恒源云_语音识别与语义处理领域之 NAG 优化器
Posted AI酱油君
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了恒源云_语音识别与语义处理领域之 NAG 优化器相关的知识,希望对你有一定的参考价值。
文章来源 | 恒源云社区(专注人工智能/深度学习云 GPU 服务器训练平台,官方体验网址:恒源智享云)
原文地址 | NAG优化器
原文作者 | 角灰
社区人才济济,小编今天又发现一个宝藏版主‘角灰’。
小编是个爱分享的人,看见好文章好作者怎能控制住不分享给大家呢?所以,接下来跟着小编我,一起快速浏览一下文章内容吧!
正文开始
最近在看fairseq源码时发现NAG优化器 (Nesterov Accelerate gradient)的实现与torch自带的有些许不一样,于是打算查下资料了解清楚。
先回忆下Momentm,该梯度下降法引入动量的概念,使用β对历史梯度进行滑动指数加权平均,最早的梯度衰减的最快,对当前更新影响小;反之,越接近当前的梯度对更新的影响越大,公式为:
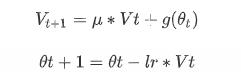
其中Vt、gt、g(θt)分别代表t时刻的速度、梯度、模型参数,μ是动量系数,lr是学习率。该方法的思想是对网络参数进行平滑处理,让梯度的摆动幅度不要太大。
NAG类似Momentum,它们都是利用历史梯度来更新参数,区别在于,NAG先利用μVt,对θt进行部分更新得到θt+μVt,然后利用梯度g(θt+μVt)更新得到θt+1,其公式如下所示:
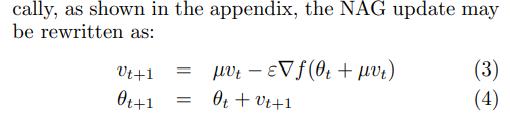
此处ε是学习率。
下图对Momentum和NAG作了形象解释:
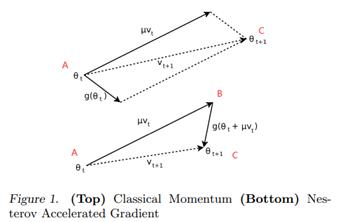
Momentum使用当前位置A处的速度Vt和梯度g(θt)直接更新到目的地C;而NAG从A点先沿着惯性方向走一小步到B,此处距C很接近了, 再利用B处的梯度g(θt+μVt)更新到C。
论文中认为这样可以快速更新V,使得Nag比momentum更稳定,且更适合于大学习率的场景。除此之外,如果Nag用μVt更新到B点较差时,由于B点梯度g(θt+μVt)比momentum的g(θt)更大,因此Nag能更快往回修正到起始点A。
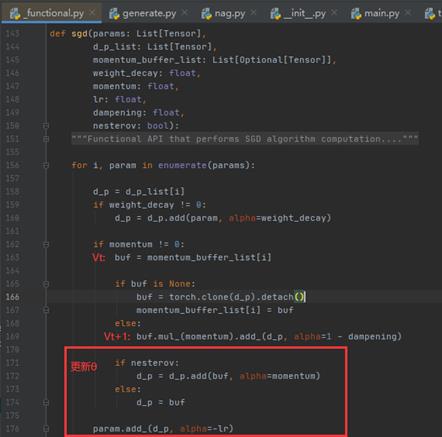
言归正传,这是torch.optim.SGD的公式和代码[1]:
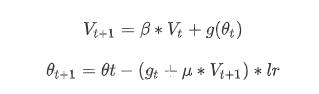
这是fairseq.optim.nag的公式和代码[2]:
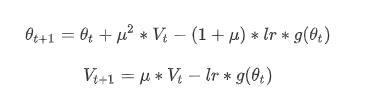
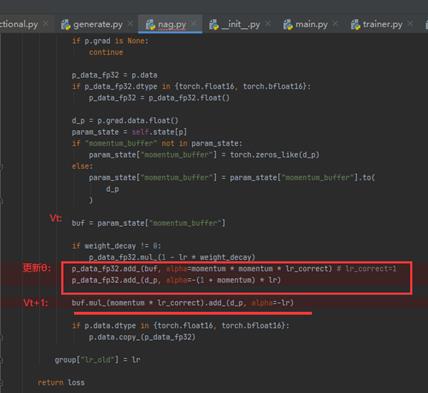
可以看出两者实际上还是有些不同,而Fairseq的nag实际上和论文的公式基本一致,[3]中有推导:
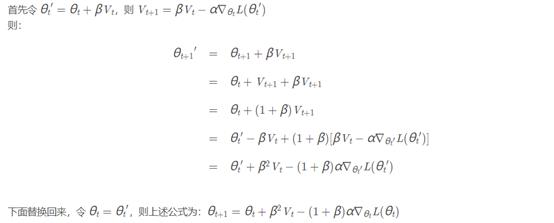
其中的β就是本文的动量系数μ,先对θt+βVt做了代换得到θt’后,最后将θt’当成待更新的参数θt,也就是每次更新的始终是θt+βVt,关于这个的解释见下图及[4]:
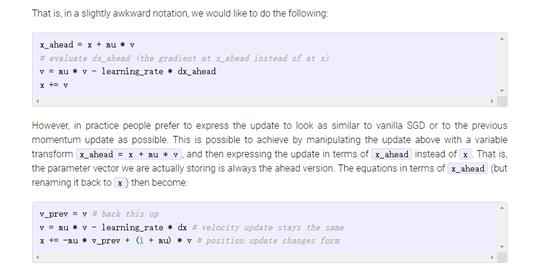
总之,nag优化器能加速收敛,且使用很大的学习率也很稳定,难怪fairseq里面ConvS2S能使用0.5的学习率。
[1]torch sgd
[2]fairseq nag
[3]深度学习中优化方法
[4]CS231n Convolutional Neural Networks for Visual Recognition
以上是关于恒源云_语音识别与语义处理领域之 NAG 优化器的主要内容,如果未能解决你的问题,请参考以下文章
恒源云(GPUSHARE)_语音识别与语义处理领域之[机器翻译] 21.7 mRASP2
恒源云(GPUSHARE)_语音识别与语义处理领域之[机器翻译] 21.7 mRASP2
恒源云_attention decoder效果不佳时如何应对