循环神经网络综述-语音识别与自然语言处理的利器
Posted 图灵人工智能
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了循环神经网络综述-语音识别与自然语言处理的利器相关的知识,希望对你有一定的参考价值。
导言
循环神经网络是一种具有记忆功能的神经网络,适合序列数据的建模。它在语音识别、自然语言处理等领域取得了成功。是除卷积神经网络之外深度学习中最常用的一种网络结构。在本文中,将和大家一起回顾循环神经网络的发展历程与在各个领域的应用。
序列数据建模
全连接网络和卷积网络在运行时每次接收的都是独立的输入数据,没有记忆能力。在有些应用中需要神经网络具有记忆功能,典型的是时间序列预测问题,时间序列可以抽象的表示为一个向量序列:

这里的下标表示时刻,神经网络每个时刻接收一个向量输入。不同时刻的向量之间存在关系,每个时刻的向量与更早时刻的向量相关。例如,在说话时当前要说的词和之前所说的词之间相关,依赖于上下文语境。我们需要根据输入序列来产生输出向量。这类问题称为序列预测问题,输入序列的长度可能不固定。
语音识别与自然语言处理的问题是这类序列预测问题的典型代表。前者的输入是一个时间序列的语音信号;后者是文字序列。下面我们用一个实际例子来说明序列预测问题。假设神经网络要用来完成汉语填空,考虑下面这个句子:
现在已经半夜12点了,
我非常困,想回家__。
最佳答案是“睡觉”或者“休息”,这个答案需要根据上下文理解得到。在这里,神经网络每次的输入为一个词,最后要填出这个空,这需要网络能够理解语义,并记住之前输入的信息即语句上下文。这里需要神经网络具有记忆功能,能够根据之前的输入词序列计出当前使用哪个词的概率最大。如何设计一个神经网络满足上面的要求?答案就是我们接下来要介绍的循环神经网络。
循环层的工作原理
循环神经网络(简称RNN)[1]会记住网络在上一个时刻的输出值,并将该值用于当前时刻输出值的生成,这由循环层实现。RNN的输入为前面介绍的向量序列,每个时刻接收一个输入,网络会产生一个输出,而这个输出是由之前的序列共同作用决定的。假设 t 时刻 循环层的状态值为ht,它由上一时刻的状态值以及当前时刻的输入值共同决定,即:
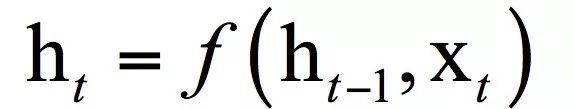
这是一个递推关系式,现在的问题是确定这个表达式的具体形式,即将上一时刻的状态值与当前时刻的输入值整合到一起。在全连接神经网络中,神经元的输出值是对输入值进行加权,然后用激活函数进行作用,得到输出。在这里,我们可以对上一时刻的状态值,当前时刻的输入值进行类似的处理,即将它们分别都乘以权重矩阵,然后整合起来。整合可以采用加法,也可以采用乘法或者更复杂的运算,最简单的是加法,乘法在数值上不稳定,多次乘积之后数为变得非常大或者非常小。显然,这里需要两个权重矩阵,分别作用于上一时刻状态值,当前时刻的输入值,由此得到下面的递推关系式:
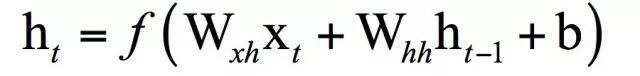
其中W为权重矩阵,b为偏置向量。和全连接神经网络相比,这里只是多了一个项:
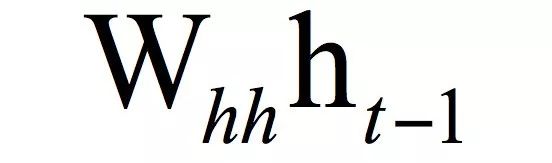
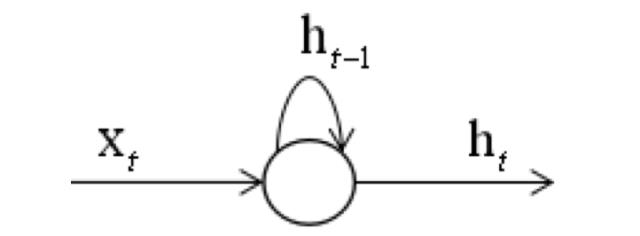
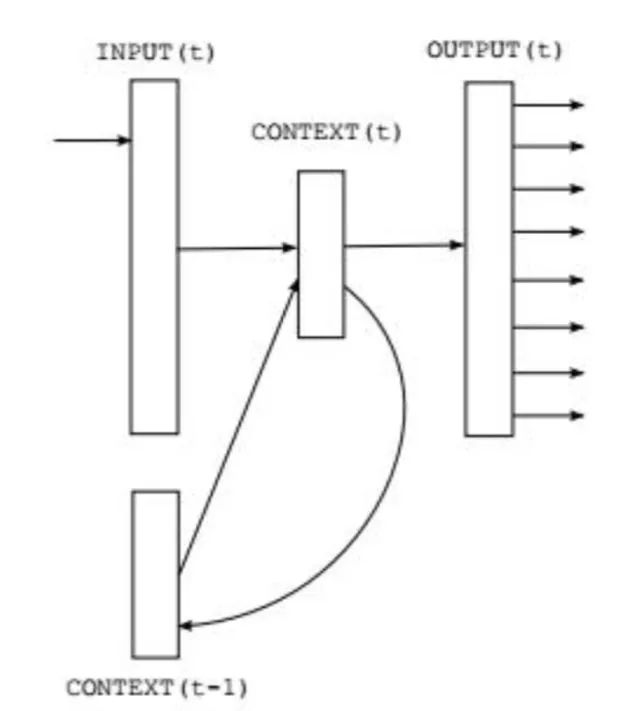
在上图中ht-1和xt共同决定ht,ht-1体现了记忆功能,而它的值又是由ht-2和xt-1决定。因此ht的值实际上是由x11,...,xt决定的,它记住了之前完整的序列信息。需要强调的是,权重矩阵Whh并不会随着时间变化,而是固定的,即在每个时刻进行计算时使用的是同一个矩阵。这样做的好处一方面是减少了模型参数,另一方面也记住了之前的信息。
如果把每个时刻的输入和输出值按照时间线展开,如下图所示:
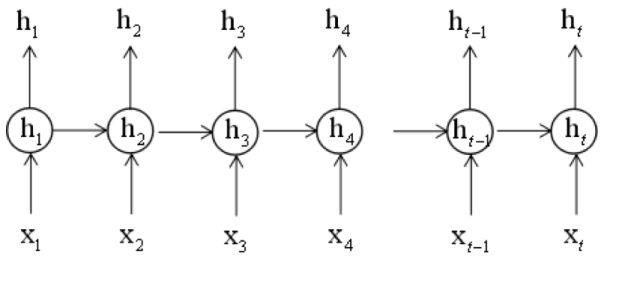
网络结构
最简单的循环神经网络由一个输入层,一个循环层,一个输出层组成。输出层接收循环层的输出值作为输入并产生输出,它不具有记忆功能。输出层实现的变换为:
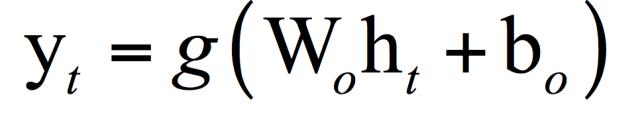
函数g的类型根据任务而定,对于分类任务一般选用softmax函数,输出各个类的概率。结合循环层和输出层,循环神经网络完成的变换为:
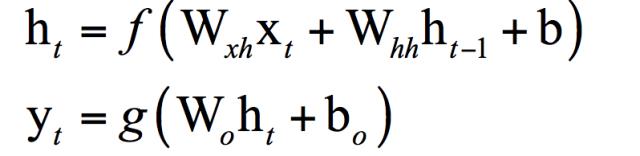
在这里只使用了一个循环层和一个输出层,实际使用时可以有多个循环层,即深度循环神经网络,在下一节中会详细介绍。
深层网络
上面我们介绍的循环神经网络只有一个输入层,一个循环层和一个输出层,这是一个浅层网络。和全连接网络以及卷积网络一样,我们可以把它推广到任意多个隐含层的情况,得到深度循环神经网络[11]。
这里有3种方案,第一种方案为Deep Input-to-Hidden Function,在循环层之前加入多个普通的前馈层,将输入向量进行多层映射之后再送入循环层进行处理。
第二种方案是Deep Hidden -to-Hidden Transition,它使用多个循环层,这和前馈型神经网络类似,唯一不同的是计算隐含层输出的时候需要利用本隐含层在上一个时刻的输出值。
第三种方案是Deep Hidden-to-Output Function,它在循环层到输出层之间加入多前馈层,这和第一种情况类似。
由于循环层一般用tanh作为激活函数,层次过多之后会导致梯度消失问题,和残差网络类似,可以采用跨层连接的方案。在语音识别、自然语言处理问题上,我们会看到深层循环神经网络的应用,实验结果证明深层网络比浅层网络有更好的精度。
训练算法
挑战与改进措施
循环神经网络与其他类型的神经网络共同要面对的是梯度消失问题,对此出现了一些解决方案,如LSTM等。相比卷积神经网络,循环神经网络在结构上的改进相对要少一些。
梯度消失问题
和前馈型神经网络一样,循环神经网络在进行梯度反向传播时也面临着梯度消失和梯度爆炸问题,只不过这种消逝问题表现在时间轴上,即如果输入序列的长度很长,我们很难进行有效的梯度更新。对这一问题的解释和理论分析,会在以后的文章中给出。文献[5]对循环神经网络难以训练的问题进行了分析。进一步的,文献[6]对这一问题作出了更深的解释,并给出了一种解决方案。
LSTM
长短期记忆模型(long short time memory,简称LSTM)由Schmidhuber等人在1997年提出[7],与高速公路网络(highway networks)有异曲同工之妙。它对循环层进行改造,具体方法是使用输入门、遗忘门、输出门3个元件,通过另外一种方式由ht-1计算ht。LSTM的基本单元称为记忆单元,它记住了上一个时刻的状态值。记忆单元在t时刻维持一个记忆值ct,循环层状态的输出值计算公式为:

即输出门与状态值的乘积,在这里是向量对应元素相乘。其中ot为输出门,是一个向 量,按照如下公式计算:
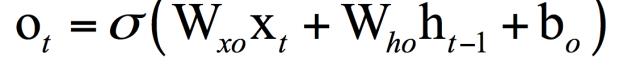
其中![]() 为sigmoid函数,后面公式中含义相同。输出门控制着记忆单元中存储的记忆值有多大比例可以被输出。使用sigmoid函数这是因为它的值域是(0,1),这样ot的所有分量的取值范围都在0和1之间,它们分别与另外一个向量的分量相乘,可以控制另外一个向量的输出比例。分别为输出门的权重矩阵和偏置向量。Wxo , Who , bo是输出门的权重矩阵和偏置项,这里参数通过训练得到。
为sigmoid函数,后面公式中含义相同。输出门控制着记忆单元中存储的记忆值有多大比例可以被输出。使用sigmoid函数这是因为它的值域是(0,1),这样ot的所有分量的取值范围都在0和1之间,它们分别与另外一个向量的分量相乘,可以控制另外一个向量的输出比例。分别为输出门的权重矩阵和偏置向量。Wxo , Who , bo是输出门的权重矩阵和偏置项,这里参数通过训练得到。
记忆值ct是循环层神经元记住的上一个时刻的状态值,随着时间进行加权更新,它的计算公式为:
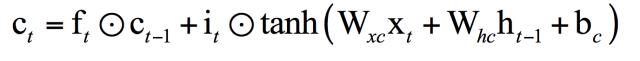
其中ft是遗忘门,ct-1是记忆单元在上一时刻的值,遗忘门决定了记忆单元上一时刻的值有多少会被传到当前时刻。上式表明,记忆单元当前值是上时刻值与当前输入值的加权和,记忆值只是个中间值。遗忘门的计算公式为:
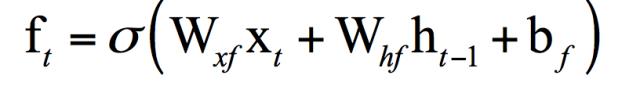
这里也使用了sigmoid函数,Wxf ,Whf ,bf 分别为遗忘门的权重矩阵和偏置向量。
it 是输入门,控制着当前时刻的输入有多少可以进入记忆单元,其计算公式为:
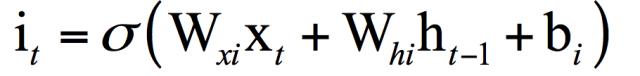
其中Wxi , Whi , bi 分别为输入门的权重矩阵和偏置向量。这3个门的计算公式都是一样的,分别使用了自己的权重矩阵和偏置向量,这3个值的计算都用到了xt 和 ht -1,它们起到了信息的流量控制作用。
隐含层的状态值由遗忘门,记忆单元上一时刻的值,以及输入门,输出门共同决定。除掉3个门之外,真正决定ht的只有xt和ht-1。总结起来,LSTM的计算思路为:
输入门作用于输入信息,遗忘门作用于之前的记忆信息,二者加权和,得到汇总信息;最后通过输出门决定输出信息。
所有的权重矩阵,偏置向量都通过训练得到,这和普通的循环神经网络没有区别,根据 BPTT 算法,我们可以得到这些参数的梯度值,在这里不详细介绍。
GRU
门控循环单元[8](Gated Recurrent Units,简称 GRU)是解决循环神经网络梯度消失的 另外一种方法,它也是通过门来控制信息的流动。和LSTM不同的是,它只使用了两个门,把LSTM的输入门和遗忘门合并成更新门。在这里我们不详细介绍计算公式,感兴趣的读者可以阅读参考文献。
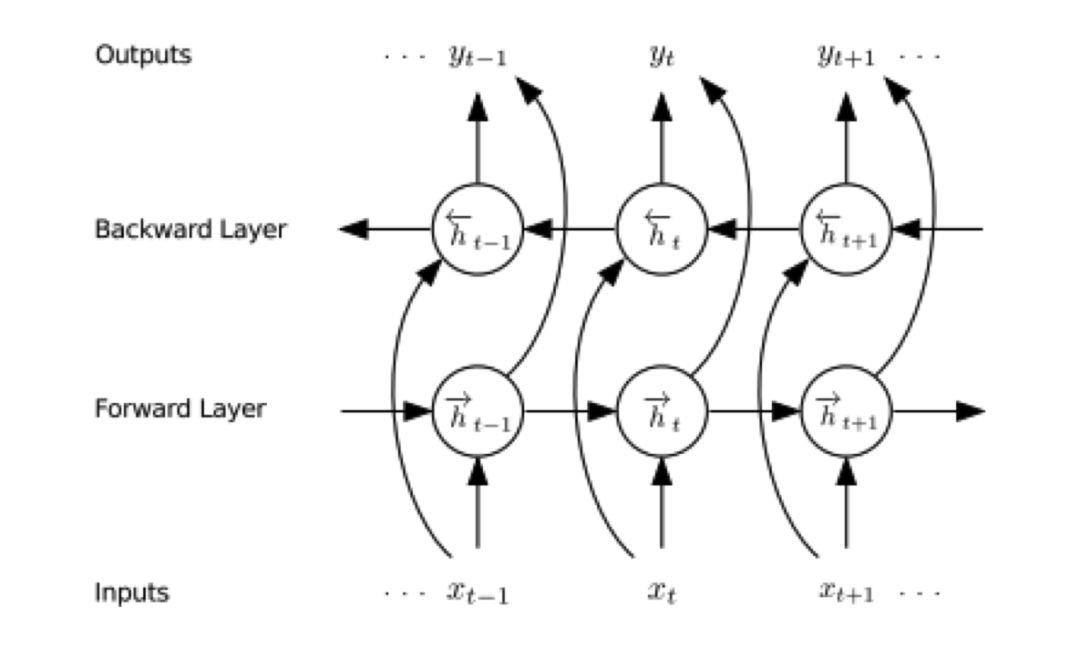
双向网络
前面介绍的循环神经网络是单向的,每一个时刻的输出依赖于比它早的时刻的输入值,这没有利用未来时刻的信息,对于有些问题,当前时刻的输出不仅与过去时刻的数据有关,还与将来时刻的数据有关,为此Schuster等人设计了双向循环神经网络[9],它用两个不同的循环层分别从正向和反向对数据进行扫描。正向传播时的流程为:
1.循环,对t=1,...T
用正向循环层进行正向传播,记住每一个时刻的输出值
结束循环
2.循环,对t=T,...1
用反向循环层进行正向传播,记住每一个时刻的输出值
结束循环
3.循环,对所有的t,可以按照任意顺序进行计算
用正向和反向循环层的输出值作为输出层的输入,计算最终的输出值
结束循环
下面用一个简单的例子来说明,假设双向循环神经网络的输入序列为x1,...,x4。首先用第一个循环层进行正向迭代,得到隐含层的正向输出序列:
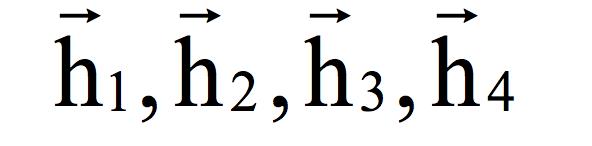
在这里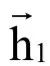 由x1决定,
