd = input.next();
String[] temp_dir = new String[p.length-1];
for(int i=0;i<p.length;i++)
if(i<(p.length-1))
temp_dir[i]=p[i];
filename = new Path(file);
Path dir = new Path(StringUtils.join(temp_dir,"/"));
if(!fs.exists(dir)) {
fs.mkdirs(dir);
System.out.println("成功创建目录");
}
if(fs.exists(filename)) {
if(!cmd.equals("y")) {
fs.delete(filename,true);
System.out.println("成功删除该文件");}}
else {
if(cmd.equals("y")) {
fs.create(filename);
System.out.println("成功创建该文件");}}
System.out.println("程序完成");
}
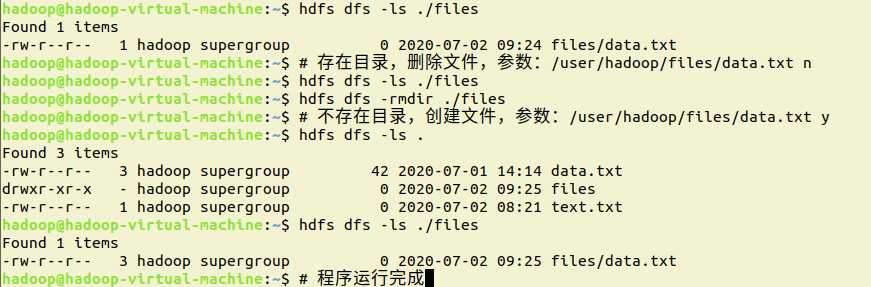
7.提供一个HDFS的目录的路径,对该目录进行创建和删除操作。创建目录时,如果目录文件所在目录不存在则自动创建相应目录;删除目录时,由用户指定当该目录不为空时是否还删除该目录
shell:
#!/bin/bash
# $1表示目录 $2表示操作
if [ "$2" = "create" ];then
hdfs dfs -test -e $1
if [ $? -eq 0 ];then
echo "Directory exists"
else
echo "Directory doesn‘t exists"
hdfs dfs -mkdir $1
echo "Create the "$1" directory"
fi
elif [ "$2"="delete" ];then
if [ `hdfs dfs -ls $1 | wc -l` -gt 0 ];then
echo "Not empty directory"
echo "Input option:"
read name
case $name in
d) hdfs dfs -rm -r $1;;
n) echo "Cancel option";;
*) echo "Error input";;
esac
else
echo "Empty directory"
hdfs dfs -rm -R $1
fi
else
echo "Error choice"
fi
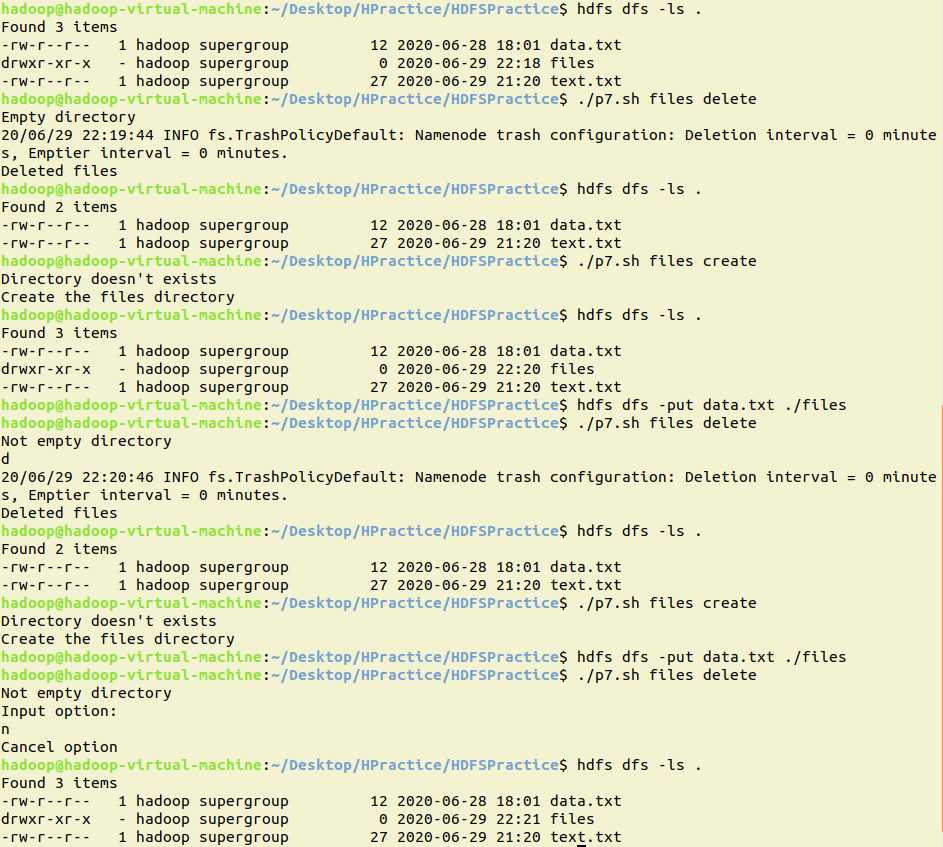
java:
private static void Prac7() throws IOException
{
System.out.print("请输入目录名称和操作(Create or Delete): ");
input = new Scanner(System.in);
filename = new Path(input.next());
String cmd = input.next();
if(cmd.equals("Create"))
{
if(!fs.exists(filename))
{
fs.mkdirs(filename);
System.out.println("成功创建目录");
}
}else if(cmd.equals("Delete"))
{
if(fs.exists(filename))
{
if(fs.listFiles(filename, true).hasNext())
{
