恒源云_[SimCSE]:对比学习,只需要 Dropout?
Posted AI酱油君
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了恒源云_[SimCSE]:对比学习,只需要 Dropout?相关的知识,希望对你有一定的参考价值。
文章来源 | 恒源云社区(恒源云,专注 AI 行业的共享算力平台)
原文地址 | Dropout
原文作者 | Mathor
要说2021年上半年NLP最火的论文,想必非《SimCSE: Simple Contrastive Learning of Sentence Embeddings》莫属。SimCSE的全称是Simple Contrastive Sentence Embedding
Sentence Embedding
Sentence Embedding一直是NLP领域的一个热门问题,主要是因为其应用范围比较广泛,而且作为很多任务的基石。获取句向量的方法有很多,常见的有直接将[CLS]位置的输出当做句向量,或者是对所有单词的输出求和、求平均等。但以上方法均被证明存在各向异性(Anisotropy)问题。通俗来讲就是模型训练过程中会产生Word Embedding各维度表征不一致的问题,从而使得获得的句向量也无法直接比较
目前比较流行解决这一问题的方法有:
- 线性变换:BERT-flow、BERT-Whitening。这两者更像是后处理,通过对BERT提取的句向量进行某些变换,从而缓解各向异性问题
- 对比学习:SimCSE。 对比学习的思想是拉近相似的样本,推开不相似的样本,从而提升模型的句子表示能力
Unsupervised SimCSE

SimCSE利用自监督学习来提升句子的表示能力。由于SimCSE没有标签数据(无监督),所以把每个句子本身视为相似句子。说白了,本质上就是
(
自
己
,
自
己
)
(自己,自己)
(自己,自己)作为正例、
(
自
己
,
别
人
)
(自己,别人)
(自己,别人)作为负例来训练对比学习模型。当然,其实远没有这么简单,如果仅仅只是完全相同的两个样本作正例,那么泛化能力会大打折扣。一般来说,我们会使用一些数据扩增手段,让正例的两个样本有所差异,但是在NLP中如何做数据扩增本身也是一个问题,SimCSE提出了一个极为简单优雅的方案:直接把Dropout当做数据扩增!
具体来说,
N
N
N个句子经过带Dropout的Encoder得到向量
h
1
(
0
)
,
h
2
(
0
)
,
…
,
h
N
(
0
)
\\boldsymbolh_1^(0),\\boldsymbolh_2^(0),…,\\boldsymbolh_N^(0)
h1(0),h2(0),…,hN(0),然后让这批句子再重新过一遍Encoder(这时候是另一个随机Dropout)得到向量
h
1
(
1
)
,
h
2
(
1
)
,
…
,
h
N
(
1
)
\\boldsymbolh_1^(1),\\boldsymbolh_2^(1),…,\\boldsymbolh_N^(1)
h1(1),h2(1),…,hN(1) ,我们可以
(
h
i
(
0
)
,
h
i
(
1
)
)
(\\boldsymbolh_i^(0),\\boldsymbolh_i^(1))
(hi(0),hi(1))视为一对(略有不同的)正例,那么训练目标为

其中,
sim
(
h
1
,
h
2
)
=
h
1
T
h
2
∥
h
1
∥
⋅
∥
h
2
∥
\\textsim(\\boldsymbolh_1, \\boldsymbolh_2)=\\frac\\boldsymbolh_1^T\\boldsymbolh_2\\Vert \\boldsymbolh_1\\Vert \\cdot \\Vert \\boldsymbolh_2\\Vert
sim(h1,h2)=∥h1∥⋅∥h2∥h1Th2。实际上式(1)如果不看
−
log
-\\log
−log和
τ
\\tau
τ的部分,剩下的部分非常像是
Softmax
\\textSoftmax
Softmax。论文中设定
τ
=
0.05
\\tau = 0.05
τ=0.05,至于这个
τ
\\tau
τ有什么作用,我在网上看到一些解释:
- 如果直接使用余弦相似度作为logits输入到 Softmax \\textSoftmax Softmax,由于余弦相似度的值域是 [ − 1 , 1 ] [-1,1] [−1,1],范围太小导致 Softmax \\textSoftmax Softmax无法对正负样本给出足够大的差距,最终结果就是模型训练不充分,因此需要进行修正,除以一个足够小的参数 τ \\tau τ将值进行放大
- 超参数 τ \\tau τ会将模型更新的重点,聚焦到有难度的负例,并对它们做相应的惩罚,难度越大,也即是与 h i ( 0 ) h_i^(0) hi(0)距离越近,则分配到的惩罚越多。其实这也比较好理解,我们将 sim ( h i ( 0 ) , h j ( 1 ) ) \\textsim(\\boldsymbolh_i^(0),\\boldsymbolh_j^(1)) sim(hi(0),hj(1))除以 τ \\tau τ相当于同比放大了负样本的logits值,如果 τ \\tau τ足够小,那么那些 sim ( h i ( 0 ) , h j ( 1 ) ) \\textsim(\\boldsymbolh_i^(0),\\boldsymbolh_j^(1)) sim(hi(0),hj(1))越靠近1的负样本,经过 τ \\tau τ的放大后会占主导
个人觉得没有严格的数学证明,单从感性的角度去思考一个式子或者一个符号的意义是不够的,因此在查阅了一些资料后我将 τ \\tau τ这个超参数的作用整理成了另一篇文章:Contrastive Loss中参数 τ \\tau τ的理解
总结一下SimCSE的方法,个人感觉实在是太巧妙了,因为给两个句子让人类来判断是否相似,这其实非常主观,例如:“我喜欢北京”跟“我不喜欢北京”,请问这两句话到底相不相似?模型就像是一个刚出生的孩子,你教它这两个句子相似,那它就认为相似,你教它不相似,于是它以后见到类似的句子就认为不相似。此时,模型的性能或者准确度与训练过程、模型结构等都没有太大关系,真正影响模型预测结果的是人,或者说是人标注的数据
但是如果你问任何一个人“我喜欢北京”跟“我喜欢北京”这两句话相不相似,我想正常人没有说不相似的。SimCSE通过Dropout生成正样本的方法可以看作是数据扩增的最小形式,因为原句子和生成的句子语义是完全一致的,只是生成的Embedding不同而已。这样做避免了人为标注数据,或者说此时的样本非常客观
Alignment and Uniformity
对比学习的目标是从数据中学习到一个优质的语义表示空间,那么如何评价这个表示空间的质量呢?Wang and Isola(2020)提出了衡量对比学习质量的两个指标:alignment和uniformity,其中alignment计算
x
i
x_i
xi和
x
i
+
x_i^+
xi+的平均距离:
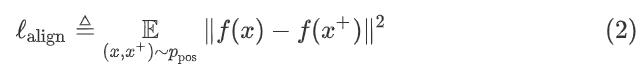
而uniformity计算向量整体分布的均匀程度:
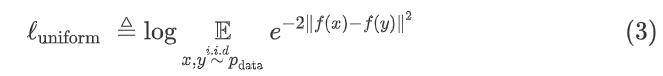