由x1决定,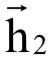 由x1,x2决定,
由x1,x2决定,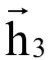 由x1 , . . . , x3决定,
由x1 , . . . , x3决定,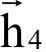 由x1 , . . . , x4 决定。即每个时刻的状态值由到当前时刻为止的所有输入值序列决定,这里利用的是序列的过去信息。然后用第二个循环层进行反向迭代,输入顺序是x4 , ..., x1,得到隐含层的反向输出序列:
由x1 , . . . , x4 决定。即每个时刻的状态值由到当前时刻为止的所有输入值序列决定,这里利用的是序列的过去信息。然后用第二个循环层进行反向迭代,输入顺序是x4 , ..., x1,得到隐含层的反向输出序列:
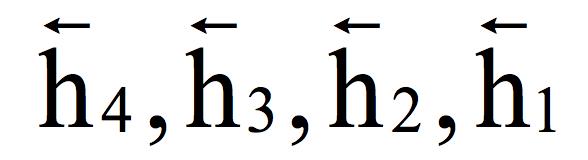
在这里,由x4决定,由x4, x3决定,由x4,...,x2 决定,由x4,...,x1决定。即每个时刻的状态值由它之后的输入序列决定,这里利用的是序列未来的信息。
然后将每个时刻的隐含层正向输出序列和反向输出序列合并起来:
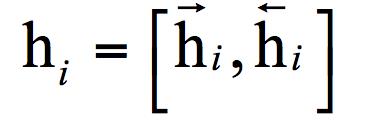
送入神经网络中后面的层进行处理,此时,各个时刻的处理顺序是随意的,可以不用按照输入序列的时间顺序。
多维网络
循环神经网络的另外一个改进是拓展到多维的情况,得到多维网络,限于篇幅,在这里不详细介绍,感兴趣的读者可以阅读参考文献[18]。
序列预测问题
序列预测问题是一类问题的抽象,它的输入是一个序列,输出也是一个序列,而且输入和输出序列的长度是不固定的。这是循环神经网络最擅长处理的问题之一。
序列标注问题
序列标注问题[12]是一个抽象的概念,它泛指将一个序列数据映射成另外一个序列的任务,其本质是根据上下文信息对序列每个时刻的输入值进行预测。典型的序列标注问题包括语音识别,机器翻译,词性标注等。对于语音识别问题,输入数据是语音信号序列,输出是离散的文字序列;对于机器翻译问题,输入是一种语言的语句,即单词序列,输出是另外一种语言的单词序列;对于词性标注问题,输入是一句话的单词序列,输出是每个单词的词性,如名词、动词。
与普通的模式分类问题相比,序列标注问题最显著的区别是输入序列数据的数据点之间存在相关性,输出的序列数据的数据点之间也存在相关性。例如,对于语音识别问题,一句话的语音信号在各个时刻显然是相关的;识别的结果单词序列组成,各个单词之间显然也具有相关性,它们必须符合词法和语法规则。
序列标注问题的一个困难之处在于输入序列和输出序列之间的对齐关系是未知的。以语音识别问题为例,输入语音信号哪个时间段内的数据对应哪个单词的对应关系在进行识别之前并不知道,我们不知道一个单词在语音信号中的起始时刻和终止时刻。
循环神经网络因为具有记忆功能,因此特别适合于序列标注任务。但是循环神经网络在处理这类任务时面临几个问题。第一个问题是标准的循环神经网络是单向的,但有些问题不仅需要序列过去时刻的信息,还需要未来时刻的信息。例如我们要理解一个句子中的某个词,它不仅与句子中前面的词有关,还和后门的词有关,即所谓的上下文语境。解决这个问题的方法是上面介绍的双向循环神经网络。
第二个问题是循环神经网络的输出序列和输入序列之间要对齐。即每一个时刻的输出值与输入值对应,而有些问题中输入序列和输出序列的对应关系是未知的。典型的是语音识别问题,这在前面已经介绍。解决这个问题的经典方法是连接主义时序分类,即Connectionist Temporal Classification,简称CTC。
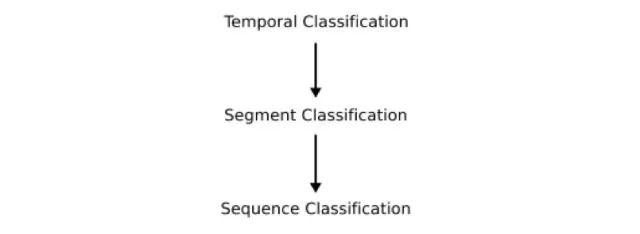
根据输入序列和输出序列的对应关系,我们可以将序列标注问题分为三类。第一类为序列分类问题,它给输入序列赋予一个类别标签,即输出序列只有一个值,因此输出序列的长度为1。第二类问题为段分类问题,输入序列被预先分成了几段,每段为一个序列,为每一段赋予一个标签值,显然,第一种问题是第二种问题的一个特例。第三类问题为时序分类问题,对于这类问题,输入序列和输出序列的任何对齐方式都是允许的。显然,第二类问题是第三类问题的一个特例,因此这3类问题是层层包含关系。三类问题的关系如下图所示:
 CTC
CTC
CTC
循环神经网络虽然可以解决序列数据的预测问题,但它要求输入的数据是每个时刻分割好并且计算得到的固定长度的特征向量。对于有些问题,对原始的序列数据进行分割并计算特征向量存在困难,典型的是语音识别。原始的声音信号我们很难先进行准确的分割,得到每个发音单元所对应的准确的时间区间。解决这类问题的一种典型方法是CTC技术。
CTC[13]是一种解决从未分段的序列数据预测标签值的通用方法,在这里不要求将输入数据进行分割之后再送入循环神经网络中预测。2014年Graves等人将这一方法用于语音识别问题[14],通过和循环神经网络整合来完成语音识别任务。CTC解决问题的关键思路是引入了空白符以及消除重复,以及用一个映射函数将循环神经网络的原始输出序列映射为最终需要的标签序列。
假设训练样本集为S,训练样本服从概率分布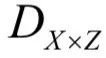 。输入空间是输入序列的集合,定义为:
。输入空间是输入序列的集合,定义为:
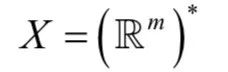
这是所有m维实向量序列的集合。目标空间是我们需要的预测结果序列的集合,定义为:
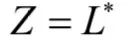
这是建立在包含有限个字母集L之上的标签序列的集合,我们将L*中的元素称为标签序列。对于语音识别,L是文字字典,L*是识别出来的句子。训练样本集中的每个样本是一个序列对(x,z)。其中输入序列为:
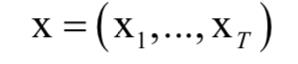
目标序列为:
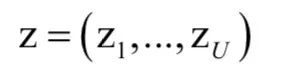
这有一个约束条件,目标序列的长度不大于输入序列的长度,即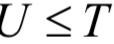 。由于输出序列的长度与输入序列的长度可能不相等,因此无法用先验知识将它们对齐,即让输出序列的某些元素和输入序列的某一个元素对应起来。我们的目标是用训练样本集训练一个时序分类器:
。由于输出序列的长度与输入序列的长度可能不相等,因此无法用先验知识将它们对齐,即让输出序列的某些元素和输入序列的某一个元素对应起来。我们的目标是用训练样本集训练一个时序分类器:
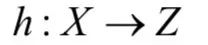
然后用它对新的输入序列进行分类。分类时,要让定义的某种误差最小化。要使用循环神经网络对时序数据进行分类,其中关键的步是将循环神经网络的输出值转换成某一个序列的条件概率值。这样,我们通过寻找使得这个条件概率最大化的输出序列来完成对输入序列的分类。
CTC网络的输出层为softmax层,如果标签字母集中的字母个数为|L|,则这一层有|L|+1个神经元,其中前|L|个神经元表示在某一个时刻输出标签为每一个标签字母的概率,最后一个神经元的输出值为输出标签值为空的概率,即没有标签输出。这样,softmax层在各个时刻的输出值合并在一起,定义了各种可能的输出标签序列和输入序列进行对齐的方式的概率。任何一个标签序列的概率值可以通过对其所有不同的对齐方式的概率进行求和得到。
假设输入序列的长度为T,循环神经网络的输入数据为m维,输出向量为n维,权重向量为w,它实现了如下的映射:
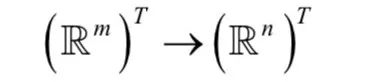
我们将网络的映射写成y=Nw (x),其中y是输出序列。在t时刻,网络第k个输出单元的值为ykt。在这里ykt可以将解释为在t时刻观测标签k的概率。这个概率值定义了集合L'T中长度为T的序列所服从的概率分布,其中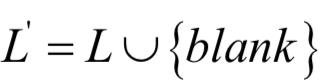 ,其中blank为空白符号,即:
,其中blank为空白符号,即:
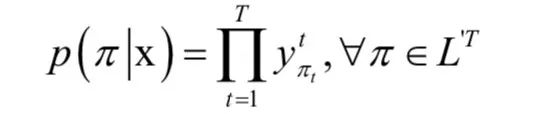
在这里我们将集合L'T中的元素称为路径(path),记为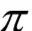 。接下来,我们定义一个多对一的映射,将神经网络的输出序列映射为最终需要的标签值序列:
。接下来,我们定义一个多对一的映射,将神经网络的输出序列映射为最终需要的标签值序列:
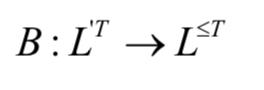
其中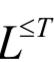 是所有可能的输出标签序列的集合,即由字母集合中的字母组成的长度小于等于T的序列的集合。从神经网络的输出序列LT得到目标标签序列的做法是消除空白符和连续的重复标签值。下面来看B函数作用于一个序列的例子:
是所有可能的输出标签序列的集合,即由字母集合中的字母组成的长度小于等于T的序列的集合。从神经网络的输出序列LT得到目标标签序列的做法是消除空白符和连续的重复标签值。下面来看B函数作用于一个序列的例子:
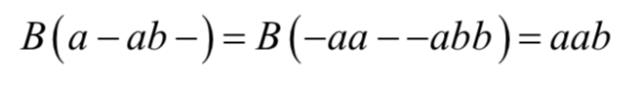
其中,-为空白符号。由于与一个标签序列对应的路径不止一个,因此目标标签序列的条件概率应该等于能得到它的所有路径的条件概率之和。我们借助映射B来定义一个标签序列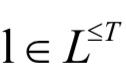 的条件概率,它等于所有映射后为l的路径
的条件概率,它等于所有映射后为l的路径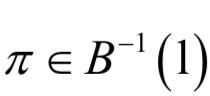 的概率之和:
的概率之和:
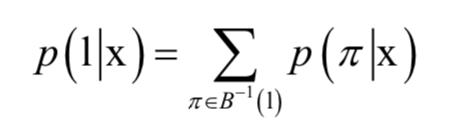
下面用一个简单的例子进行说明。如果标签字母集合为{a,b,c},路径的序列长度为4,标签序列的长度为3。则标签序列 l = abc 所对应的所有可能路径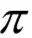 为:
为:
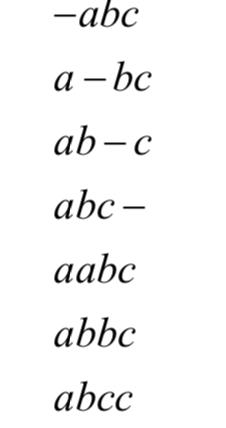
总共有7条路径和一个标签序列对应。基于上面的定义,CTC分类器的分类结果是给定输入序列,寻找上面的条件概率最大的那个输出序列:
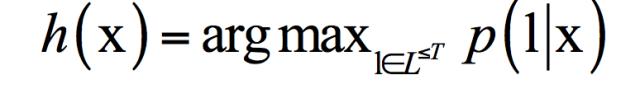
在这里,需要解决如何找到概率最大的输出序列的问题,而前面定义的框架只是计算给定的输出序列的条件概率。采用和隐马尔可夫模型类似的概念,我们称这一过程为解码,它们都是要得到概率最大的序列值。直接暴力枚举计算量太大,这里采用了动态规划建立递推公式进行计算,限于篇幅,我们不能详细介绍,在后面的文章中,将对此展开讲解。
seq2seq
