怎么用bioedit在基因组序列中找出已知序列的序列相似
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了怎么用bioedit在基因组序列中找出已知序列的序列相似相关的知识,希望对你有一定的参考价值。
最近在做实验,需要用到生物信息学软件,但不知怎么用,望高手指教..具体是对实验室中的一种菌进行了基因组测序,得到很多Contig,现有另一种菌的一个基因序列,怎么利用bioedit软件在基因组序列中找出与这个基因序列相似性较高的Contig,不胜感激!
Bioedit提供了本地blast工具(菜单里的local blast 功能),如图一。
你需要把基因组数据做成本地数据库,使用菜单里的create a local nucleotide database file功能建立本地DNA数据库,建库的原始数据需要做成fasta格式的,建成的数据库存放在...\\bioedit\\database文件夹里。
然后用另一种菌的基因序列和基因组本地数据库做blastn或者tblastx(图二),就能找到与这个基因序列相似性较高的contig了。
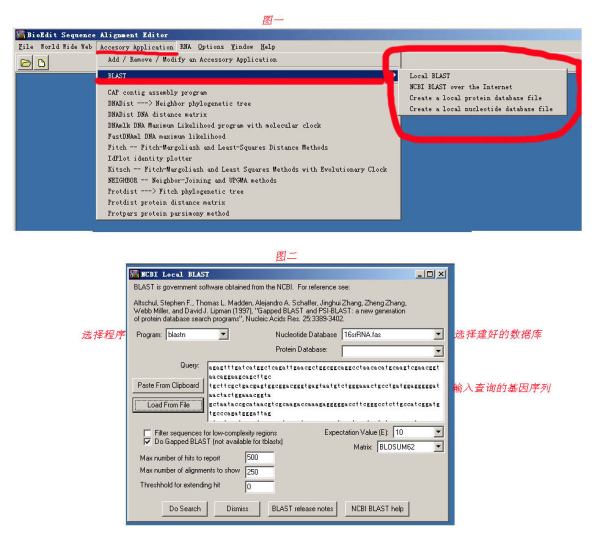
我的bioedit版本较低,估计也能参考吧。
也可以直接从NCBI下载本地blast相关程序,使用dos命令行操作。
参考技术A 1. 用已有的contig序列制作一个数据库。2. 用新的序列作为query, 数据库选择刚刚建好的那个,设置blastn参数(就是定义相似性)
通常看e-value,越小越好,然后看hits的长度。如果相似性很高,但覆盖率比较小,也不是你希望的结果。
怎样在genbank基因库中找出我需要的基因序列啊?
我想做植物中一种酶的基因克隆,NCBI上只有植物的全基因测序结果,但是我想做的酶的基因可能是推测出来的,不能直接在基因库中查询的该酶基因的序列,现在我想设计引物,需要提供该酶的基因序列,我该怎么办?这个问题已经困扰我很久了,不知道怎么解决,希望各位高手能够知道一下,不胜感激!!!
在GeneBank 中查找基因序列只要输入accession号就可以了 ,下面网址就是一个基因的全部序列信息的例子,http://www.ncbi.nlm.nih.gov/Sitemap/samplerecord.html,在记录的末尾有各种记录的详细说明,如果你没有accession号,可以把你手头的编号用source等信息源转换成accession号,中文教程太古老了,如果你是初学者一定要养成看英文文献的习惯,要是特别想看中文翻译的话,书店里随便一本生物信息学书里都会介绍数据库的,不过有些翻译过来的东西真的很别扭。 2、关于在GeneBank中查找序列我有几点体会: 最直接、最简单的方法是手头有基因的accession号;如果没有就需要明确两个重要的内容,即基因名称及物种信息(如果有最好是拉丁全名),基因名称尽可能详细,避免搜出一些不相关的信息;
搜索的时候建议先用NCBI的Gene数据库搜索,这样得到的accession号是属于NCBI工作人员重新整理过的Refseq的序列,这样会比较可靠;当然这个要看你的分析目的,如果你是要对该序列进行下游的分子生物学操作or分析,选这种序列我觉得会比较好,如果是要进行多序列的分析or其他目的需要全面分析该序列的,可能需要其他序列做补充,但是我觉得序列越多问题越说不清楚,因为毕竟不是自己的序列,如果Gene数据库里没有收录,那就只有在Nucleotide数据库里找了,但是还是建议采用Refseq的序列,Refseq序列特征如下:
Accession prefix Molecule type Comment
AC_ Genomic Complete genomic molecule, alternate assembly NC_ Genomic Complete genomic molecule, reference assembly NG_ Genomic Incomplete genomic region
NT_ Genomic Contig or scaffold, clone-based or WGSa NW_ Genomic Contig or scaffold, primarily WGSa NS_ Genomic Environmental sequence NZ_b Genomic Unfinished WGS NM_ mRNA NR_ RNA
XM_c mRNA Predicted model XR_c RNA Predicted model
AP_ Protein Annotated on AC_ alternate assembly NP_ Protein YP_c Protein
XP_c Protein Predicted model
ZP_c Protein Predicted model, annotated on NZ_ genomic records a Whole Genome Shotgun sequence data. b An ordered collection of WGS for a genome. c Computed.
其他值得考虑的是,对于真核生物最好找注释为全长的mRNA序列,原核生物最好有起始密码子和终止密码子 参考技术A 既然你知道给酶的基本信息,那么一定有很多文献报道,包括克隆信息等等。而且只要你知道该基因的名称,必定会从genebank中extrat到一些序列,如果实在不行,只能从同源性上找,利用保守序列去钓一钓呢? 参考技术B 先从文献找找酶的信息,在ncbi上查,没有该酶相关信息的话,可以从同源性高的其他植物中,利用保守序列去尝试
以上是关于怎么用bioedit在基因组序列中找出已知序列的序列相似的主要内容,如果未能解决你的问题,请参考以下文章
GENES模块---批量的引物设计、批量的序列提取以及批量翻译