大数据 | 实验一:大数据系统基本实验 | 熟悉常用的HDFS操作
Posted 啦啦右一
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据 | 实验一:大数据系统基本实验 | 熟悉常用的HDFS操作相关的知识,希望对你有一定的参考价值。
文章目录
📚实验目的
1)理解 HDFS 在 Hadoop 体系结构中的角色。
2)熟练使用 HDFS 操作常用的 shell 命令。
3)熟悉 HDFS 操作常用的 Java API。
📚实验平台
1)操作系统:Linux;
2)Hadoop 版本:3.2.2;
3)JDK 版本:1.8;
4)Java IDE:Eclipse。
📚实验内容
编程实现以下功能,并利用 Hadoop 提供的 Shell 命令完成相同任务
⭐️HDFSApi
1)向 HDFS 中上传任意文本文件。如果指定的文件在 HDFS 中已经存在,则由用户来指定是追加到原有文件末尾还是覆盖原有的文件;
Shell命令
检查文件是否存在,可以使用如下命令:
cd /usr/local/hadoop
./bin/hdfs dfs -test -e text.txt
#执行完上述命令不会输出结果,需要继续输入以下命令查看结果
echo $?
重启了虚拟机开始做这个实验,一开始出现报错,搜索后发现原来是hadoop没开



echo $? 返回上一个命令的状态,0表示没有错误,其他任何值表明有错误(这里显然出错,因为还没有建text.txt文件夹),手动建一个text.txt然后拖到/usr/local/hadoop。

用户可以选择追加到原来文件末尾或者覆盖原来文件
cd /usr/local/hadoop
./bin/hdfs dfs -appendToFile local.txt text.txt #追加到原文件末尾
#touch local.txt
./bin/hdfs dfs -copyFromLocal -f local.txt text.txt #覆盖原来文件,第一种命令形式
./bin/hdfs dfs -cp -f file:///usr/local/hadoop/local.txt text.txt#覆盖原来文件,第二种命令形式

这样会自动建一个local.txt文件

实际上,也可以不用上述方法,而是采用如下命令来实现
if $(hdfs dfs -test -e text.txt);
then $(hdfs dfs -appendToFile local.txt text.txt);
else $(hdfs dfs -copyFromLocal -f local.txt text.txt);
fi

编程实现

package HDFSApi;
import java.util.Scanner;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import java.io.*;
public class HDFSApi
/*
判断路径是否存在
*/
public static boolean test(Configuration conf, String path) throws IOException
FileSystem fs = FileSystem.get(conf);
return fs.exists(new Path(path));
/*
复制文件到指定路径
若路径已存在,则进行覆盖
*/
public static void copyFromLocalFile(Configuration conf, String localFilePath, String remoteFilePath) throws IOException
FileSystem fs = FileSystem.get(conf);
Path localPath = new Path(localFilePath);
Path remotePath = new Path(remoteFilePath);
/* fs.copyFromLocalFile 第一个参数表示是否删除源文件,第二个参数表示是否覆盖 */
fs.copyFromLocalFile(false, true, localPath, remotePath);
fs.close();
/*
追加文件内容
*/
public static void appendToFile(Configuration conf, String localFilePath, String remoteFilePath) throws IOException
FileSystem fs = FileSystem.get(conf);
Path remotePath = new Path(remoteFilePath);
/* 创建一个文件读入流 */
FileInputStream in = new FileInputStream(localFilePath);
/* 创建一个文件输出流,输出的内容将追加到文件末尾 */
FSDataOutputStream out = fs.append(remotePath);
/* 读写文件内容 */
byte[] data = new byte[1024];
int read = -1;
while ( (read = in.read(data)) > 0 )
out.write(data, 0, read);
out.close();
in.close();
fs.close();
/*
主函数
*/
public static void main(String[] args)
Configuration conf = new Configuration();
conf.set("fs.default.name","hdfs://localhost:9000");
String localFilePath = "/usr/local/hadoop/local.txt";
String remoteFilePath = "/usr/local/hadoop/text.txt";
String choice = "append";
String choice2 = "overwrite";
Scanner in=new Scanner(System.in);
String a=in.nextLine();
boolean a1= a.contentEquals(choice2);
boolean a2=a.contentEquals(choice);
//System.out.println(a.contentEquals(choice));//
try
/* 判断文件是否存在 */
Boolean fileExists = false;
if (HDFSApi.test(conf, remoteFilePath))
fileExists = true;
System.out.println(remoteFilePath + " 已存在.");
else
System.out.println(remoteFilePath + " 不存在.");
if ( !fileExists)
//文件不存在,则上传
HDFSApi.copyFromLocalFile(conf, localFilePath, remoteFilePath);
System.out.println(localFilePath + " 已上传至 " + remoteFilePath);
else if (a2)
//选择覆盖
HDFSApi.copyFromLocalFile(conf, localFilePath, remoteFilePath);
System.out.println(localFilePath + " 已覆盖 " + remoteFilePath);
else if(a1)
//选择追加
HDFSApi.appendToFile(conf, localFilePath, remoteFilePath);
System.out.println(localFilePath + " 已追加至 " + remoteFilePath);
catch (Exception e)
e.printStackTrace();
⭐️HDFSApi2
2)从 HDFS 中下载指定文件。如果本地文件与要下载的文件名称相同,则自动对下载的文件重命名;
Shell命令
if $(./bin/hdfs dfs -test -e file:///usr/local/hadoop/text.txt);
then $(./bin/hdfs dfs -copyToLocal text.txt ./text2.txt);
else $(./bin/hdfs dfs -copyToLocal text.txt ./text.txt);
fi