对有些问题,输入序列的长度和输出序列不一定相等,而且我们事先并不知道输出序列的长度,典型的是机器翻译问题。以机器翻译为例,将一种语言的句子翻译成另外一种语言之后,句子的长度即包括的单词数量一般是不相等的。以英译汉为例,英文句子“what's your name”是3个单词组成的序列,翻译成中文为“你叫什么名字”,由4个汉字词组成。标准的RNN没法处理这种输入序列和输出序列长度不相等的情况,解决这类问题的一种方法是序列到序列学习技术。
Sequence to Sequence Learning,即序列到序列的学习[15],简称seq2seq,是用循环神经网络构建的一种框架,它能实现从一个序列到另外一个序列的映射,两个序列的长度可以不相等。seq2seq框架包括两部分,分别称为编码器和解码器,它们都是循环神经网络。这里要完成的是从一个序列到另外一个序列的预测:
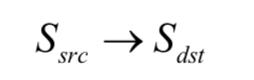
前者是源序列,后者是目标序列,两个序列的长度可能不相等。
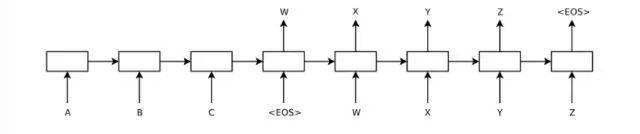
用于编码器的循环神经网络接受输入序列x1,..., xT,最后时刻T产生的隐含层状态值hT作为序列的编码值,它包含了时刻1到T输入序列的所有信息,在这里我们将其简写为v,这是一个固定长度的向量。用于解码的RNN的初始隐含状态为v,它可以计算目标序列y1,...,yT' 的条件概率:
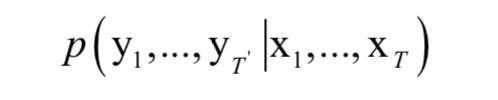
根据训练神经网络的输出值之间的关系,这个概率可以进一步写成:
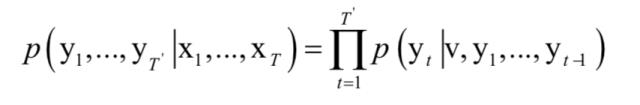
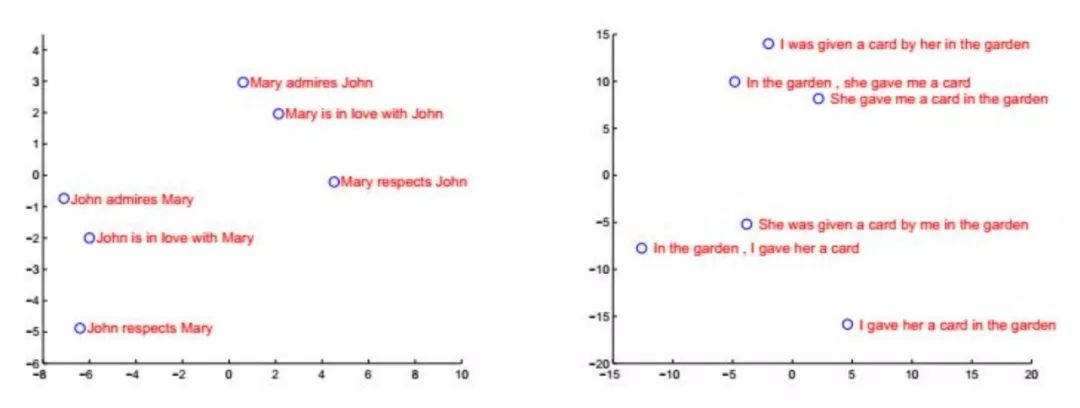
如果在输出层使用softmax函数映射,就可以到到上面每一个时刻的概率。实现时编码器和解码器同时训练,最大化上面的条件概率。在这里训练样本是成对的序列(A,B),训练的目标是让序列A编码之后解码得到序列B的概率最大,即最大化如下的条件对数似然函数:
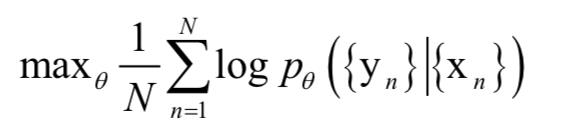
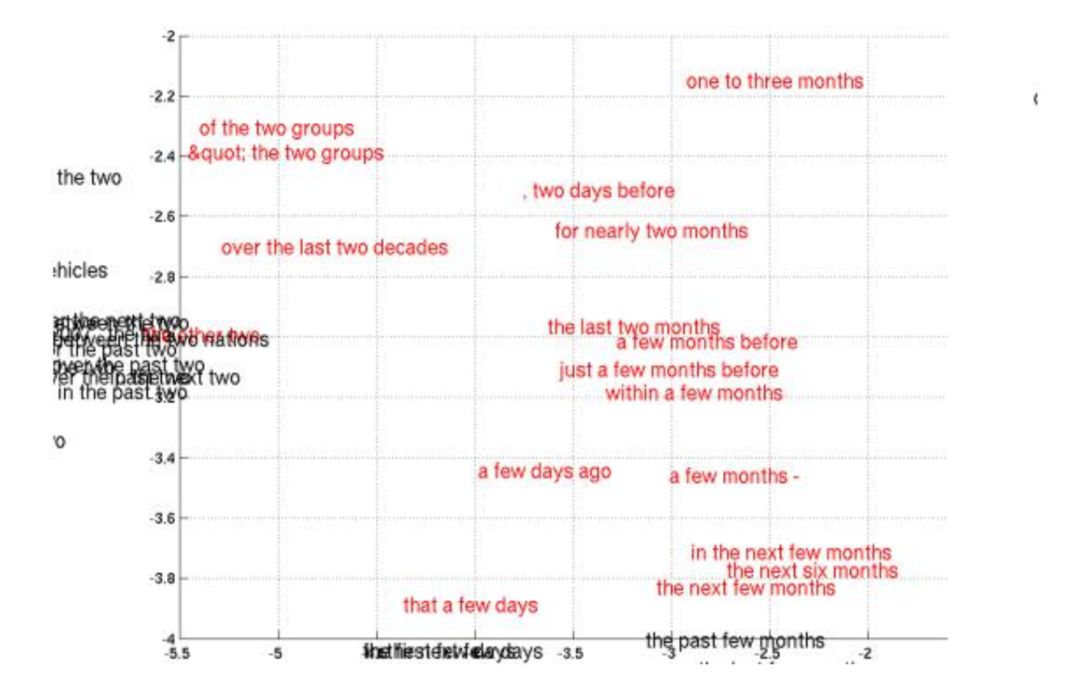
其中N是训练样本数,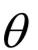 为要求解的参数。输入序列和对应的输出序列组合在一起为一个训练样本。下图是编码器对句子编码后的结果,在这里投影到2维平面上了:
为要求解的参数。输入序列和对应的输出序列组合在一起为一个训练样本。下图是编码器对句子编码后的结果,在这里投影到2维平面上了:
seq2seq 框架有两种用法。第一种用法是为输入输出序列对打分,即计算条件概率值:
第二种用法是根据输入序列生成对应的输出序列,由于seq2seq只有计算条件概率的功能,因此需要采用搜索技术得到条件概率最大的输出序列,可以使用集束搜索(beam search) 技术。机器翻译问题采用的是第二种用法。seq2seq框架提供的是一种预测输出序列对输入序列的条件概率的手段。
集束搜索通过在每一步对上一步的结果进行扩展来生成最优解。在每一步,选择一个词添加到之前的序列中,形成新的序列,并只保留概率最大的k个序列。在这里,k为人工设定的参数,称为集束宽度。
下面用一个例子来说明集束搜索的原理。假设词典大小为3,包含的词为{a,b,c}。如果集束搜索的搜索宽度设置为2,则在选择第一个词的时候,寻找概率最大的两个词,假设为{a,b}。接下来,生成下一个词,对所有可能的组合{aa,ab,ac,ba,bb,bc},保留概率最大的2个,假设为{ab,bb}。接下来,在这个基础上再选择第三个词,以此类推。最终得到概率最大的完整序列作为输出。
典型应用
循环神经网络被成功应用于各类时间序列数据的分析和建模,包括语音识别,自然语言处理,机器视觉中的目标跟踪、视频动作识别等。
语音识别
深度学习最早应用于语音识别问题时的作用是替代GMM-HMM框架中的高斯混合模型,负责声学模型的建模,即DNN-HMM结构。在这种结构里,深层神经网络负责计算音频帧属于某一声学状态的概率或者是提取出声音的特征,其余的部分和GMM-HMM结构相同。
语音识别的困难之处在于输入语音信号序列中每个发音单元的起始位置和终止位置是未知的,即不知道输出序列和输入序列之间的对齐关系,这属于前面介绍的时序分类问题。
深度学习技术在语音识别里一个有影响力的成果是循环神经网络和CTC的结合,和卷积神经网络、自动编码器等相比,循环神经网络具有可以接受不固定长度的序列数据作为输入的优势,而且具有记忆功能。文献[14]将CTC技术用于语音识别问题。语音识别中,识别出的字符序列或者音素序列长度一定不大于输入的特征帧序列。CTC在标注符号集中加上空白符号blank,然后利用循环神经网络进行标注,再把blank符号和预测出的重复符号消除。下图是 CTC 的原理:
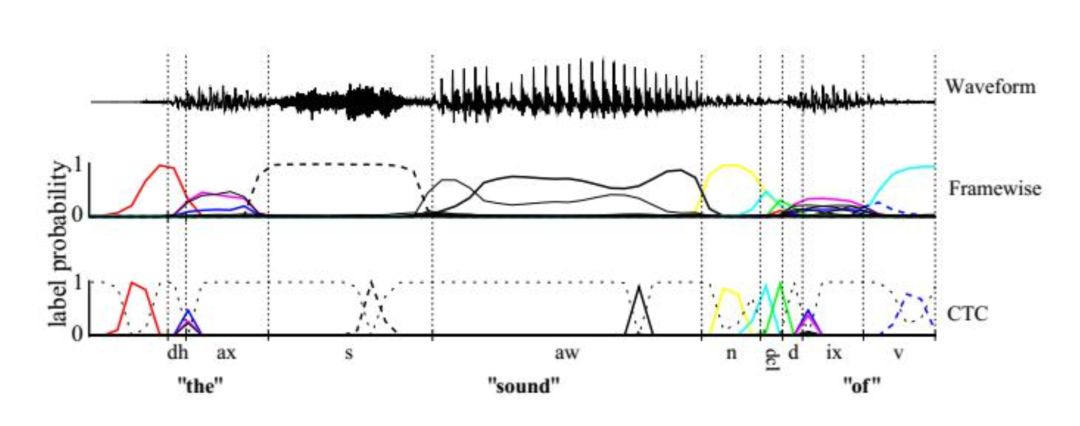
假设x为语音输入序列,l 为识别出来的文字序列,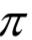 为循环神经网络的输出。可能有多个连续帧对应一个文字,有些帧可能没有任何输出,按照CTC的原理,用多对一的函数B把输出序列中重复的字符进行合并,形成一个唯一的序列:
为循环神经网络的输出。可能有多个连续帧对应一个文字,有些帧可能没有任何输出,按照CTC的原理,用多对一的函数B把输出序列中重复的字符进行合并,形成一个唯一的序列:
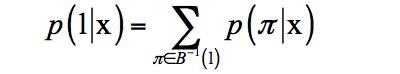
其中l为文字序列,是带有冗余的循环神经网络输出。映射函数B将神经网络的输出序列映射成文字序列l。分类器的输出为对输入序列最可能的标签值:
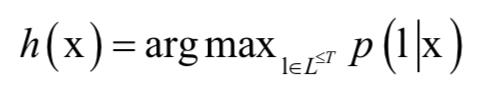
解码时采用的是前缀搜索技术。CTC在这里起到了对齐的作用,最显著的优势是实现了端到端的学习,无需人工对语音序列进行分割,这样做还带来了精度上的提升。
在实现时循环神经网络采用了双向 LSTM 网络,简称 BLSTM。训练样本集的音频数据 被切分成 10 毫秒的帧,其中相邻帧之间有 5 毫秒的重叠,使用 MFCC 特征作为循环神经网 络的输入向量。原始音频信号被转换成一个 MFCC 向量序列。特征向量为 26 维,包括了对 数能量和一阶导数值。向量的每一个分量都进行了归一化。在解码时,使用最优路径和前缀 搜索解码,解码的结果就是语音识别要得到的标记序列。
文献[14]中的循环神经网络是一个浅层的网络,文献[17]提出了一种用深度双向LSTM网络和CTC框架进行语音识别的方法,这种方法主要的改进是使用了多个双向LSTM层,称为深度LSTM网络。对于多层RNN网络,计算公式为:
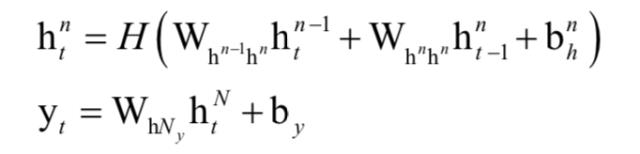
双向深度循环神经网络采用两套隐含层,分别正向、反向对输入序列进行处理,并把最后一个隐含层的输出值合并之后送到输出层,计算公式为:
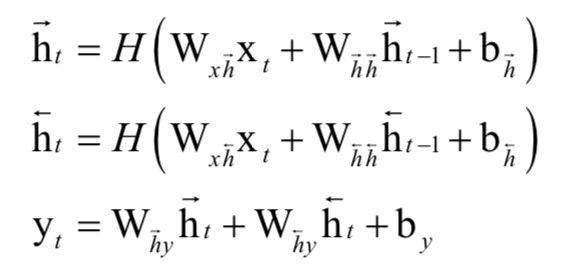
对于深度双向LSTM网络原理类似,只是把隐含层的变换换成LSTM结构的公式,在这里不再详细介绍。
假设输入的声学序列数据为x,输出音素序列为y。第一步是给定输入序列和所有可能的输出序列,用循环神经网络计算出条件概率值 p(y|x)。在训练时的样本为输入序列以及对应的输出序列。训练时的损失函数为对数似然函数:
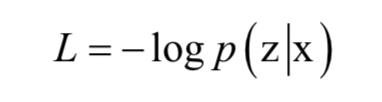
这里使用CTC来对序列z进行分类,对于一段输入的语音数据,分类的结果是一个音素序列。假设有k个音素,再加上一个空白符,是一个k+1类的分类问题。循环神经网络的最后一层为softmax层,输出k+1个概率值,在时刻t输出值为p(y|t)。
神经网络在每一个时刻确定是输出一个音素,还是不输出即输出空白符。将所有时刻的输出值合并在一起,得到了一个输入和输出序列的对齐方案。CTC对所有的对齐方式进行概率求和得到p(z|x)。
在使用CTC时,循环神经网络被设计成双向的,这样每个时刻的概率输出值为:
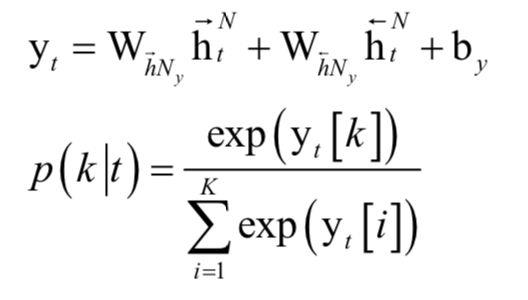
其中N是隐含层的数量,y是神经网络的输出向量。上式用softmax映射根据神经网络的输出向量得到每一个音素的概率值。
前面介绍的CTC框架输入是声学数据,输出是音素数据,只是一个声学模型。接下来还需要将音素序列转化成最终的文字序列作为识别结果,需要一个语言模型。在这里采用RNN transducer,一种集成了声学建模CTC和语言模型RNN的方法,后者负责将音素转化成文字,二者联合起来训练得到模型,我们称第一个网络为CTC网络,第二个网络为预测网络。
假设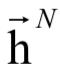 和
和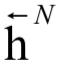 为CTC网络最后一个CTC最后一个隐含层的前向和后向输出序列,p为预测网络的隐含层输出序列。在每个时刻t,u为输出网络,它包含一个线性层,接受输入和,产生输出向量lt,另外还包含一个tanh隐含层,接受输入值lt和pu,产生输出值htu,最后将htu送入类的softmax层得到概率值p(k|t,u)。整个过程的计算公式为:
为CTC网络最后一个CTC最后一个隐含层的前向和后向输出序列,p为预测网络的隐含层输出序列。在每个时刻t,u为输出网络,它包含一个线性层,接受输入和,产生输出向量lt,另外还包含一个tanh隐含层,接受输入值lt和pu,产生输出值htu,最后将htu送入类的softmax层得到概率值p(k|t,u)。整个过程的计算公式为:
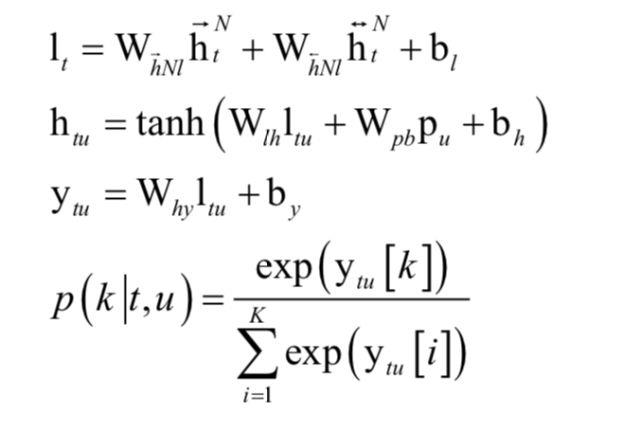
RNN transducer只是给出了任何一个输出序列相对于输入序列的条件概率值,还需要解码算法得到概率最大的输出序列。在这里使用了集束搜索算法,算法给出 n 个最优的候选结果,选择的依据是概率值p(k|t)。
整个系统的输入数据是对音频数据进行分帧后的编码向量,具体做法是对分帧后的音频数据进行傅里叶编码,然后40个傅里叶系数,加上能量,以及它们的一阶和二阶导数构成的向量,因此特征向量为123维。整个向量进行了归一化。在这里使用了61个音素,它们被映射为39个类。实验结果证明,更深的网络具有更高的准确率,双向LSTM比单向网络也有更高的精度。
文献[19]提出了一种融合了卷积神经网络和循环神经网络的英语与汉语普通话语音识别算法。这也是一种完全端到端的方法,所有人工工程的部分都用神经网络替代,可以处理各种情况,包括噪声、各种语言。
整个系统的输入为音频数据,使用20毫秒的窗口对原始音频数据分帧,然后计算对数谱,对功率进行归一化形成序列数据,送入神经网络中处理。首先是1D或者2D卷积层,然后是双向RNN,接下来全力连接的lookahead卷积层,最后是CTC分类器。整个模型也实现了端到端的训练。
