语音识别食用指南
Posted Debroon
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了语音识别食用指南相关的知识,希望对你有一定的参考价值。
循环神经网络 RNN
之前描述的全连接神经网络(FCN)和卷积神经网络(CNN),其目标数据的样本是不分先后的。
比如下面这句话:
- 早上好天气,适合(去打球\\睡懒觉)。
既然“天气不错”,那么做出 “去打球” 这个决策的可能性应该高于“睡懒觉”。
为了获取这一类序列特征,在此基础上,具备记忆机制的循环网络模型,逐渐演进到现在,成为更有效的循环神经网络模型(RNN)。
RNN 是一种特别适合识别带有时间先后顺序的数据的算法模型(比如像是文本、语音信息,还有一些具有前后因果关系的图像数据)。
我们平常用的很多中英文翻译软件(如微信的语音转文字),就使用到了这个算法。
单层RNN
早上好天气,适合(去打球\\睡懒觉)。
输入到 RNN 中,会被切分成依次排成的序列:
-
[ 早 , 上 , 好 , 天 , 气 , 适 , 合 , ⋅ ⋅ ⋅ ] [早,上,好,天,气,适,合,···] [早,上,好,天,气,适,合,⋅⋅⋅]
-
[ x 1 , x 2 , ⋅ ⋅ ⋅ , x t ] [x_1,x_2,···,x_t] [x1,x2,⋅⋅⋅,xt]
P.S. 如果有做分词的,那 x 1 x_1 x1 对应的不是一个字,而是一个词。
- 输出: [ 去 , 打 , 球 ] [去,打,球] [去,打,球]

上图中,
h
t
h_t
ht 组成的一条竖线,称为一个 “时间步”。
- h t h_t ht:第 t 层元素的激活值(a)
- x t x_t xt:第 t 个元素
- W h x W_hx Whx:x 作为输入来计算 h 时的参数
- W h h W_hh Whh:上一步 h 作为输入来计算 h 时的参数
- W h y W_hy Why:上一步 h 作为输入来计算 y 时的参数

- h 0 h_0 h0:一般初始化为零向量,是人为添加的
- h 1 = f ( W h x x 1 + W h h h 0 + b ) h_1=f(W_hxx_1+W_hhh_0+b) h1=f(Whxx1+Whhh0+b)
- h 2 = f ( W h x x 2 + W h h h 1 + b ) h_2=f(W_hxx_2+W_hhh_1+b) h2=f(Whxx2+Whhh1+b)
- ···
- h t = f ( W h x x t + W h h h t − 1 + b ) h_t=f(W_hxx_t+W_hhh_t-1+b) ht=f(Whxxt+Whhht−1+b)
- y t = W h y h t + b y y_t=W_hyh_t+b_y yt=Whyht+by
第 1 次处理过程输入是 h 0 、 x 1 h_0、x_1 h0、x1,得到激活值 h 1 h_1 h1。
第 2 次处理过程输入是 h 1 、 x 2 h_1、x_2 h1、x2,得到激活值 h 2 h_2 h2。
也就是说,网络再对第 2 个字( x 2 x_2 x2)预测的时候,会参考第 1 个字( x 1 x_1 x1)的信息。
这样一次处理过程,也叫一个时间步,每次输入不同,但后一个时间步的输入是前一个时间步的输出。
双向RNN
如果遇到,下文反过来推理上文的场景就需要双向 RNN,例如:
- 早上难得好天气,适合(去打球/睡懒觉),可别叫醒我。
综合上下文,既然有 “别叫醒我” 跟在后面,显然 “睡懒觉” 的可能性大幅提高。
在这一类需要结合上下文,在正序、倒序两个方向上做推理的场景中,可以通过双向 RNN 结构,加入逆向推理机制。
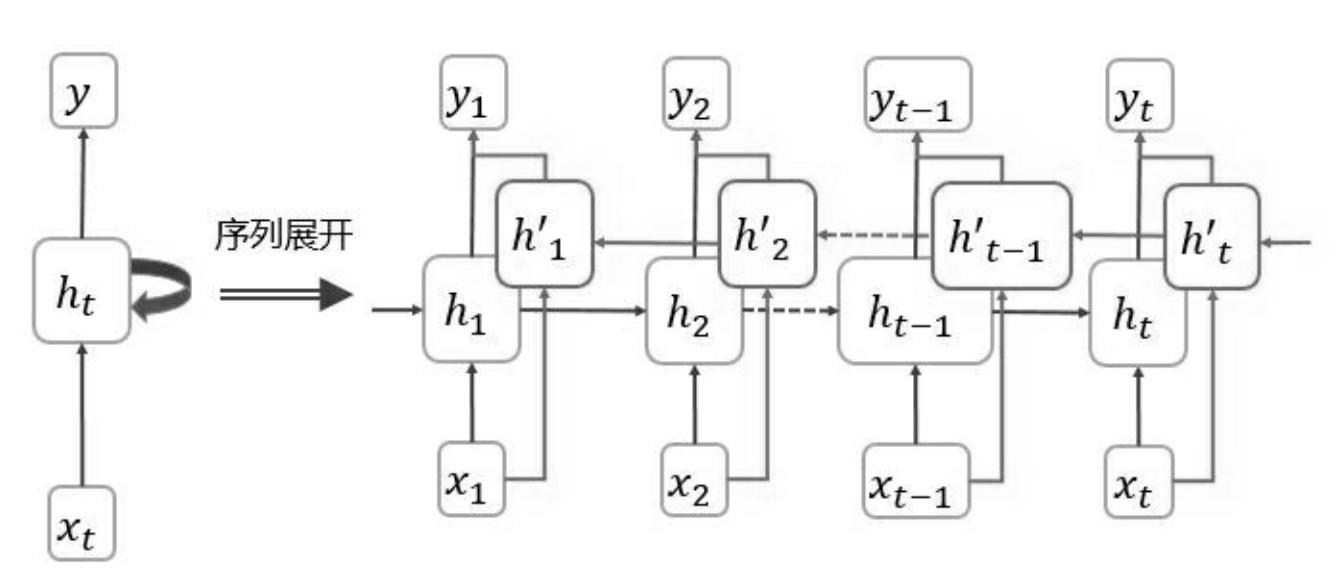
- h i h_i hi:表示正向
- h i ′ h'_i hi′:表示反向
同正方向序列上的权值参数一样,逆序列也有权参 W h x ′ 、 W h h ′ 、 W h y ′ W'_hx、W'_hh、W'_hy Whx′、Whh′、Why′,相应的参数量和隐藏节点个数扩展到单向模型的两倍。
俩者的区别只在于,计算激活值的方向不同, h i h_i hi 是从 1 1 1 到 t t t, h i ′ h'_i hi′ 是从 t t t 到 i i i。
- h t ′ = f ( W h x ′ x t + W h h ′ h t − 1 ′ + b ′ ) h'_t=f(W'_hxx_t+W'_hhh'_t-1+b') ht′=f(Whx′xt+Whh′ht−1′+b′)
- ···
- h 2 ′ = f ( W h x ′ x 2 + W h h ′ h 1 ′ + b ′ ) h'_2=f(W'_hxx_2+W'_hhh'_1+b') h