恒源云_attention decoder效果不佳时如何应对
Posted AI酱油君
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了恒源云_attention decoder效果不佳时如何应对相关的知识,希望对你有一定的参考价值。
文章来源 | 恒源云社区
原文地址 | ECCV 2020
原文作者 | 学习cv的小何
背景:
通常STR识别论文中的实验数据集来自真实街景图片,其中包含大量语义信息。那么在decode时利用attention机制的decoder往往可以很好地利用这些语义信息,从而避免将apple预测成0pple的情况。然而实际项目中并不一定都是语义信息丰富的文本图片,遇到随机字符的组合或者弱语义文本识别,经典识别方法可能出现错误的预测结果。
通常对于这种情况,我的习惯是使用CTC解码器。而今天介绍一篇来自商汤团队ECCV2020的文本识别论文《RobustScanner- Dynamically Enhancing Positional Clues for Robust Text Recognition》,提出了一种增强位置信息的方法,来解决这一问题。
动机:
作者发现目前的STR识别模型对于没有语义信息或者弱语义信息的文本识别效果不佳。而随后实验发现,基于attention的解码器中,对于不同的文本串每个time step的隐含状态(ht-即attention中的query)在同一个位置相似度很高,说明h编码了字符的位置信息。同时时序模型得到的h隐含状态,往往包含一定的语义信息。但实验发现随着文本串的长度增加,相邻h之间的余弦相似度变得越来越大,说明随着语义信息的增加(时间序列越靠后,积累的语义信息越多),这种位置信息反而降低了。因此作者认为面对没有多少语义信息的文本串,有必要尝试增加位置信息,降低过强语义信息导致atten并未准确定位到当前字符特征。最终实验证明,除了常规的数据集外,对于随机字符生成的数据集,本文的方法仍然可以较好识别文字。
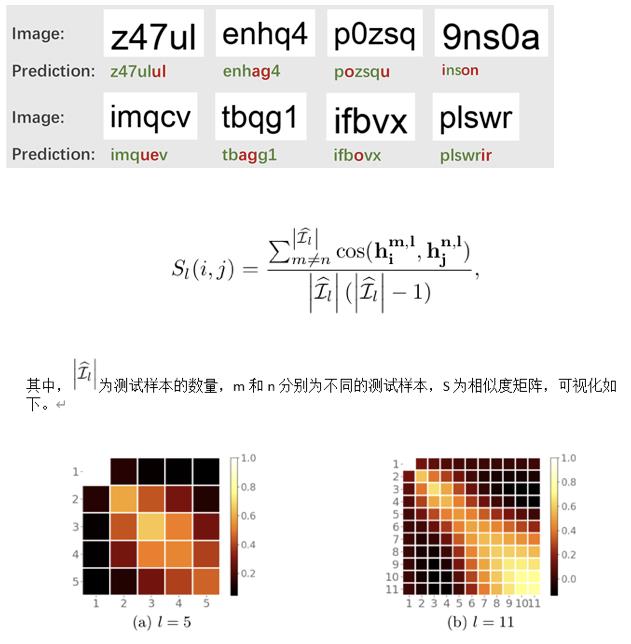
缺点:
对于语义信息较强的文本串,该方案可能会低于单纯依赖语义信息的atten解码器。实验结果显示,在SVT和SVTP上效果较差,原因在于这两个街道场景数据集中存在大量模糊字符,而它们的数据大多为有语义的单词,这种情况下通过语义进行猜测远比准确定位字符位置更为重要。
贡献:
解码器包含位置增强模块和经典的解码模块
设计动态融合模块来合并 两个解码器的输出。
方案介绍:
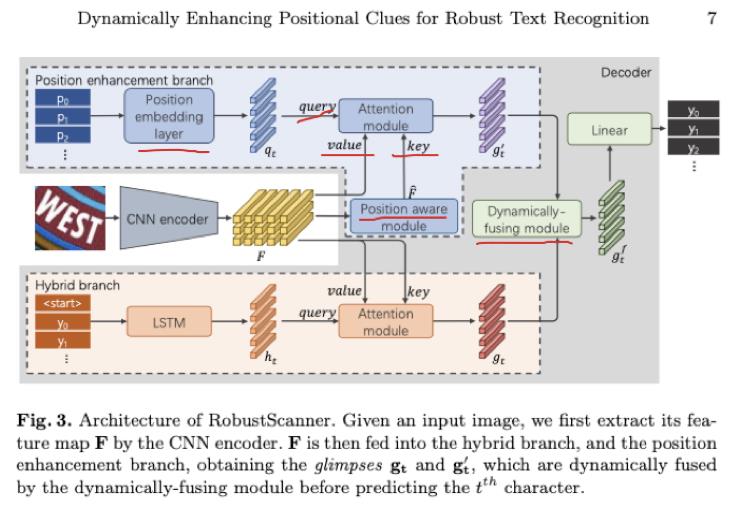
经典的识别模型结构:CNN encoder + hybrid branch decoder
RobustScanner:增加了position enhancement branch,增强query中的位置信息特征。最后将两个分支的输出gt和g’t 利用动态融合模块进行融合处理
下面具体介绍这两个模块
一、position enhancement branch
由position embedding layer、attention module、position aware module组成
1、position embedding layer 位置编码层
将当前的time step对应步数作为输入,得到位置编码向量。embedding层,输入one-hot向量,输出embedding向量。
作者对比了embedding层编码(可学习)和transformer中的三角函数position编码(不可学习)方式的表现,如下:

2、position aware module 位置模块
对编码器的输出特征进行增强,使其可以编码丰富的位置信息。虽然position embedding layer对文本中字符的index做了编码,但要想在encoder输出的feature map上准确定位第t个字符还是很困难。这需要全局信息。因为CNN的感受野有限,而且确定字符的index需要准确理解文本序列的方向、形状,因此作者选择两层单向LSTM,对feature map的每一行进行处理,使得输出可以编码位置信息。输出是attention module的key。
结构是双层单向LSTM,33conv + relu + 33conv

二、Dynamically-Fusing Module
结构如上图b。
融合方法方面,作者对比了concate和element-wise add。结果如下,动态融合效果最好

以上是关于恒源云_attention decoder效果不佳时如何应对的主要内容,如果未能解决你的问题,请参考以下文章