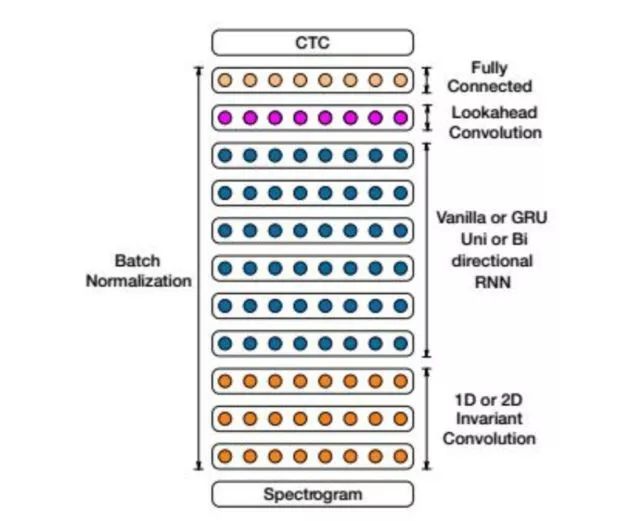
在每个时刻t神经网络的输出值为p(lt|x)。其中lt为字母表中的符号或者是空格。对于英文为:
{a,b,c,...,z,space,apotrohpe,blank}
其中space为词之间的边界。对于中文输出值为简化的汉字字符。识别时CTC模型和语言模型结合起来使用。解码时使用集束搜索算法寻找输出序列y,最大化如下函数:
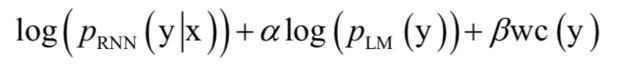
第一部分为RNN的损失函数,第二部分为语言模型的损失函数,第三部分对英文为单词数,对汉语为字数,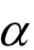 和
和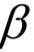 为人工设定的权重参数。
为人工设定的权重参数。
网络的最前端是卷积层,对输入的频谱向量执行1D或者2D卷积。实验结果证明2D卷积有更好的效果。
整个网络包含多个循环层,循环层还使用了批量归一化技术,它可以作用于前一层和本层上一时刻状态值的线性加权和,也可以只作用于前一层的输入值。
在所有循环层之前,加上了lookahead卷积层,计算公式为:
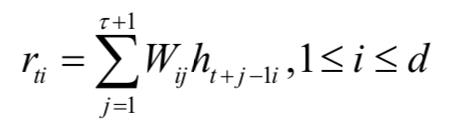
其中d为前一层的神经元个数,h是前一层的输出值,W是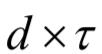 的权重矩阵,
的权重矩阵,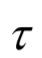 为时间步长。除了上面介绍的这些论文,用循环神经网络进行语音识别的文章还很多,限于篇幅, 不能一一列举,感兴趣的读者可以自己去阅读。
为时间步长。除了上面介绍的这些论文,用循环神经网络进行语音识别的文章还很多,限于篇幅, 不能一一列举,感兴趣的读者可以自己去阅读。
自然语言处理
自然语言处理的很多问题是时间序列问题,也是循环神经网络被广为应用的领域,下面介绍在一些典型问题上的使用情况。文献[30]为自然语言处理的很多问题提供了一个用循环神经网络解决的统一框架。这个框架用循环神经网络为句子序列进行编码,得到上下文语义信息,然后产生输出,如下图所示:
中文分词
汉语句子的词之间没有类似英文的空格,因此我们需要根据上下文来完成对句子的切分。分词的任务是把句子切分成词的序列,即完成我们通常所说的断句功能,它是解决自然语言处理很多问题的第一步,在搜索引擎等产品中都有应用。由于歧义和未登录词即词典里没有的新词的存在,中文分词并不是一件简单的任务。以下面的句子为例:
乒乓球拍卖了
显然这句话有歧义,对应于下面两种切分方案:
乒乓球 拍卖 了
乒乓球拍 卖 了
句子中出现词典里没有的词也会影响我们的正确切分,例如下面的句子:
李国庆节日在加班
在这里李国庆是一个人名字,而国庆节也是一个合法的词,正确的分词需要程序知道李国庆是人名。
最简单的分词算法是基于词典匹配,这又分为正向匹配,反向匹配和双向匹配3种策略。如果使用正向最大匹配,在分词时用词典中所有的词和句子中还未切分的部分进行匹配,如果存在多个匹配的词,则以长度最大的那个词作为匹配结果。反向最大匹配的做法和正向最大匹配类似,只是从后向前扫描句子。双向最大匹配则既进行正向最大匹配,也进行反向最大匹配,以切分的词较少的最为结果。显然,词典匹配无法有效的处理未登录词问题,对歧义切分也只能简单使用长度最大的词去匹配。词典匹配可以看作是解决分词问题的基于规则的方法。
作为改进,可以采用全切分路径技术。这种技术列出一个句子所有切分的方案,然后选择出最佳的方案。随着句子的增长,这种方法的计算量将呈指数级增长。
机器学习技术也被用于分词问题,采用序列标注的手段解决此问题。隐马尔可夫模型、条件随机场等方法为其中的代表。
分词可以看成是序列标注问题,将一个句子中的每个字标记成各种标签。系统的输入是字序列,输出是一个标注序列,因此这是一个标准的序列到序列的问题。在这里,标注序列有这样几种类型:
{B,N,E,S}
其中B表示当前字为一个词的开始,M表示当前字为一个词的中间位置,E表示当前字为一个词的结束位置,S表示单字词。以下面的句子为例:
我是中国人
其分词结果为:
我 是 中国人
标注序列为:
我/S 是/S 中/B 国/M 人/E
同样的,我们可以用循环神经网络进行序列标注从而完成分词任务,在这里网络的输出是句子中的每个字,输出是每个字的类别标签。得到类别标签之后,我们就完成了对句子的切分。
词性标注
词性标注(POS Tagging)是确定一个句子中各个词的类别,它是和分词密切相关的一个问题。典型的分类有名词,动词,形容词和副词等。给定句子中的词序列,词性标注的结果是每个词的词类别。这也可以看成是一个序列标注问题,即给定一个句子,预测出句子中每个词的类别:
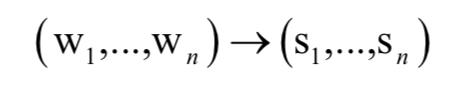
最简单的是基于统计信息的模型,即从训练样本中统计出每种词性的词后面所跟的词的词性,然后计算最大的概率。除此之外,条件熵,隐马尔可夫模型,条件随机场等技术也被用于词性标注问题。
同样的,词性标注问题可以看做是一个序列标注问题。将循环神经网络用于词性标注时,输入序列是一个句子的单词序列,每个时刻的输入向量是单词的one-hot编码向量,网络的输出为单词属于某一类次的概率,此时输出层可以采用softmax作为激活函数。在这里,典型的标注集合为:
{v,n,a,...}
其中v为动词,n为名字,a为形容词,其他词性在这里不详细列出。训练时,也使用端到端的方案,直接给定语句和对应的标签序列。神经网络的预测输出就是每个词的词性类别值。
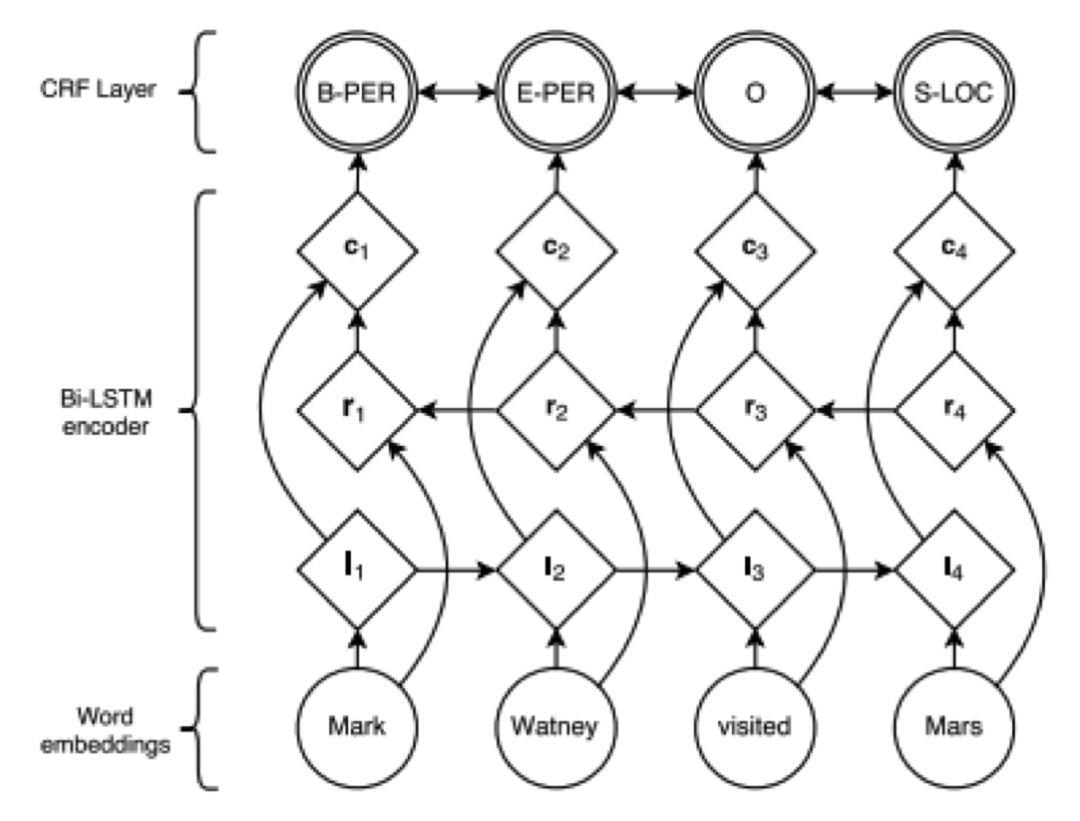
命名实体识别
命名实体识别(Named Entity Recognition,简称NER)又称为专名识别,其目标是识别文本中有特定含义的实体,如人名、地名、机构名称、专有名词等,属于未登录词识别的范畴。命名实体识别和其他自然语言处理问题相比存在的一个困难是训练样本的缺乏,因为未登录词很少有重复的,基本上都是新词。
如果直接用序列标注的方法解决命名实体识别,思路和分词类似,这里要识别出句子里所有的专名词。假设要识别的专有词包括人名,地名,组织机构名称,则标注集合为:
{BN,MN,EN,BA,MA,EA,BO,MO,EO,O}
其中BN表示这个字是人名的开始,BN表示人名的中间字,EN表示人名的结束;BA表示地名的开始,MA表示地名的中间字,EA表示地名的结束;BO表示机构名称的开始,MO表示机构名称的中间字,EO表示机构名称的结束;O表示这个字不是命名实体。给定所有训练样本句子的标注序列,我们就可以实现端到端的训练。预测时输入一个句子,输出标签序列,根据标签序列我们可以得到命名实体识别的结果。
除了这种最直接的序列标记手段,还更复杂的方法。文献[31]提出了一种用LSTM和条件随机场CRF进行命名实体识别的方法。假设LSTM网络的输入序列是(x1,...,xn ),输出序列是(h1,...,hn)。其中,输入序列是一个句子所有的单词,这些单词被编码为向量。
LSTM在t时刻的输出向量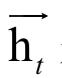 是句子中第t个单词的左上下文。单词的右上下
是句子中第t个单词的左上下文。单词的右上下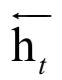 文也是非常重要的信息,也通过LSTM计算得到,具体做法是将整个句子颠倒过来送入LSTM中计算,第个时刻的输出向量即为右上下文。在这里,称第一个LSTM为前向LSTM,第二个为后向LSTM。它们是两个不同的神经网络,分别有各自的参数。这种结构也称为双向LSTM。
文也是非常重要的信息,也通过LSTM计算得到,具体做法是将整个句子颠倒过来送入LSTM中计算,第个时刻的输出向量即为右上下文。在这里,称第一个LSTM为前向LSTM,第二个为后向LSTM。它们是两个不同的神经网络,分别有各自的参数。这种结构也称为双向LSTM。
每个词用它的左上下文和右上下文联合起来表示,即将两个向量拼接起来:
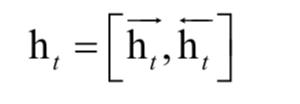
接下来用条件随机场对句子中的所有词进行联合标注。对于一个句子,假设矩阵P是双向LSTM输出的得分矩阵。这是一个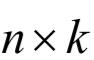 的矩阵,其中k是不同的标记个数。元素pij为第i个单词被赋予第j个标记的概率。对于预测输出序列y,它的得分定义为:
的矩阵,其中k是不同的标记个数。元素pij为第i个单词被赋予第j个标记的概率。对于预测输出序列y,它的得分定义为:
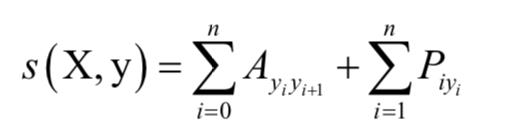
其中矩阵A是转移得分矩阵,其元素表示从标记i转移到标记j的得分。y0和yn 是句子的开始和结束标记,我们把它们加入到标记集合中。因此矩阵A是一个k+2阶方阵。
对所有可能的标记序列的softmax值定义了序列的概率:
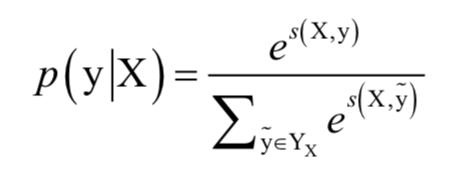
其中YX 为X句子所有可能的标记序列。在解码时将具有最大得分的序列作为预测输出:
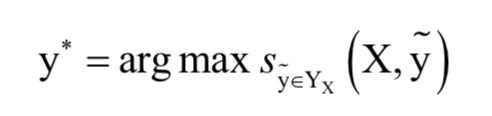
这可以通过动态规划算法得到。根据输出序列的值,我们就可以直接得到命名实体识别的结果。
文本分类
文本分类是自然语言处理中的重要问题,经典的机器学习算法如支持向量机、贝叶斯分类器等都曾被用于解决此问题。卷积神经网络在文本分类问题中也有应用。除了这些方法之外,循环神经网络也被成功的应用于文本分类问题。
文献[34]设计了一种用分层注意力网络进行文本分类的方案。在这种方案里采用了分层的结构,首先建立句子的表示,然后将它们聚合,形成文档的表示。在文档中,不同的词和句子所蕴含的有用信息是不一样的,而且重要性和文档上下文有密切的关系。因此,采用了两层的注意力机制,第一个是单词级的,第二个是句子级的。在提取文档的表示特征时,会关注某些词和句子,也会忽略一些词和句子。
整个网络由一个单词序列编码器,一个单词级注意力层,一个句子编码器,一个句子级注意力层组成。单词序列编码器由GRU循环神经网络实现。网络的输入是一个句子的单词序列,输出是句子的编码向量。
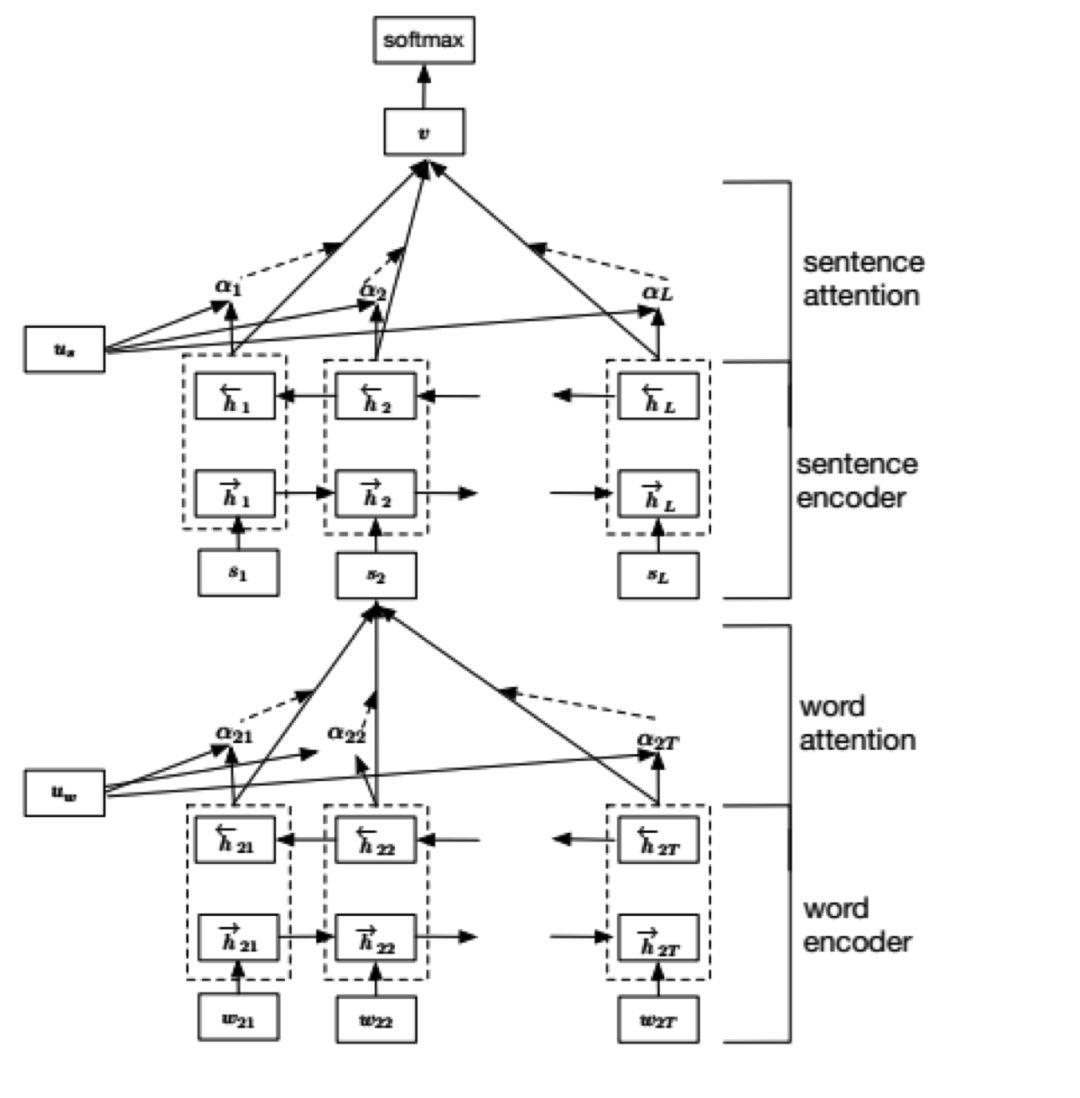
假设一篇文档有L个句子si,句子si有Ti个词。wit 表示第i个句子中的第t个单词,其中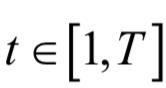 。HAN将文档投影为一个向量,然后对这个向量进行分类。
。HAN将文档投影为一个向量,然后对这个向量进行分类。
第一步是采用词嵌入技术将一个句子的单词转换为一个向量。计算公式为:
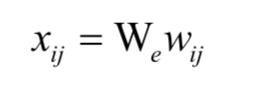
