恒源云(GPUSHARE)_语音识别与语义处理领域之[机器翻译] 21.7 mRASP2
Posted AI酱油君
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了恒源云(GPUSHARE)_语音识别与语义处理领域之[机器翻译] 21.7 mRASP2相关的知识,希望对你有一定的参考价值。
文章来源 | 恒源云社区(一个专注 AI 行业的共享算力平台恒源智享云)
原文地址 | [机器翻译] 21.7 mRASP2
原文作者 | 角灰
Contrastive Learning for Many-to-many Multilingual Neural Machine Translation
github:
摘要:
现有的多语言模型聚焦于英语为中心的翻译,而非英语的方向远远落后。本文旨在一个多对多翻译系统,重点是非英语语言方向的质量。基于这样一个假设:通用的跨语言表示会导致更好的多语言翻译性能。为此提出了一种训练方法mRASP2,以获得单一统一的多语言翻译模型。mRASP2的核心在于如下两点:
- 通过对比学习拉近多语言表示对齐语义空间
- 同时使用平行和单语语料进行对齐增强
结论:
- 对比学习确实能提升零资源翻译
- 使用单语数据,所有翻译方向上都取得了实质性的改进。
- 分析并可视化了本文方法,对比学习确实能够拉近不同语言语义的表征
- 未来打算使用更大数据集训练模型PC150
方法:
1.损失函数
损失为交叉熵Lce和对比损失Lctr的加权和,|s|是平均句子长度,因为Lce是词级别的,而Lctr是序列级别的,两者有比例关系,因此要乘上平均句子长度。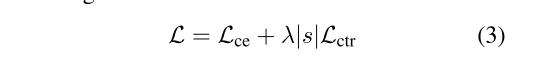
xi,xj是平行语料。Lce计算常规decoder输出和label的交叉熵,旨在让解码器输出分布与真实分布一致。
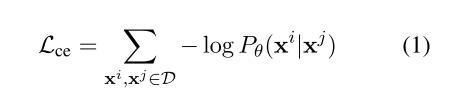
而对比损失Lctr为了拉近语义空间中跨语言同义词的表征距离,并且拉远非同义词表征的距离。具体为:以某个样本点的源端向量表示为锚点,以该样本目标端的向量表征为正样本(过encoder),以同一个batch中其他样本点的目标端句子向量表示为负样本,最小化锚点和正样本的距离,最大化锚点和所以负样本的距离。