System.out.print("要删除的目录非空,是否强制删除(y):");
input = new Scanner(System.in);
cmd = input.next();
if(cmd.equals("y"))
if(fs.delete(filename,true))
System.out.println("成功删除目录");
}
else
if(fs.delete(filename,true))
System.out.println("成功删除目录");
}else
System.out.println("不存在该目录");
}else
System.out.println("错误命令");
}
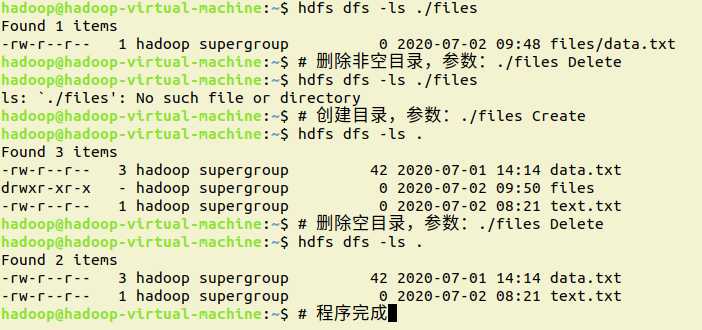
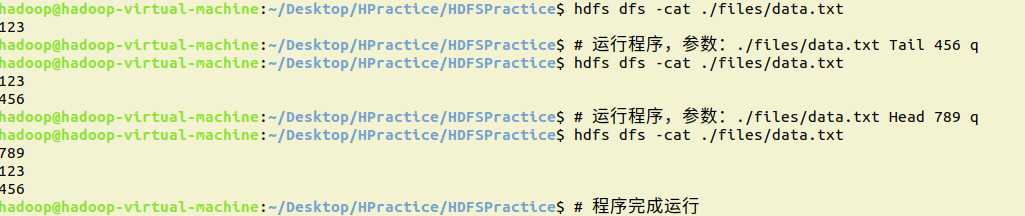
8.向HDFS中指定的文件追加内容,由用户指定内容追加到原有文件的开头或结尾
shell:
!/bin/bash
# $1表示指定HDFS中文件
hdfs dfs -test -e $1
if [ $? -eq 0 ];then
echo "Input appended content"
cat > temp.txt
hdfs dfs -get $1 $1
echo -n "Head or Tail:"
read cmd
if [ "$cmd" = "Head" ];then
cat temp.txt $1 > ${1}.template
hdfs dfs -rm $1
hdfs dfs -put ${1}.template $1
elif [ "$cmd" = "Tail" ];then
cat $1 temp.txt > ${1}.template
hdfs dfs -rm $1
hdfs dfs -put ${1}.template $1
else
echo "Wrong Commands"
fi
rm ${1}.template temp.txt $1
else
echo "File doesn‘t exist"
fi
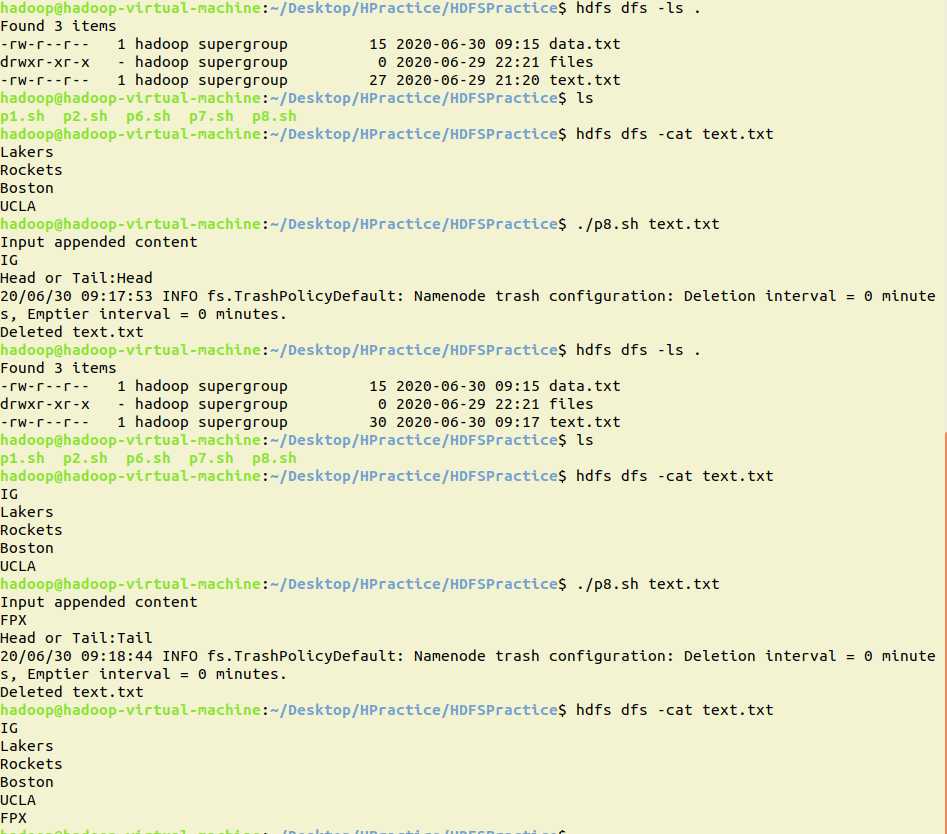
java:
当重复运行程序,参数为tail时,可能会报错org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.hdfs.protocol.RecoveryInProgressException): Failed to APPEND_FILE /user/hadoop/files/data.txt for DFSClient_NONMAPREDUCE_262443574_1 on 127.0.0.1 because lease recovery is in progress. Try again later.
稍等一会儿运行就可以了。
private static void Prac8() throws IOException
{
System.out.print("请输入指定文件和追加的方式(Head or Tail): ");
input = new Scanner(System.in);
filename = new Path(input.next());
String cmd = input.next();
System.out.println("请输入追加的内容:");
input = new Scanner(System.in);
String cont="";
String temp;
while(input.hasNextLine())
{
temp = input.nextLine();
if(temp.equals("q"))
break;