在这里We 称为嵌入矩阵。然后用双向GRU网络对词序列进行编码:
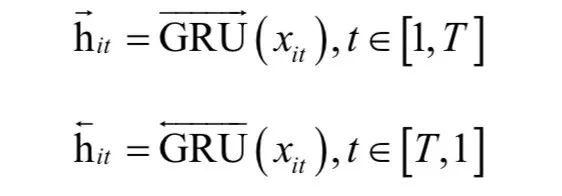
具体做法参考双向RNN和双向LSTM。得到隐含层的状态值:
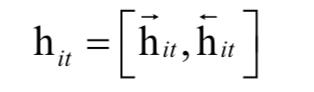
将这个状态值作为句子的表示。句子中的不同单词有不同的重要性,在这里采用了注意力机制。它的计算公式为:
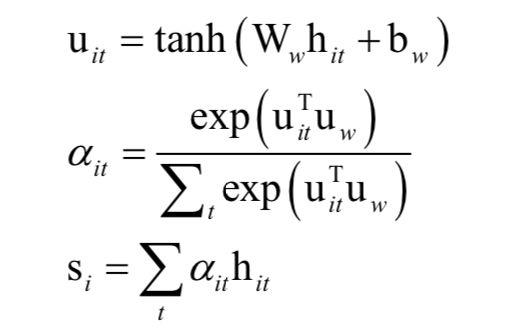
首先将hit输入一个单层的MLP,得到它的隐含层表示uit,这个单词的重要性由向量uit与单词级上下文向量uw的相似度来衡量。通过softmax函数,最后得到归一化的重要性权重值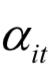 。接下来计算句子向量si,它是词向量的加权平均,加权值为每个词的重要性权重。在这里,上下文向量uw被随机初始化,并且在训练过程中和神经网络一起训练得到。
。接下来计算句子向量si,它是词向量的加权平均,加权值为每个词的重要性权重。在这里,上下文向量uw被随机初始化,并且在训练过程中和神经网络一起训练得到。
在得到句子向量之后,我们可以用类似的方式得到文档向量。在这里,使用双向GRU对句子进行编码:
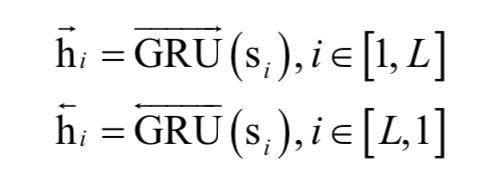
将这两个向量合并,得到句子的编码向量:
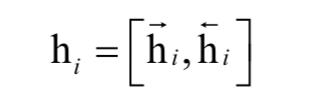
这个编码综合第i个句子周围的句子,但还是聚焦于第i个句子。类似的,我们用句子级的注意力机制来形成文档的表示向量:
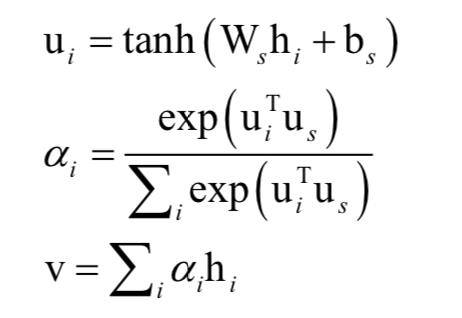
在这里v是文档向量,它综合了文档中所有句子的信息。同样的,us 向量通过训练得到。
最后用文档向量来对文档进行分类:
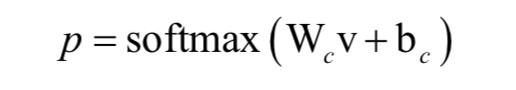
训练时的损失函数采用负对数似然函数,定义为:
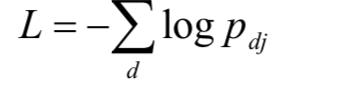
其中j是第d个文档的类别标签值。采用注意力机制,可以直接把对分类有贡献的词和句子显示出来,便于理解和调试分析。
自动摘要
自动摘要的目标是给定一段文本,得到它的摘要信息,摘要信息浓缩了文本的内容,和输入文本有相同的语义,体现了文章的主要内容。在这里,输入文本可以是一句话或者多句话。摘要输出语句的词汇表和输入文本的词汇表相同。可以将自动摘要也看成是一个序列到序列的预测问题,输出序列的长度远小于输入序列的长度。
文献[35]提出了一种使用注意力机制和seq2seq技术的新闻类文章标题生成算法。在这里,先用seq2seq的编码网络生成文本的抽象表示,解码器网络在生成摘要的每个单词的时候使用注意力机制关注文本中的重点词。
首先,新闻文章的每个单词被依次输入编码网络,单词首先被送入嵌入层,生成概率分布表示。然后,被送入有多个隐含层组成的训练神经网络。所有词被输入网络处理之后,最后一个隐含层的状态值将用来作为解码器网络的输入。
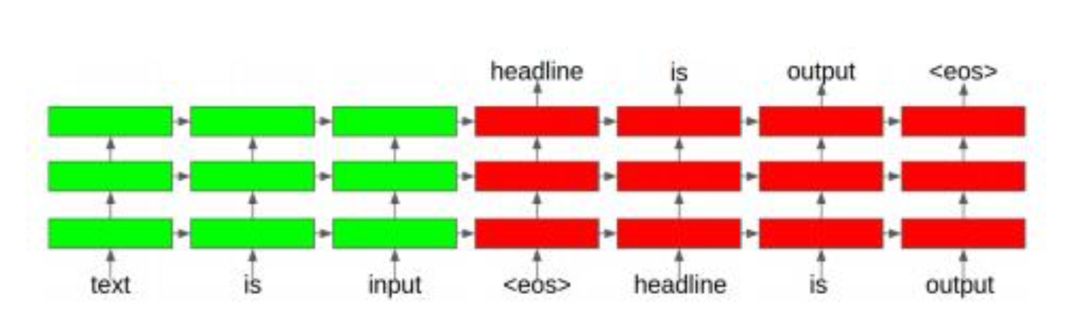
接下来将作为解码器网络的初始状态。首先将一个结束符end-of-sequences,简称EOS,输入解码器网络,用softmax层和注意力机制生成每一个摘要单词,最后以EOS结束。在生成每一个单词时,将生成的上一个单词作为解码器网络的输入。
训练时的损失函数定义为:
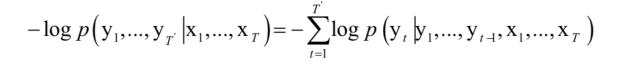
其中xi是输入文本的单词序列,yi是生成的摘要单词序列。训练时,解码器在每个时刻的输入为真实的标题中的单词,而不是上一时刻生成的单词。在测试时,则使用的是上一时刻生成的单词。但这样做会造成训练和预测时的脱节,作为补救,在训练时随机的使用真实的单词和上一时刻生成的单词作为输入。在预测时,使用集束搜索技术生成每一个输出单词。
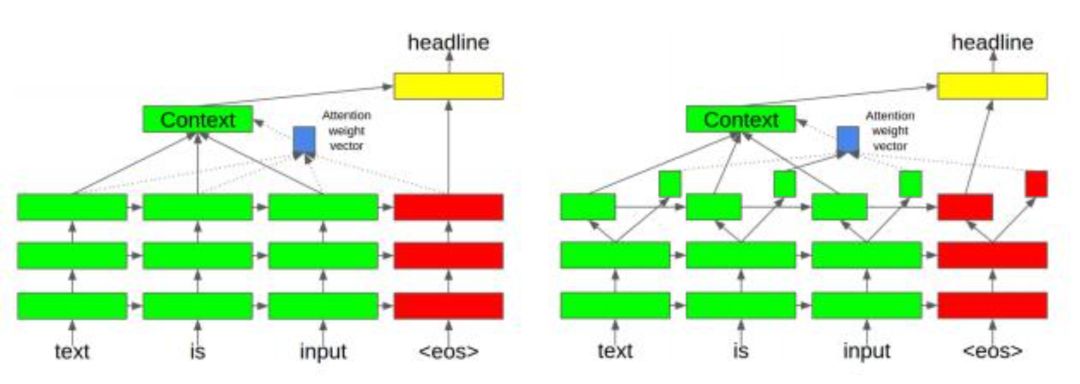
在解码器生成每个输出单词时使用了注意力机制。对于每一个输出单词,注意力机制为每个输入单词计算一个权重值,这个权重值决定了对每个输入单词的关注度。这些权重的和为1,并被用于计算最后一个隐含层的输出值的加权平均值,在这里,每次处理完一个输入单词,会产生一个输出值,最后是对这些输出值进行平均。这个加权平均值被看做是文档的上下文信息,接下来,它和解码器当前解码时最后一个隐含层的输出值一起被送入softmax层进行计算。
机器翻译
统计机器翻译采用大量的语料库进行学习,训练样本为源语言和目标语言的语句。得到模型之后,对于一个语句,算法直接使用这个模型得到目标语言的语句。如果用统计学习的方法,机器翻译要解决的问题是,给定一个输入句子a,对于另外一种语言所有可能的翻译结果b,计算条件概率:
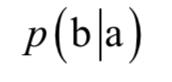
概率最大的句子就是翻译的结果。使用机器学习的翻译有基于词的翻译和基于短语的翻译两种方法。前者对词进行翻译,不考虑上下文语境和词之间的关联,后者对整个句子进行翻译,目前主流的是基于短语的翻译。
我们可以将机器翻译问题抽象成一个序列到另外一个序列的预测:
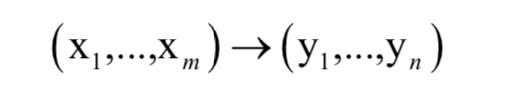
和语音识别之类的应用不同,这里的序列到序列映射并不是一个单调映射,也就是说,输出序列的顺序是按照输入序列的顺序来的。这很容易理解,将一种语言的句子翻译成另一一种语言的句子时,源语言种的每个单词的顺序和目标语言种每个单词的顺序不一定是一致的。
训练时的目标是对所有的样本最大化下面的条件概率:
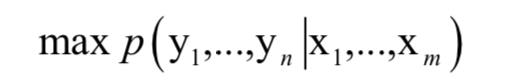
因此我们需要在所有可能的输出序列中寻找到上面的条件概率值最大的那个序列作为机器翻译的输出。如果用神经网络来对机器翻译进行建模,称为神经机器翻译。当前,用循环神经网络解决机器翻译问题的主流方法是序列到序列学习技术。
文献[15]提出了用seq2seq技术解决机器翻译问题。在这里,使用编码器对输入的输入序列进行特征编码,得到这句话的意义,然后用解码器对这个意义进行解码并得到概率最大的输出序列,这就得到了翻译的结果。
先将源句子表示成向量序列xi , i =1, ..., T,在这里每个向量是一个词的编码向量。通过第一个循环神经网络,当我们输入完这个序列之后得到最后时刻的隐含层状态值hT,在这里简记为v。这个值包含了整个句子的信息。
接下来用解码器生成翻译序列。解码器循环神经网络银行层的初始状态值为v,它输出向量序列yi, i =1,...,n。对于所有可能的输出序列,我们都可以用解码器计算出它的条件概率值,在这里要寻找概率值最大的那个序列。如果枚举所有可能的输出序列,计算量太大,显然是不现实的。在这里采用了集束搜索技术。
训练样本是成对的句子,即源句子和它的翻译结果。训练的目标是最大化对数概率值:
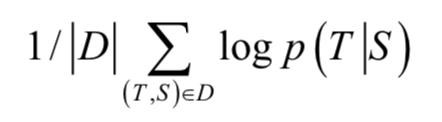
其中D是训练样本集,S是源句子,T是翻译的句子。训练完成之后,可以用这个模型来进行翻译,即寻找概率最大的输出序列:
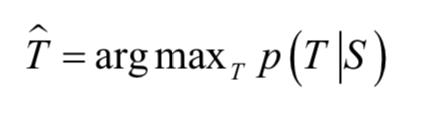
在这里采用了自左到右的集束解码器。它维持个最有可能的部分结果,部分结果是整个翻译句子的前缀部分。在每一步,我们在词典的范围内用每一个可能的词扩展这个部分结果。然后用seq2seq模型计算这些部分结果的概率,保留概率最大的个部分结果。当输入结束符之后,整个翻译过程结束。
在实现时,无论是在训练阶段还是测试阶段,都将句子反序输入,但是预测结果序列是正序而不是反序。另外,并没有采用单个隐含层的循环神经网络,而是采用了4层的LSTM网络。
文献[36]提出了一种用编码器-解码器框架进行机器翻译的方法。在这里,编码器-解码器框架的结构和之前介绍的相同。
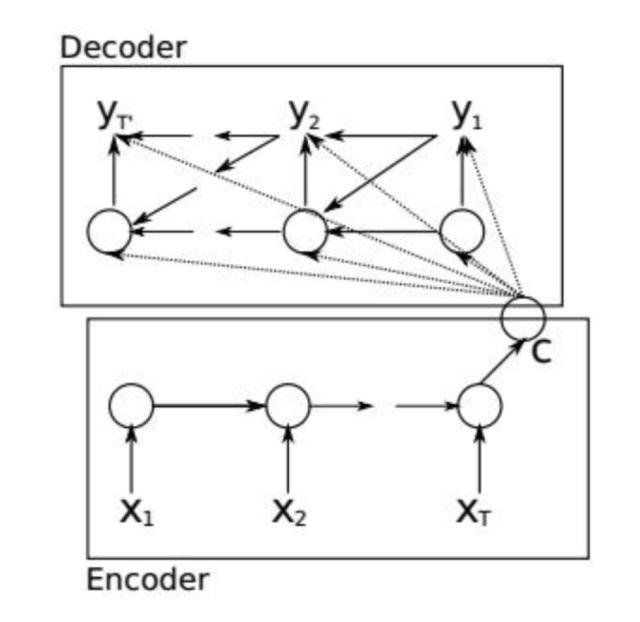
不同的是,使用了一种新的隐藏单元,即循环层的激活函数。这种激活函数和LSTM类似,但计算更简单。在这里,使用了两个门来进行信息流的控制,分别称为更新门和复位门。复位门的计算公式为:
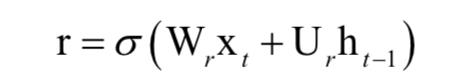
更新门的计算公式为:
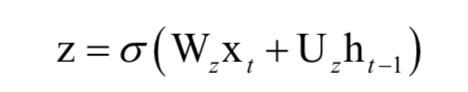
隐含层的变换公式为:
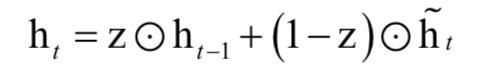
在这里,更新门用来控制新老信息的权重。其中:
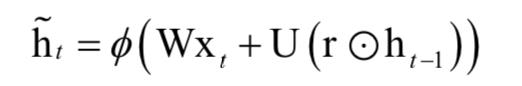
假设e为源语句,f为翻译后的目标语句。根据贝叶斯公式,机器翻译的目标是给定源语句,寻找使得如下条件概率最大的目标语句:
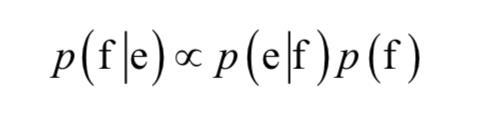
上式右边的第一项为转换模型,第二项为语言模型,这和语音识别类似。大多数机器翻译算法将转换模型表示成对数线性模型:
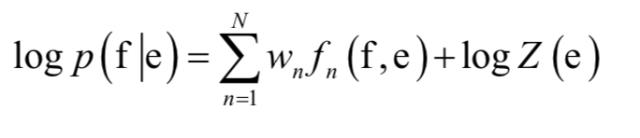
其中fn 为第n个特征,为特征的权重,Z(e)为归一化因子。在这里编码器-解码器框架用于对对数线性模型的翻译候选结果短语进行评分。
文献[37]提出了一种使用了双向循环神经网络的机器翻译算法,循环层也使用了重置门和更新门结构。
解码器用循环神经网络实现,它根据当前状态,以及当前的输出词预测下一个输出词,计算公式为:
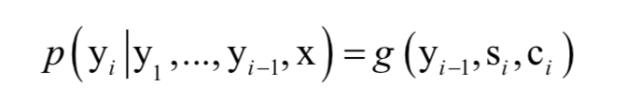
其中si 为解码器网络隐含层的状态。这个框架采用了注意力机制,计算方法和之前介绍的相同。
文献[38]介绍了Google的机器翻译系统。他们的系统同样采用了编码器-解码器架构,两个网络都由深层双向LSTM网络实现,并采用了注意力机制。
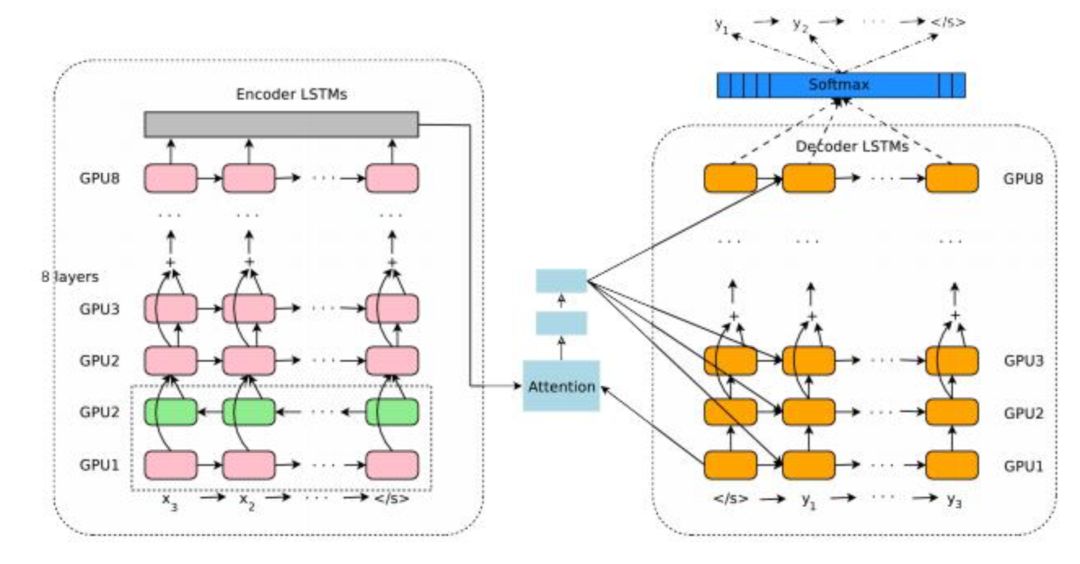
这里的深层双向LSTM网络和前面介绍的相同,不再重复讲述。为了克服深层带来的梯度消失问题,隐含层采用了残差网络结构,即跨层连接。
训练时的目标是最大化对数似然函数,即对数条件概率值:
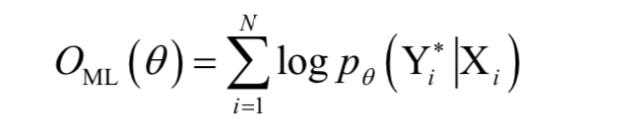
在这里是要求解的参数。同样的,解码时也使用了集束搜索算法。
机器视觉
对于机器视觉中的某些问题,循环神经网络也取得了很好的效果。在这些问题中,数据都被抽象成一个时间序列,如物体运动的动作,状态等。
字符识别
如果我们知道每个字符的笔画信息,即整个字的书写过程,则可以将手写字符识别看成是一个轨迹分类问题。每个手写字符是一个序列数据,每个时刻的坐标连接起来,在平面上构成一个字符的图像。手写字符识别属于序列标记问题中的序列分类问题,即给定一个字符的坐标点序列,预测这个字符的类别。在这里,循环神经网络的输入为坐标点序列,输出值为类别,为了达到这个目的,我们可以将最后一个时刻的循环层输出值映射为类别概率,这可以通过softmax层实现。
