恒源云_语音识别与语义处理领域之低资源机器翻译综述
Posted AI酱油君
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了恒源云_语音识别与语义处理领域之低资源机器翻译综述相关的知识,希望对你有一定的参考价值。
文章来源 | 恒源云社区
原文地址 | 低资源机器翻译综述
原文作者 | 角灰
摘要
神经机器翻译效果非常好,但需要大量的平行语料,因此有了低资源翻译的研究。
本文按照按数据的利用对低资源翻译分为3类:
- 利用单语数据
- 利用辅助语言
- 利用多模态数据

结论和未来方向
目前还有如下开放问题:
- 在多语言迁移学习中,尚不知道应该用多少语言、哪些语言。
- 在迁移学习中如何处理未见过语言的词表
- 如何高效选择数轴语言
- 双语词典非常有用且易得,目前的研究主要用在源语言和目标语言上,如何用在多语言迁移学习中的低资源和辅助语言上
- 考虑到多模态数据,语音有提升翻译性能的潜力,同时也有许多限制,比如有同音异字
- 目前在低资源翻译上取得成功的方法,或者有大量单语语料,或者有相似的富资源语言。如果两个都没有怎么办,如阿迪格语和锡伯语。
2.利用单语数据

2.1 回译、前向翻译
回译:用tgt2src的反向翻译模型将目标语言的单语语料t转换为源语言,从而得到伪平行数据Bp(tgt2src(t),t)。
前向翻译:相反,用src2tgt的正向翻译模型将源语言的单语语料s转换为目标语言,从而得到伪平行数据Bp’(s, src2tgt(s))。
将产生的伪数据Bp, Bp’和真的平行语料Dp混合后训练正向模型有助于性能提升。
除了使用术搜索生成伪数据外,还有许多方法:
(1)根据输出概率分布随机采样
(2)在源语言添加噪声,再结合术搜索生成
(3)对术搜索生成的句子预先添加标签
随机采样和加噪声只在富资源语言上奏效,而第三种预添加标签在富、低资源翻译上都表现最好。除此之外,在低资源翻译上,将目标语言拷贝到源语言也能进一步提升翻译质量。
2.2 双向联合训练
(1)考虑到源语言和目标语言都很稀缺的情况,可以使用对偶学习,将源语言x经前向模型得到y’,再输入反向模型回译成x’,优化x和x’的重建损失。后面有人提出multi-agent进一步提升对偶学习。,
(2)直观上,更好的回译模型带来更好的伪数据,从而训练出更好的翻译系统。使用迭代回译可以重复执行回译、训练的过程,从而使模型生成越来越高质量的句子,得到更好的NMT系统,流程如下图:
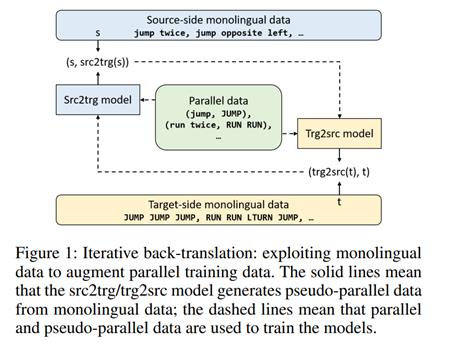
2.3无监督NMT
为处理零资源翻译的场景,常用的步骤包含两个部分:
(1)双语对齐,使模型能对齐两种语言:
a.双语词嵌入
b.降噪自编码器
c.无监督统计机器翻译
d.语言模型预训练
(2)翻译提升,通过迭代学习提升翻译质量:
a.迭代回译,见2.2
b.过滤低质量的伪数据
c.Loss种加正则,防止训练时遗忘双语嵌入
d.同时用统计、神经机器翻译模型进行回译
2.4语言模型预训练
预训练语言模型能提升对语言的理解和生成能力,而NMT同时需要这两种能力,按是否联合训练编码器和解码器分为两类:
(1)分离训练:如XLM
(2)联合训练:如MASS,Bart,T5
2.5利用相似语料
相似语料即涉及相同实体的不同语言单语语料,可以从中挖掘隐含的平行语料。如LASER。
2.6利用双语词典增强
(1)用于稀有词翻译
(2)逐词翻译
(3)基于词典,缩小源语言和目标语言之间嵌入空间的差距
2.7 小结
以上方法可以组合使用,如回译和联合训练
3. 利用辅助语言

3.1 多语言训练:
低资源语言对与其他语言对在一个模型中联合训练
优点:
(1)较训练多个模型,多语言训练显著降低训练时间,且容易维护
(2)低资源语言可以受益于富资源语言
(3)多语言模型有潜力做到零资源翻译
相关工作可被分为:
(1)参数共享(不共享、全部共享、部分共享)
(2)针对低资源语言的设计
a.辅助语言选择,尽量选择同一语系的富资源语言
b.训练样本平衡,用基于温度的方法平衡富、低资源语言,使得模型不再偏好富资源语言
c.辅助语言词重排序:预先对辅助语言重排词的顺序再进行翻译
d.辅助语言的单语数据:用回译、跨语言预训练、元学习、无监督等方法提升低资源语言模型
(3)零资源翻译
假设模型学过x和英文的双向翻译,y和英文的双向翻译,即使模型没见过x和y的平行语料,模型也能进行x和y的双向翻译。
3.2 迁移学习:
即先训练通常包含富资源语言对的父母NMT模型,然后微调低资源语言对。
共享词汇表不适用于将预先训练的父模型迁移到词汇表中有未见过文字的语言。为了解决这一问题,Kim等人提出学习未见语言和双语父模型的嵌入的跨语言线性映射。
3.3 枢轴翻译:
选择一种或多种枢轴语言作为源语言和目标语言之间的桥梁,利用源-枢轴和枢轴-目标数据来帮助源目标语言的翻译。有如下三种方式:
(1)直接结合源-枢轴和枢轴-目标模型,逐个翻译
(2)使用源-枢轴和枢轴-目标模型生成伪数据,用来训练源-目标模型
(3)使用源-枢轴和枢轴-目标模型的参数,进行从源到目标语言的迁移学习
4.利用多模态数据
目前,图像-文本并行数据在NMT上的应用是有限的,因为这种图像-文本数据对于低资源语言来说总是很难收集。建立新的图像-文本数据集的一个可能的数据源是网站上的图像和相应的标题。
对于只有语音而没有文本的语言,可以利用语音数据来进行翻译。
5.数据集
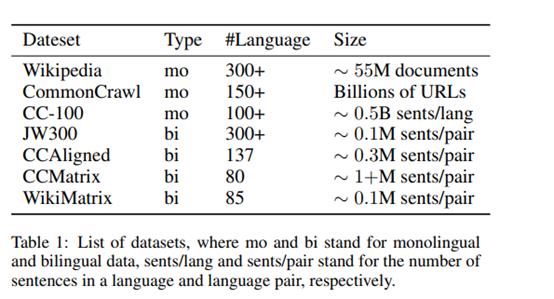
个人总结
接下来我可以针对迁移学习的词表映射、多语言模型的部分参数共享、对偶学习、元学习这几个方面继续研读。
参考
以上是关于恒源云_语音识别与语义处理领域之低资源机器翻译综述的主要内容,如果未能解决你的问题,请参考以下文章
恒源云(GPUSHARE)_语音识别与语义处理领域之[机器翻译] 21.7 mRASP2