cont=cont+temp+"
";
}
if(cmd.equals("Tail"))
{
conf.setBoolean("dfs.support.append", true);
//补充的配置内容
conf.set("dfs.client.block.write.replace-datanode-on-failure.policy", "NEVER");
conf.setBoolean("dfs.client.block.write.replace-datanode-on-failure.enabled", true);
FSDataOutputStream fos = fs.append(filename);
byte[] bytes = cont.getBytes();
fos.write(bytes,0,bytes.length);
fos.close();
}
else if(cmd.equals("Head"))
{
if(!fs.exists(filename)) {
System.out.println("文件不存在");
return;
}
Path localPath = new Path("/home/hadoop/temp");
fs.moveToLocalFile(filename, localPath);
FileInputStream is = new FileInputStream("/home/hadoop/temp");
FSDataOutputStream fos = fs.create(filename);
fos.write(cont.getBytes());
byte[] b = new byte[1024];
int len;
while((len=is.read(b))!=-1)
fos.write(b,0,len);
is.close();
File f = new File("/home/hadoop/temp");
f.delete();
fos.close();
}else
System.out.println("错误命令");
System.out.println("程序结束运行");
}
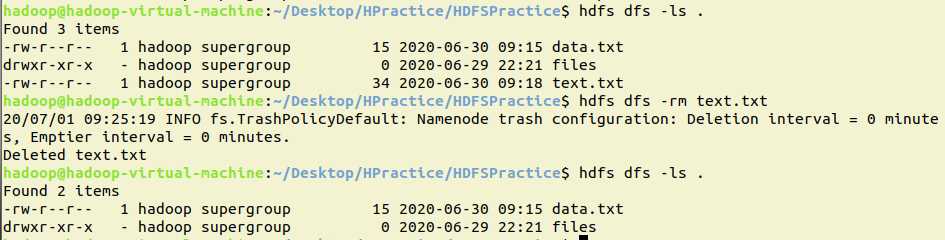
9.删除HDFS中指定的文件
shell:
hdfs dfs -rm text.txt
java:
private static void Prac9() throws IOException
{
System.out.print("请输入文件名:");
input = new Scanner(System.in);
filename = new Path(input.next());
if(!fs.exists(filename)) {
System.out.println("文件不存在");
return;
}
if(fs.delete(filename,true))
System.out.println("成功删除文件");
}
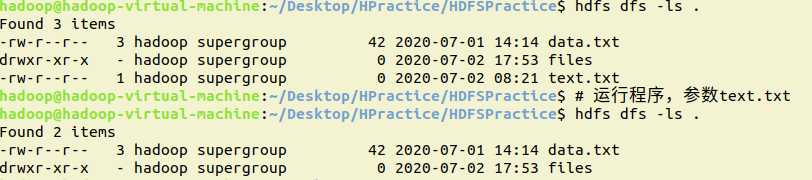
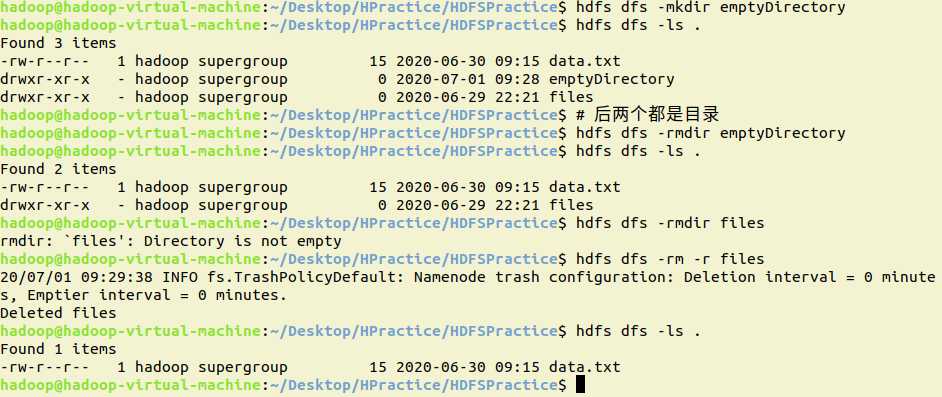
10.删除HDFS中指定的目录,由用户指定目录中如果存在文件时是否删除目录
shell:
hdfs dfs -rmdir emptyDirectory # 删除空目录,非空目录无法删除
hdfs dfs -rm -r files # 删除目录,空、非空目录都可以删除
java:
private static void Prac10() throws IOException
{
System.out.print("请输入目录名和是否强制删除(y): ");