另外,也可以直接以图像作为输入,在这里,将图像看作是一个序列,序列中的每一个向量是图像中的一个行的像素。依次将每一行输入循环神经网络,最后时刻的隐含层状态输出作为提取的字符特征,送入softmax层进行分类。
目标跟踪
运动跟踪可以抽象为已知目标在之前时刻的坐标,预测出它在当前时刻的坐标,这同样是一个序列预测问题。
文献[42]提出了一种用循环神经网络进行目标跟踪的方法,称为RTT。RTT主要目标是解决目标遮挡问题。循环神经网络的作用是得到置信度图,即每个点处是目标的概率。下面介绍这种方法的处理流程。
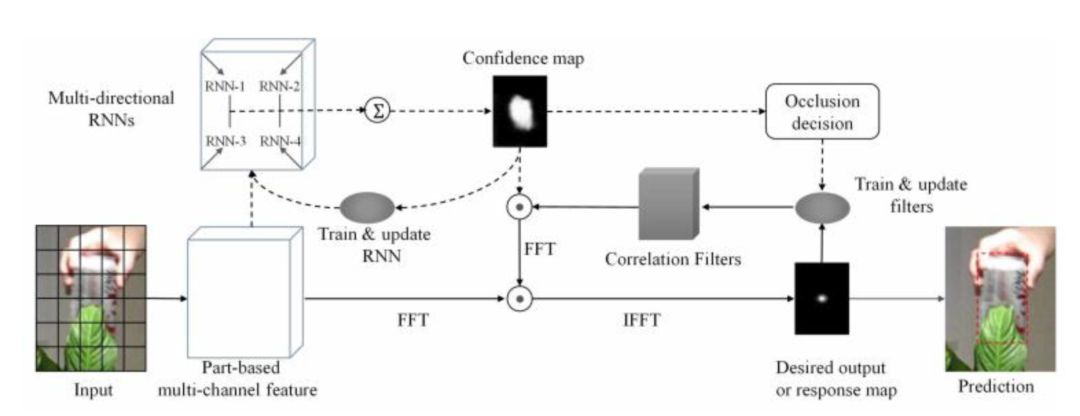
在对每一帧进行跟踪时,给定目标在上一帧中的矩形框,以目标的中心为中心,以目标宽高的2.5倍为宽高,即将目标矩形放大2.5倍,得到一个矩形的候选区域。然后,将这个候选区域划分成网格。然后对每个矩形框提取特征,可以使用HOG特征,也可以使用更复杂的卷积网络提取的特征。在这里,划分网格而不是对整个候选区域计算特征的原因是这样做能够更好的处理遮挡,以及目标外观的变化。最后我们得到候选区域的特征。
然后,以这个特征作为输入,用多维RNN对特征进行处理,得到置信度图。最后根据置信度图完成对目标位置的预测。
和单个目标跟踪不同,多目标跟踪需要解决数据关联问题,即上一帧的每个目标和下一帧的哪个目标对应,还要解决新目标出现,老目标消失问题。多目标的跟踪的一般流程为每一时刻进行目标检测,然后进行数据关联,为已有目标找到当前时刻的新位置,在这里,目标可能会消失,也可能会有新目标出现,另外目标检测结果可能会存在虚警和漏检测。联合概率滤波,多假设跟踪,线性规划,全局数据关联,MCMC马尔可夫链蒙特卡洛算法先后被用于解决数据关联问题来完成多个目标的跟踪。
首先我们定义多目标跟踪的中的基本概念,目标是我们跟踪的对象,每个目标有自己的状态,如大小、位置、速度。观测是指目标检测算法在当前帧检测出的目标,同样的,它也有大小、位置、速度等状态值。在这里,我们要建立目标与观测之间的对应关系。下图是数据关联的示意图:
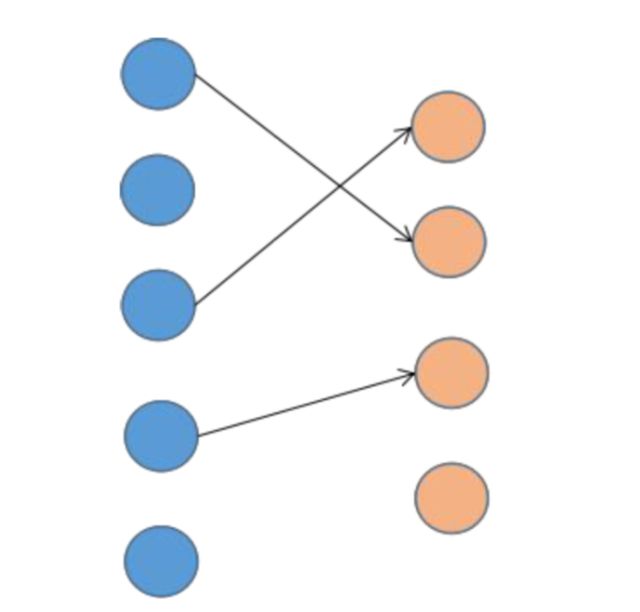
在上图中,第一列圆形为跟踪的目标,即之前已经存在的目标;第二列圆为观测值,即当前帧检测出来的目标。在这里,第1个目标与第2个观察值匹配,第3个目标与第1个观测值匹配,第4个目标与第3个观测值匹配。第2个和第5个目标没有观测值与之匹配,这意味着它们在当前帧可能消失了,或者是当前帧被漏检,没有检测到这两个目标。类似的,第4个观测值没有目标与之匹配,这意味着它是新目标,或者虚警。
文献[43]提出了一种用循环神经网络在线跟踪多个目标的算法。这种方法实现了完全端到端的训练。在这里,用LSTM循环神经网络同时解决数据关联、新目标出现、老目标消失问题。
首先定义状态向量xt,这是一个 NxD 维向量,表示t时刻所有目标的状态值,其中,D为每个目标的状态个数,在这里值为4,分别为目标的位置和宽高。定义N为某一帧中能够同时跟踪的最大目标个数。xit为第i个目标的状态。
类似的定义观测向量zt,这是一个 MxD 维向量,表示t时刻所有观测值。其中M为每一帧中最大检测目标个数。需要注意的是,我们对模型能够处理的最大目标个数并没有限制。
接下来定义分配概率矩阵A,这是一个Nx(M+1)的矩阵,元素取值0和1之间的实数。矩阵的每一行为一个目标的分配概率向量,即元素Aij表示将第i个目标分配给第j个观测的概率。分配概率矩阵满足约束条件:
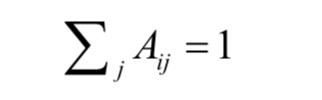
在这里矩阵的列数不是M而是 M+1,这是因为一个目标可能不和任何一个观测向匹配。
最后定义指示向量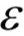 ,这是一个N维向量,每个元素表示一个目标存在的概率值。
,这是一个N维向量,每个元素表示一个目标存在的概率值。
跟踪问题被分成两个部分来解决:状态预测与更新,以及跟踪管理;数据关联。前一部分负责单个目标的状态跟踪;后一部分解决目标之间的对应关系。
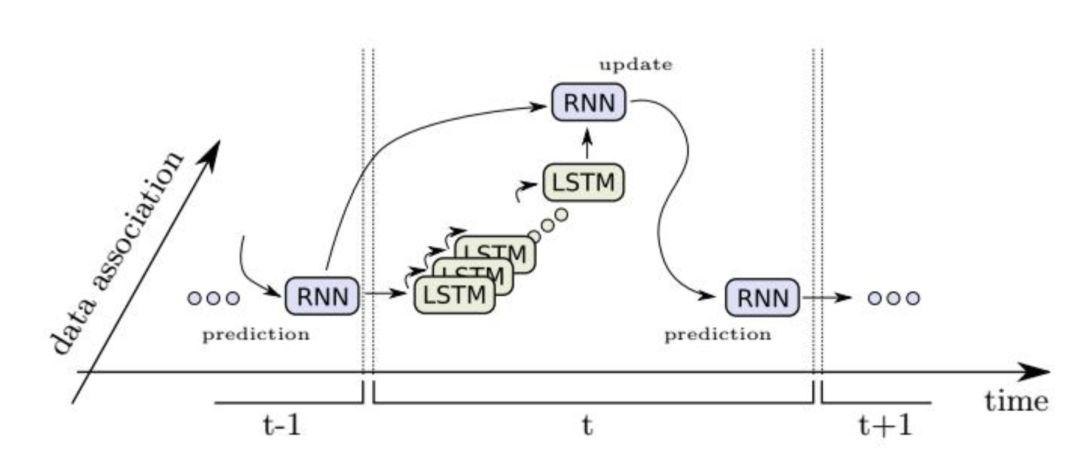
对于第一个问题,用一个时序循环神经网络来学习N个目标的运动模型,以及目标的指示变量,指示变量用于处理目标的出现与消失。在时刻t,循环神经网络输出四种值:
1.包括所有目标的状态预测值x*t+1,前面已经介绍过。
2.所有目标状态的更新值xt+1。
3.指示向量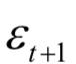 ,其每个元素的值位于之间,表示目标是一个真实轨迹的概率。
,其每个元素的值位于之间,表示目标是一个真实轨迹的概率。
4.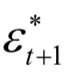 ,这是与
,这是与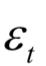 的差值。
的差值。
神经网络的输入为前一个时刻的状态值xt,前一个时刻的指示向量值,当前时刻的观测值zt+1,以及当前时刻的数据关联矩阵At+1,数据关联矩阵的计算方法将在后面介绍。
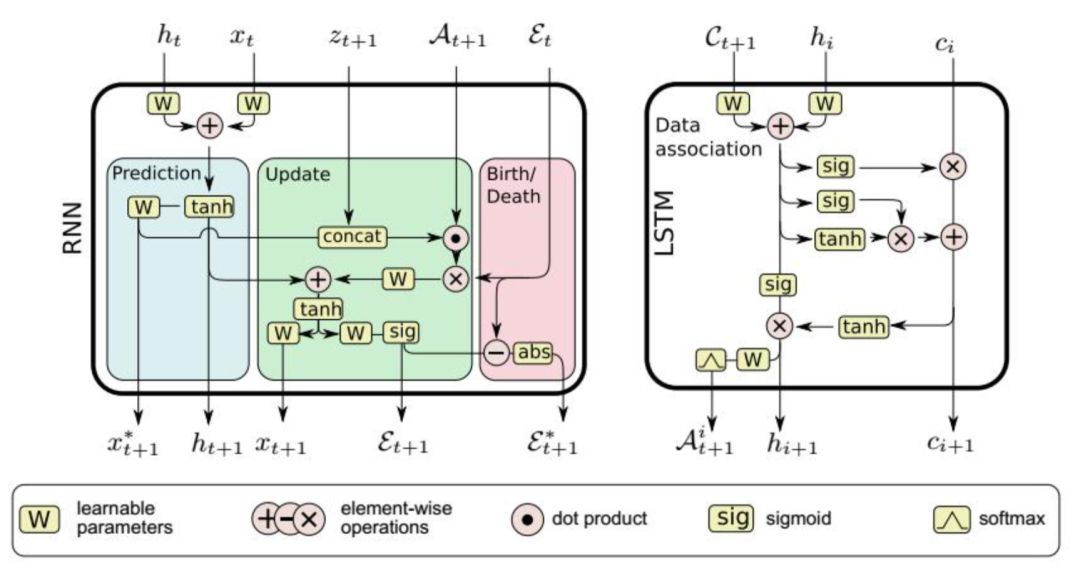
这个功能模块有三个目标:
1.预测。为指定数量的目标学习一个复杂的运动模型,这个模型包含了每个目标的运动参数,包括速度,加速度信息等。
2.更新。根据当前的观测数据,对预测值进行校正,修正物体的状态值,包括运动状态值。
3.目标的出现与消失。学习到如何根据目标的状态值、当前时刻的观测值,以及数据关联信息来处理新目标的出现,已有目标的消失问题。
预测值x*t+1只取决于状态值xt和循环神经网络隐含层的状态值ht。一旦数据关联矩阵At+1已经确定,即已经知道了目标和观测之间的对应关系,我们就可以根据观测值来更新状态值,完成校正。接下来,将观测值和预测的状态值拼接在一起:
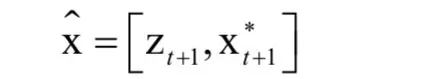
然后乘以矩阵At+1。同时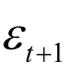 也被计算出来。在确定了网络的输出和输出之后,我们需要定义训练时的损失函数。损失函数定义为:
也被计算出来。在确定了网络的输出和输出之后,我们需要定义训练时的损失函数。损失函数定义为:
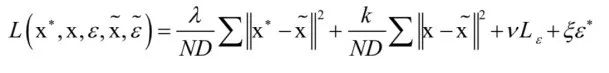
其中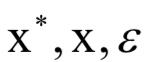 为预测值,
为预测值,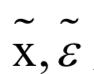 为真实值。上面损失函数的第一部分为预测误差,第二部分为更新误差,第三和第四部分为目标消失、出现以及回归值误差。这里只是定义了某一个时刻的误差值,训练时需要将每一帧的误差值累加起来,然后计算平均值。第一部分误差的意义是在没有观察值的情况下,预测值要和目标的真实运动轨迹尽可能接近。第二部分的意义是得到观测值之后,要将预测值校正到和观测值尽可能接近。
为真实值。上面损失函数的第一部分为预测误差,第二部分为更新误差,第三和第四部分为目标消失、出现以及回归值误差。这里只是定义了某一个时刻的误差值,训练时需要将每一帧的误差值累加起来,然后计算平均值。第一部分误差的意义是在没有观察值的情况下,预测值要和目标的真实运动轨迹尽可能接近。第二部分的意义是得到观测值之后,要将预测值校正到和观测值尽可能接近。
第三部分损失反应了目标的出现与消失。如果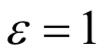 ,表示一个目标存在,如果
,表示一个目标存在,如果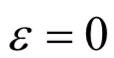 ,表示这个目标不存在。为此我们定义交叉熵损失函数:
,表示这个目标不存在。为此我们定义交叉熵损失函数:
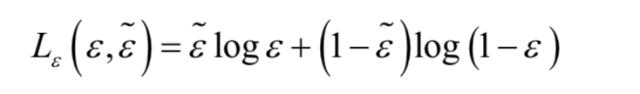
最后一个问题是数据关联。数据关联的目标是为每个目标分配一个唯一的观测值,这是一个组合优化问题,直接求解的话是NP完全问题。在这里,采用LSTM网络通过学习来解决此问题。在这里,网络的输入是成对距离矩阵C,这是一个NxM的矩阵,矩阵元素定义为:
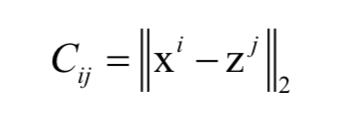
即第i个目标的预测状态与第j个观察值之间的欧氏距离。当然,我们也可以使用更多的信息,如目标的外观或其他相似度。网络的输出值为概率向量Ai,表示第i个目标与所有观测值之间的分配概率,这可以通过softmax层输出。这里的Ai是数据关联矩阵的第i行。最后,我们定义网络训练时的损失函数为:
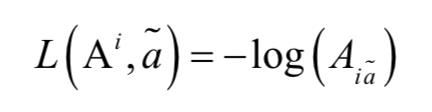
其中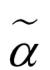 是一个标量,是目标i的真实分配值,即将目标i分配给观测值。
是一个标量,是目标i的真实分配值,即将目标i分配给观测值。

视频分析
视频动作识别是机器视觉领域的一个重要问题,它的目标是对运动物体的动作进行分类,如人的站立,坐下等动作。动作识别在诸多领域有实际的应用,如视频监控、人机交互、游戏控制等。这个问题可以抽象成一个时间序列分类问题。以人的动作识别为例,它的输入是目标关键点坐标序列,如人体一些关键点的2D或3D坐标,输出值为动作类别,即序列的标签值。
文献[45]提出了一种整合了卷积神经网络和循环神经网络的框架进行人体动作分类的方法。整个系统包括一个3D卷积神经网络和一个循环神经网络。其中,3D卷积神经网络的输入为多张图像,用于提取一段视频的时空特征。然后将提取的特征序列送入循环神经网络中进行分类。
在这里,卷积神经网络的输入为3D图像。整个视频被分成一系列的固定长度片段,每个片段包括相同数量的帧,被处理成固定大小的输入图像。第三个卷积层后面是两个全连接层,最后一个全连接层有6个神经元,即卷积网络的输出向量为6维。
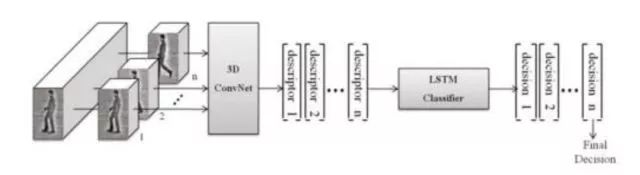
接下来将卷积得到的固定长度的特征向量序列送入LSTM循环神经网络。用循环神经网络的输出完成对视频的分类。
文献[46]提出了一种用双向LSTM循环神经网络进行3D手势分类的方法。在这里,每个时刻用加速度计和陀螺仪测量出手在3D空间的加速度和角速度,形成一个6D的向量,作为循环神经网络的输入,这是一个序列数据。循环神经网络采用双向LSTM网络。循环神经网络的输出向量维数和要分类的手势类型数相同,最后通过softmax层产生概率输出用于分类。这些都是标准的做法,不再详细讲述。
文献[47]提出了一种用分层循环神经网络进行人体动作识别的方法,在这里,利用了人体骨架的关键点信息,对骨架关键点的运动轨迹进行分析。
整个人体被分成5个部分进行建模,分别为四肢和躯干。整个处理流程为:
1.将5个部分分别送入5个子网络中进行处理
2.将四肢和躯干在第一步中的处理结果分别进行融合,送入4个子网络中进行处理