编程实现

package HDFSApi;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import java.io.*;
public class HDFSApi2
/*
下载文件到本地
判断本地路径是否已存在,若已存在,则自动进行重命名
*/
public static void copyToLocal(Configuration conf, String remoteFilePath, String localFilePath) throws IOException
FileSystem fs = FileSystem.get(conf);
Path remotePath = new Path(remoteFilePath);
File f = new File(localFilePath);
if(f.exists())
//如果文件名存在,自动重命名(在文件名后面加上 _0, _1 ...)
System.out.println(localFilePath + " 已存在.");
Integer i = 0;
while (true)
f = new File(localFilePath + "_" + i.toString());
if (!f.exists())
localFilePath = localFilePath + "_" + i.toString();
break;
System.out.println("将重新命名为: " + localFilePath);
// 下载文件到本地
Path localPath = new Path(localFilePath);
fs.copyToLocalFile(remotePath, localPath);
fs.close();
/*
主函数
*/
public static void main(String[] args)
Configuration conf = new Configuration();
conf.set("fs.default.name","hdfs://localhost:9000");
String localFilePath = "/usr/local/hadoop/local.txt";
String remoteFilePath = "/usr/local/hadoop/text.txt";
try
HDFSApi2.copyToLocal(conf, remoteFilePath, localFilePath);
System.out.println("下载完成");
catch (Exception e)
e.printStackTrace();
⭐️HDFSApi3
3)将 HDFS 中指定文件的内容输出到终端中;
Shell命令
hdfs dfs -cat text.txt

刚开始先跑shell,运行不报错,但无内容输出(但txt里是有内容的)。编程实现跑了一遍,再回去跑shell就有输出了(?
编程实现

package HDFSApi;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import java.io.*;
public class HDFSApi3
public static void cat(Configuration conf, String remoteFilePath) throws IOException
/*
读取文件内容
*/
FileSystem fs = FileSystem.get(conf);
Path remotePath = new Path(remoteFilePath);
FSDataInputStream in = fs.open(remotePath);
BufferedReader d = new BufferedReader(new InputStreamReader(in));
String line = null;
while ( (line = d.readLine()) != null )
System.out.println(line);
d.close();
in.close();
fs.close();
/*
主函数
*/
public static void main(String[] args)
Configuration conf = new Configuration();
conf.set("fs.default.name","hdfs://localhost:9000");
String remoteFilePath = "/usr/local/hadoop/text.txt"; // HDFS 路径
try
System.out.println("读取文件: " + remoteFilePath);
HDFSApi3.cat(conf, remoteFilePath);
System.out.println("\\n 读取完成");
catch (Exception e)
e.printStackTrace();
⭐️HDFSApi4
4)显示 HDFS 中指定的文件的读写权限、大小、创建时间、路径等信息;
Shell命令
hdfs dfs -ls -h text.txt