input = new Scanner(System.in);
filename = new Path(input.next());
String cmd = input.next();
if(!fs.exists(filename)) {
System.out.println("该目录不存在");
return;
}
if(fs.listFiles(filename, true).hasNext())
{
System.out.println("目录中存在文件");
if(cmd.equals("y"))
{
if(fs.delete(filename,true))
System.out.println("成功删除目录");
else
System.out.println("删除失败");
}else
System.out.println("选择保留目录");
}else
{
if(fs.delete(filename,true))
System.out.println("成功删除目录");
else
System.out.println("删除失败");
}
}
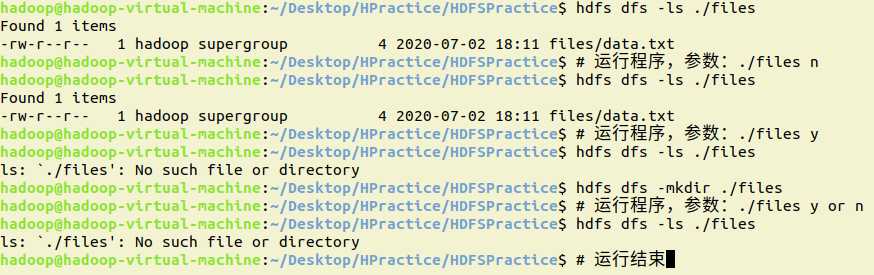
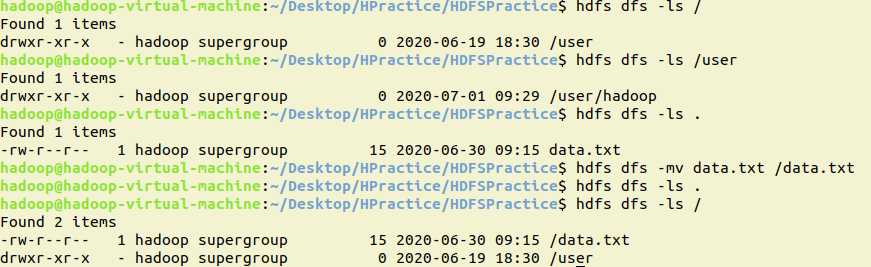
11.在HDFS中,将文件从源路径移动到目的路径
shell:
hdfs dfs -mv data.txt /data.txt
java:
private static void Prac11() throws IOException
{
System.out.print("请输入源路径和目的路径:");
input = new Scanner(System.in);
Path src = new Path(input.next());
Path tar = new Path(input.next());
if(!fs.exists(src))
{
System.out.println("源文件不存在");
return ;
}
if(fs.rename(src, tar))
System.out.println("移动成功");
else
System.out.println("移动失败");
}
12.编程实现一个类“MyFSDataInputStream”,该类继承“org.apache.hadoop.fs.FSDataInputStream”,要求如下:实现按行读取HDFS中指定文件的方法“readLine()”,如果读到文件末尾,则返回空,否则返回文件一行的文本。
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
public class MyFSDataInputStream extends FSDataInputStream{
private static MyFSDataInputStream my;
private static InputStream inputStream;
public MyFSDataInputStream(InputStream in) {
super(in);
inputStream = in;
}
public static MyFSDataInputStream getInstance(InputStream inputStream){
if (null == my){
synchronized (MyFSDataInputStream.class){
if (null == my){
my = new MyFSDataInputStream(inputStream);
}
}
}
return my;
}