3.将两只胳膊,两条腿,躯干在第二步中的处理结果进行融合,送入2个子网络中进行处理
4.将上一步中的两个结果融合,送入第4层子网络中进行处理
5.将上一步的结果送入全连接层中进行处理
6.最后用softmax层进行计算,得到分类概率
在这里,所有循环层都使用双向循环结构,前面3个循环层都采用tanh激活函数,最后一个循环层采用LSTM单元。循环层和全连接层的计算方式和前面介绍的标准结构相同,在这里不详细讲述。
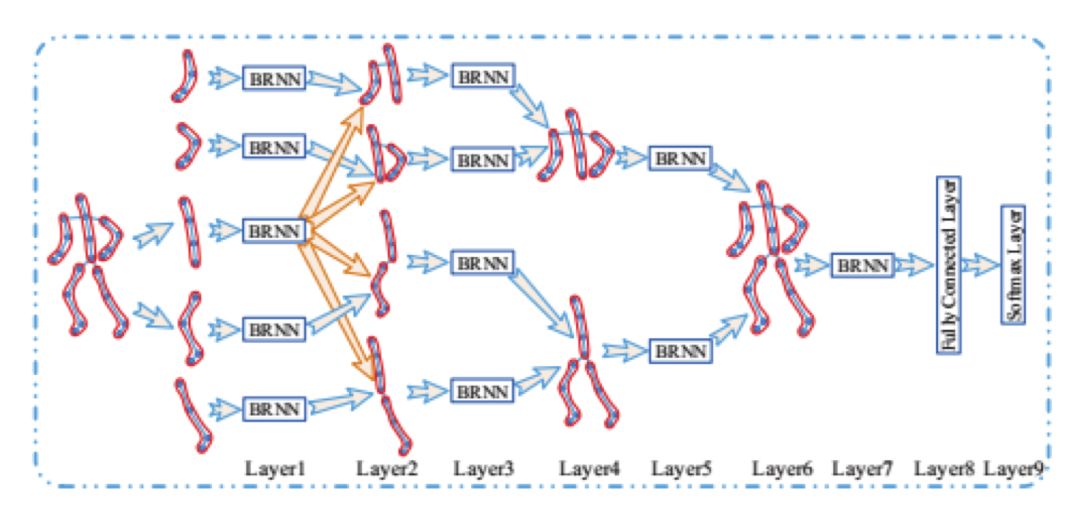
全连接层在各个时刻的输出向量被累计起来,然后用softmax层进行概率输出。整个网络的输入为人体各个部位关键点的3D坐标,送入网络之前,对坐标进行了归一化处理;要识别的动作类型根据实际应用而定。
文献[48]提出了一种整合卷积神经网络和循环神经网络的视频识别方法。在这里,用卷积网络提取单帧图像的特征,多个帧的特征依次被送入循环神经网络中进行处理。这种结构不仅在空间上具有深度,在时间上也具有深度,称为Long-term Recurrent Convolutional Networks,简称LRCNs。
整个系统的输入是一系列的视频帧,对于每一帧,首先经过卷积网络的作用,产生固定长度的输出向量。经过这一步,我们得到一个固定长度的序列数据:
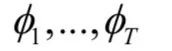
这个序列数据被送入循环神经网络中进行处理,得到输出值。最后,经过softmax层,得到概率输出。这里的卷积网络和循环神经网络的变换和前面介绍的标准做法一致,不再重复介绍。
假设循环神经网络的学习参数为V和W,训练时的损失函数定义为:
这一框架可以用于以下三种情况:
1.序列输入,固定长度输出。即实现映射(x1,...,xT )-> y,典型的是视频动作识别。在这里输入是多个视频帧,输出是动作类别。
2.固定长度输入,序列输出。即实现映射x ->(y1,...,yT ),典型的是生成图像的描述,如给图像生成文字说明。
3.序列输入,序列输出。即实现映射(x1,...,xT )->(y1,...,yT' ),典型的是视频描述,如为一段视频生成一段文字解说。
参考文献:
[1] Mikael Boden. A guide to recurrent neural networks and backpropagation. 2001.
[2] Ronald J Williams, David Zipser. A learning algorithm for continually running fully recurrent neural networks. 1989, Neural Computation.
[3] Fernando J Pineda. Generalization of back-propagation to recurrent neural networks. 1987, Physical Review Letters.
[4] Paul J Werbos. Backpropagation through time: what it does and how to do it. 1990, Proceedings of the IEEE.
[5] Xavier Glorot, Yoshua Bengio. On the difficulty of training recurrent neural networks. 2013, international conference on machine learning.
[6] Y. Bengio, P. Simard, P. Frasconi. Learning long-term dependencies with gradient descent is difficult. IEEE Transactions on Neural Networks, 5(2):157-166, 1994.
[7] S. Hochreiter, J. Schmidhuber. Long short-term memory. Neural computation, 9(8): 1735-1780, 1997.
[8] Kyunghyun Cho, Bart Van Merrienboer, Caglar Gulcehre, Dzmitry Bahdanau , Fethi Bougares, Holge. Learning Phrase Representations using RNN Encoder--Decoder for Statistical Machine Translation. 2014, empirical methods in natural language processing.
[9] M. Schuster and K. K. Paliwal. Bidirectional recurrent neural networks. IEEE Transactions on Signal Processing, 45(11):2673-2681, 1997.
[10] Junyoung Chung, Caglar Gulcehre, Kyunghyun Cho, Yoshua Bengio. Gated Feedback Recurrent Neural Networks. 2015, international conference on machine learning.
[11] Razvan Pascanu, Caglar Gulcehre, Kyunghyun Cho, Yoshua Bengio. How to Construct Deep Recurrent Neural Networks. 2014, international conference on learning representations.
[12] Alex Graves. Supervised Sequence Labelling with Recurrent Neural Networks.
[13] Alex Graves, Santiago Fernandez, Faustino J Gomez, Jurgen Schmidhuber. Connectionist temporal classification: labelling unsegmented sequence data with recurrent neural networks.2006, international conference on machine learning.
[14] Alex Graves, Navdeep Jaitly. Towards End-To-End Speech Recognition with Recurrent Neural Networks. 2014, international conference on machine learning.
[15] Ilya Sutskever, Oriol Vinyals, Quoc V Le. Sequence to Sequence Learning with Neural Networks.2014, neural information processing systems.
[16] Oriol Vinyals, Suman Ravuri, and Daniel Povey. Revisiting Recurrent Neural Networks for Robust ASR. ICASSP, 2012.
[17] A. Graves, A.Mohamed, G. Hinton, Speech Recognition with Deep Recurrent Neural Networks, ICASSP 2013.
[18] Alex Graves, Santiago Fernandez, Juergen Schmidhuber. Multi-dimensional recurrent neural networks. 2007, international conference on artificial neural networks.
[19] Dario Amodei, Sundaram Ananthanarayanan, Rishita Anubhai, Jingliang Bai, Eric Battenberg. Deep speech 2: end-to-end speech recognition in English and mandarin. 2016, international conference on machine learning.
[20] Hasim Sak, Andrew W Senior, Kanishka Rao, Francoise Beaufays. Fast and Accurate Recurrent Neural Network Acoustic Models for Speech Recognition. 2015, conference of the international speech communication association
[21] Miao, Yajie, Mohammad Gowayyed, and Florian Metze. EESEN: End-to-end speech recognition using deep RNN models and WFST-based decoding. 2015 IEEE Workshop on Automatic Speech Recognition and Understanding (ASRU). IEEE, 2015.
[22] Bahdanau, Dzmitry, et al. End-to-end attention-based large vocabulary speech recognition. 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2016.
[23] Chan, William, et al. Listen, attend and spell: A neural network for large vocabulary conversational speech recognition. 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2016.
[24] H. Sak, Hasim, Senior, Andrew, and Beaufays, Francoise. Long short-term memory recurrent neural network architectures for large scale acoustic modeling. In Inter speech, 2014.