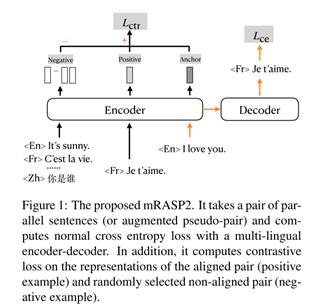
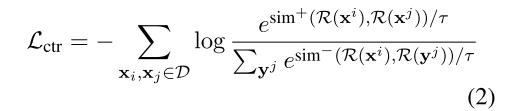
其中距离使用的是余弦距离,分子是锚点和正例的距离,分母是所有负例和锚点的距离和,通过最小化Lctr就能达到拉近同义词表征、拉远非同义词表征的目的。
引入对比学习,可以在不降低其他翻译方向的基础上,提高零资源翻译的性能。
2.对齐增强
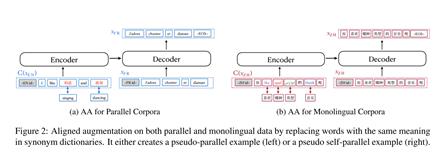
其中距离使用的是余弦距离,分子是锚点和正例的距离,分母是所有负例和锚点的距离和,通过最小化Lctr就能达到拉近同义词表征、拉远非同义词表征的目的。
实验结果
相比多语言基线模型m-Transformer,mRASP2在表中的10个方向上都有显著的提升。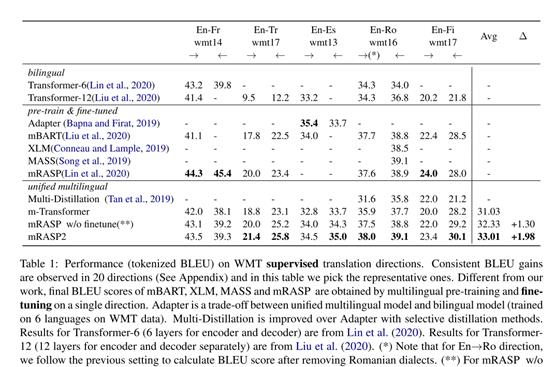
在无监督翻译(至少一端的语料在预训练时出现过)上平均超过了基线十多点。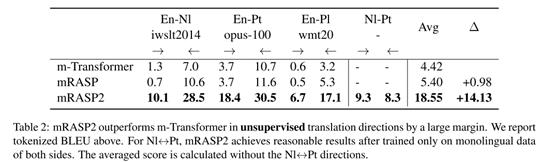
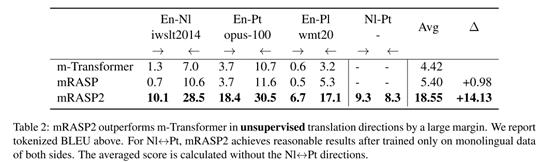
即使是在零资源翻译(非英语对翻译)上性能也很卓越,和桥接模型差不多(pivot)。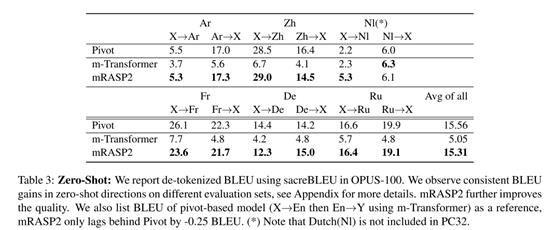
可视化分析
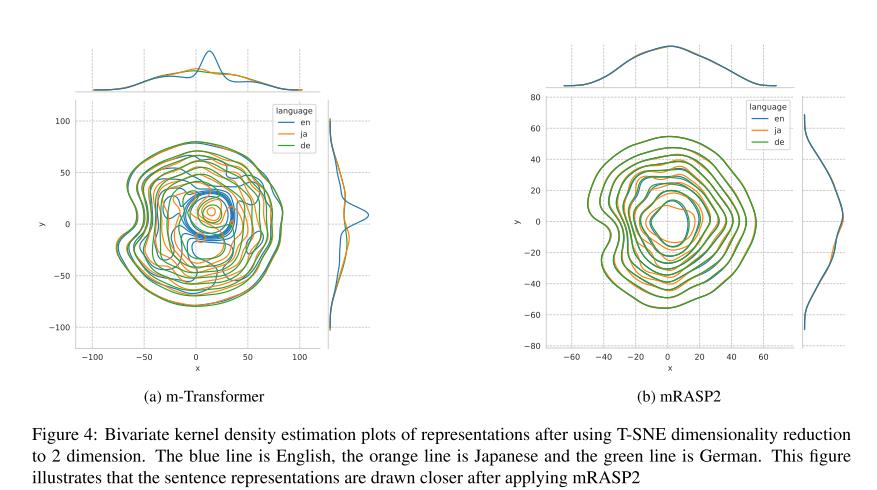
使用T-SNE对英、日、德三种语言同义句的语义空间表征降维后可视化,发现使用mRASP(b)比基线transformer更好的拉近了多语言同义句的语义表征。
个人总结
对比学习yyds,接下来准备找代码试试。
以上是关于恒源云(GPUSHARE)_语音识别与语义处理领域之[机器翻译] 21.7 mRASP2的主要内容,如果未能解决你的问题,请参考以下文章
恒源云(GPUSHARE)_attention decoder效果不佳时如何应对