编程实现
package HDFSApi;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import java.io.*;
import java.text.SimpleDateFormat;
public class HDFSApi4
/*
显示指定文件的信息
*/
public static void ls(Configuration conf, String remoteFilePath) throws IOException
FileSystem fs = FileSystem.get(conf);
Path remotePath = new Path(remoteFilePath);
FileStatus[] fileStatuses = fs.listStatus(remotePath);
for (FileStatus s : fileStatuses)
System.out.println("路径: " + s.getPath().toString());
System.out.println("权限: " + s.getPermission().toString());
System.out.println("大小: " + s.getLen());
/* 返回的是时间戳,转化为时间日期格式 */
Long timeStamp = s.getModificationTime();
SimpleDateFormat format = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
String date = format.format(timeStamp);
System.out.println("时间: " + date);
fs.close();
/**
* 主函数
*/
public static void main(String[] args)
Configuration conf = new Configuration();
conf.set("fs.default.name","hdfs://localhost:9000");
String remoteFilePath = "/usr/local/hadoop/text.txt"; // HDFS 路径
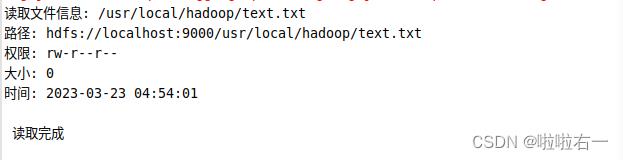
try
System.out.println("读取文件信息: " + remoteFilePath);
HDFSApi4.ls(conf, remoteFilePath);
System.out.println("\\n 读取完成");
catch (Exception e)
e.printStackTrace();
⭐️HDFSApi5
5)给定 HDFS 中某一个目录,递归输出该目录下的所有文件的读写权限、大小、创建时间、路径等信息;
Shell命令
cd /usr/local/hadoop
./bin/hdfs dfs -ls -R -h /usr/hadoop

编程实现

package HDFSApi;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import java.io.*;
import java.text.SimpleDateFormat;
public class HDFSApi5
/*
显示指定文件夹下所有文件的信息(递归)
*/
public static void lsDir(Configuration conf, String remoteDir) throws IOException
FileSystem fs = FileSystem.get(conf);
Path dirPath = new Path(remoteDir);
/* 递归获取目录下的所有文件 */
RemoteIterator<LocatedFileStatus> remoteIterator = fs.listFiles(dirPath, true);
/* 输出每个文件的信息 */
while (remoteIterator.hasNext())
FileStatus s = remoteIterator.next();
System.out.println("路径: " + s.getPath().toString());
System.out.println("权限: " + s.getPermission().toString());
System.out.println("大小: " + s.getLen());
/* 返回的是时间戳,转化为时间日期格式 */
Long timeStamp = s.getModificationTime();
SimpleDateFormat format = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss"
{ "id":2, "name":"Bob","age":29 }
{ "id":3 , "name":"Jack","age":29 }
{ "id":4 , "name":"Jim","age":28 }
{ "id":4 , "name":"Jim","age":28 }
{ "id":5 , "name":"Damon" }
{ "id":5 , "name":"Damon" }
为 employee.json 创建 DataFrame,并写出 Scala 语句完成下列操作:
(1) 查询所有数据;
主讲教师:林子雨 http://www.cs.xmu.edu.cn/linziyu 第 1 页厦门大学林子雨,赖永炫,陶继平 编著《Spark 编程基础(Scala 版)》 教材配套机房上机实验指南
实验 5 Spark SQL 编程初级实践
主讲教师:林子雨 http://www.cs.xmu.edu.cn/linziyu 第 2 页
(2) 查询所有数据,并去除重复的数据;
(3) 查询所有数据,打印时去除 id 字段;
(4) 筛选出 age>30 的记录;
(5) 将数据按 age 分组;
(6) 将数据按 name 升序排列;
(7) 取出前 3 行数据;
(8) 查询所有记录的 name 列,并为其取别名为 username;
(9) 查询年龄 age 的平均值;
(10) 查询年龄 age 的最小值。
2.编程实现将 RDD 转换为 DataFrame
源文件内容如下(包含 id,name,age):
1,Ella,36
2,Bob,29
3,Jack,29
请将数据复制保存到 Linux 系统中,命名为 employee.txt,实现从 RDD 转换得到
DataFrame,并按“id:1,name:Ella,age:36”的格式打印出 DataFrame 的所有数据。请写出程序代
码。
3. 编程实现利用 DataFrame 读写 MySQL 的数据
(1)在 MySQL 数据库中新建数据库 sparktest,再创建表 employee,包含如表 6-2 所示的
两行数据。
表 6-2 employee 表原有数据
id
name
gender
Age
1
Alice
F
22
2
John
M
25
(2)配置 Spark 通过 JDBC 连接数据库 MySQL,编程实现利用 DataFrame 插入如表 6-3 所
示的两行数据到 MySQL 中,最后打印出 age 的最大值和 age 的总和。
表 6-3 employee 表新增数据
id
name
gender
age
3
Mary
F
26
4
Tom
M
23以上是关于大数据 | 实验一:大数据系统基本实验 | 熟悉常用的HDFS操作的主要内容,如果未能解决你的问题,请参考以下文章