[25] Sainath, Tara, Vinyals, Oriol, Senior, Andrew, and Sak, Hasim. Convolutional, long short-term memory, fully connected deep neural networks. In ICASSP, 2015.
[26] Chorowski, Jan, Bahdanau, Dzmitry, Cho, Kyunghyun, and Bengio, Yoshua. End-to-End continuous speech recognition using attention-based recurrent nn: First results. abs/1412.1602, 2015. http://arxiv.org/1412.1602
[27] Hannun, Awni, Case, Carl, Casper, Jared, Catanzaro, Bryan, Diamos, Greg, Elsen, Erich, Prenger, Ryan, Satheesh, Sanjeev, Sengupta, Shubho, Coates, Adam, and Ng, Andrew Y. Deep speech: Scaling up end-to-end speech recognition. 1412.5567, 2014a. http://arxiv.org/abs/1412.5567.
[28] A.Graves. Sequence transduction with recurrent neural networks. ICML Representation Learning Workshop, 2012.
[29] Bahdanau, Dzmitry, Chorowski, Jan, Serdyuk, Dmitriy, Brakel, Philemon, and Bengio, Yoshua. End-to-end attention-based large vocabulary speech recognition. abs/1508.04395, 2015. http://arxiv.org/abs.1508.04395.
[30] Tomas Mikolov, Martin Karafiat, Lukas Burget, Jan Cernocký, Sanjeev Khudanpur. Recurrent neural network based language model. 2010, conference of the international speech communication association.
[31] Guillaume Lample, Miguel Ballesteros, Sandeep Subramanian, Kazuya Kawakami, Chris Dyer. Neural architectures for named entity recognition. 2016, north american chapter of the association for computational linguistics.
[32] Peilu Wang, Yao Qian, Frank K Soong, Lei He, Hai Zhao. Part-of-Speech Tagging with Bidirectional Long Short-Term Memory Recurrent Neural Network. 2015, Computation and Language.
[33] Siwei Lai, Liheng Xu, Kang Liu, Jun Zhao. Recurrent convolutional neural networks for text classification. 2015, national conference on artificial intelligence.
[34] Zichao Yang, Diyi Yang, Chris Dyer, Xiaodong He, Alexander J Smola, Eduard H Hovy. Hierarchical Attention Networks for Document Classification. 2016, north american chapter of the association for computational linguistics.
[35] Konstantin Lopyrev. Generating News Headlines with Recurrent Neural Networks. 2015, arXiv: Computation and Language.
[36] Kyunghyun Cho,Bart Van Merrienboer, Caglar Gulcehre, Dzmitry Bahdanau, Fethi Bougares. Learning Phrase Representations using RNN Encoder--Decoder for Statistical Machine Translation. 2014, empirical methods in natural language processing.
[37] Dzmitry Bahdanau, Kyunghyun Cho, Yoshua Bengio. Neural Machine Translation by Jointly Learning to Align and Translate. 2015, international conference on learning representations.
[38] Yonghui Wu, et al. Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation. Technical Report, 2016.
[39] Graves, Alex. Generating sequences with recurrent neural networks. arXiv preprint arXiv:1308.0850 (2013).
[40] Shujie Liu, Nan Yang, Mu Li, Ming Zhou. A Recursive Recurrent Neural Network for Statistical Machine Translation. 2014, meeting of the association for computational linguistics.
[41] Junyoung Chung, Caglar Gulcehre, Kyunghyun Cho, Yoshua Bengio. Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling. 2014, arXiv: Neural and Evolutionary Computing.
[42] Zhen Cui, Shengtao Xiao, Jiashi Feng, Shuicheng Yan. Recurrently Target-Attending Tracking. 2016, computer vision and pattern recognition.
[43] Anton Milan, Seyed Hamid Rezatofighi, Anthony R Dick, Ian D Reid, Konrad Schindler. Online Multi-target Tracking using Recurrent Neural Networks. 2016, national conference on artificial intelligence.
[44] Peter Ondruska, Ingmar Posner. Deep tracking: seeing beyond seeing using recurrent neural networks. 2016, national conference on artificial intelligence.
[45] M. Baccouche, F. Mamalet, C. Wolf, C. Garcia, and A. Baskurt. Sequential deep learning for human action recognition. In Human Behavior Understanding, pages 29-39. Springer, 2011.
[46] G. Lefebvre, S.Berlemont, F.Mamalet, and C.Garcia. Blstm-rnn based 3d gesture classification. In Artificial Neural Networks and Machine Learning, pages 381-388. Springer, 2013.
[47] Y.Du, W.Wang and L.Wang. Hierarchical recurrent neural network for skeleton based action recognition. CVPR 2015.
[48] J.Donahue, L.A.Hendricks, S.Guadarrama, M.Rohrbach, S.Venugopalan, K.Saenko, and T.Darrell. Long-term recurrent convolutional networks for visual recognition and description. arXiv preprint arXiv:1411.4389, 2014.
[49] A.Grushin, D.D.Monner, J.A.Reggia, and A.Mishra. Robust human action recognition via long short-term memory. In International Joint Conference on Neural Networks, pages 1-8, IEEE, 2013.
[50] Antoine Miech, Ivan Laptev, Josef Sivic. Learnable pooling with Context Gating for video classification. 2017, Computer Vision and Pattern Recognition.
以上是关于循环神经网络综述-语音识别与自然语言处理的利器的主要内容,如果未能解决你的问题,请参考以下文章