public static String readline(FileSystem fileStatus)
{
BufferedReader bfr = new BufferedReader(new InputStreamReader(inputStream));
String line = null;
try {
if((line=bfr.readLine())!=null)
{
bfr.close();
inputStream.close();
return line;
}
} catch (IOException e) {
e.printStackTrace();
}
return null;
}
}
13.查看Java帮助手册或其它资料,用“java.net.URL”和“org.apache.hadoop.fs.FsURLStreamHandlerFactory”编程完成输出HDFS中指定文件的文本到终端中
这个题目的重点似乎在于怎么用URL链接到HDFS,这个我是借鉴了网上的,感觉就是这么回事儿(很有可能是自己才疏学浅??
这里需要输入完整的路径,不然会报错。
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.URL;
import java.util.Scanner;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.FsUrlStreamHandlerFactory;
import org.apache.hadoop.fs.Path;
public class last {
private static Path filename;
private static FileSystem fs;
public static void main(String[] args) throws IOException {
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://localhost:9000");
conf.set("fs.hdfs.impl", "org.apache.hadoop.hdfs.DistributedFileSystem");
fs = FileSystem.get(conf);
System.out.print("输入文件名称: ");
Scanner input = new Scanner(System.in);
filename = new Path(input.next());
if(!fs.exists(filename)) {
System.out.println("文件不存在");
System.exit(1);
}
show();
}
public static void show()
{
try {
URL.setURLStreamHandlerFactory(new FsUrlStreamHandlerFactory());
InputStream is = new URL("hdfs","localhost",9000,filename.toString()).openStream();
BufferedReader bfr = new BufferedReader(new InputStreamReader(is));
String line = null;
while((line = bfr.readLine())!=null)
System.out.println(line);
}catch(IOException e) {
e.printStackTrace();
}
}
}

人生此处,绝对乐观
以上是关于HDFS操作实验的主要内容,如果未能解决你的问题,请参考以下文章