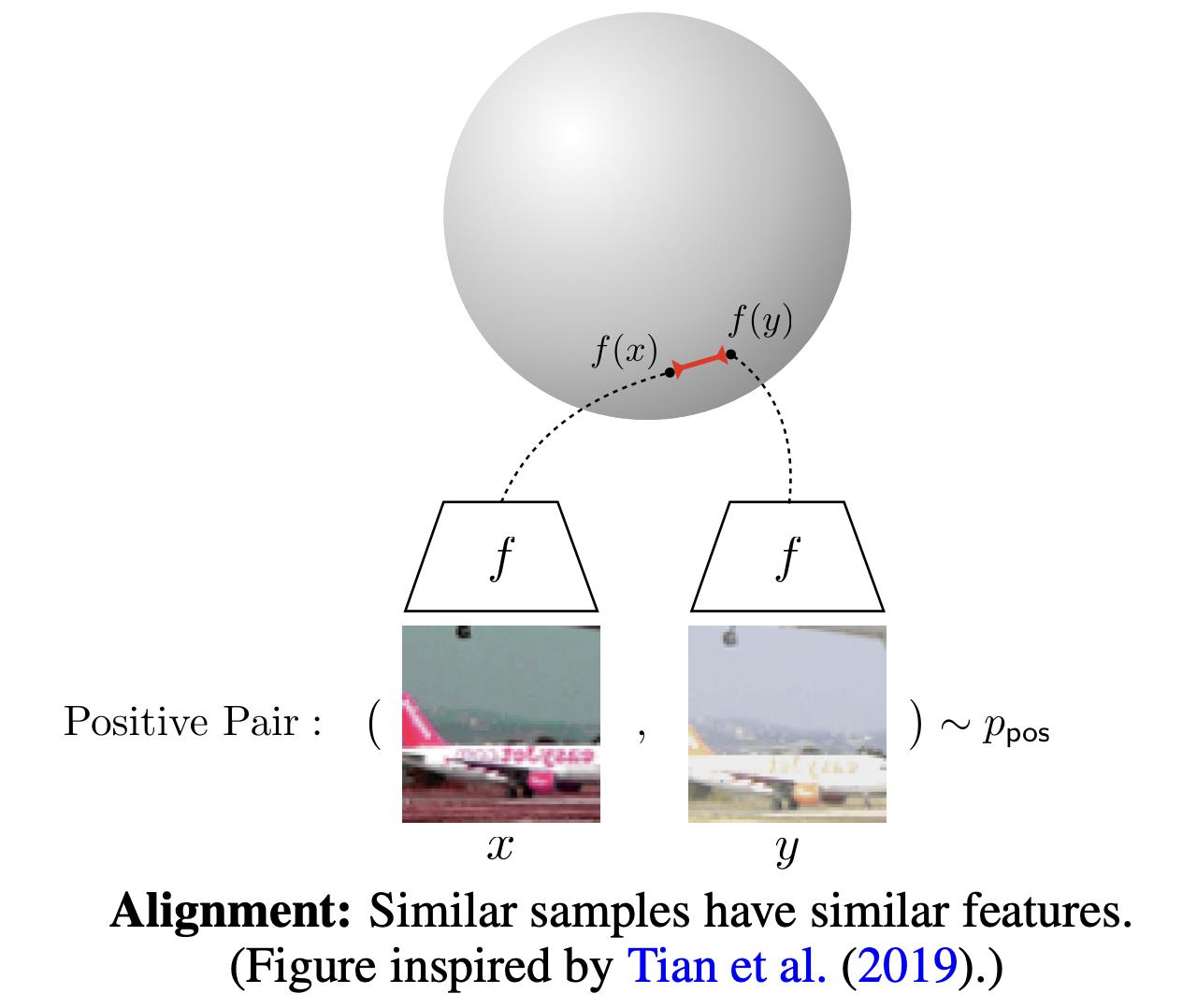
我们希望这两个指标都尽可能低,也就是一方面希望正样本要挨得足够近,另一方面语义向量要尽可能地均匀分布在超球面上,因为均匀分布的信息熵最高,分布越均匀则信息保留的越多。作者从维基百科中随机抽取十万条句子来微调BERT,并在STS-B dev上进行测试,实验结果如下表所示:
其中None是作者提出的随机Dropout方法,其余方法均是在None的基础上对
x
i
+
x_i^+
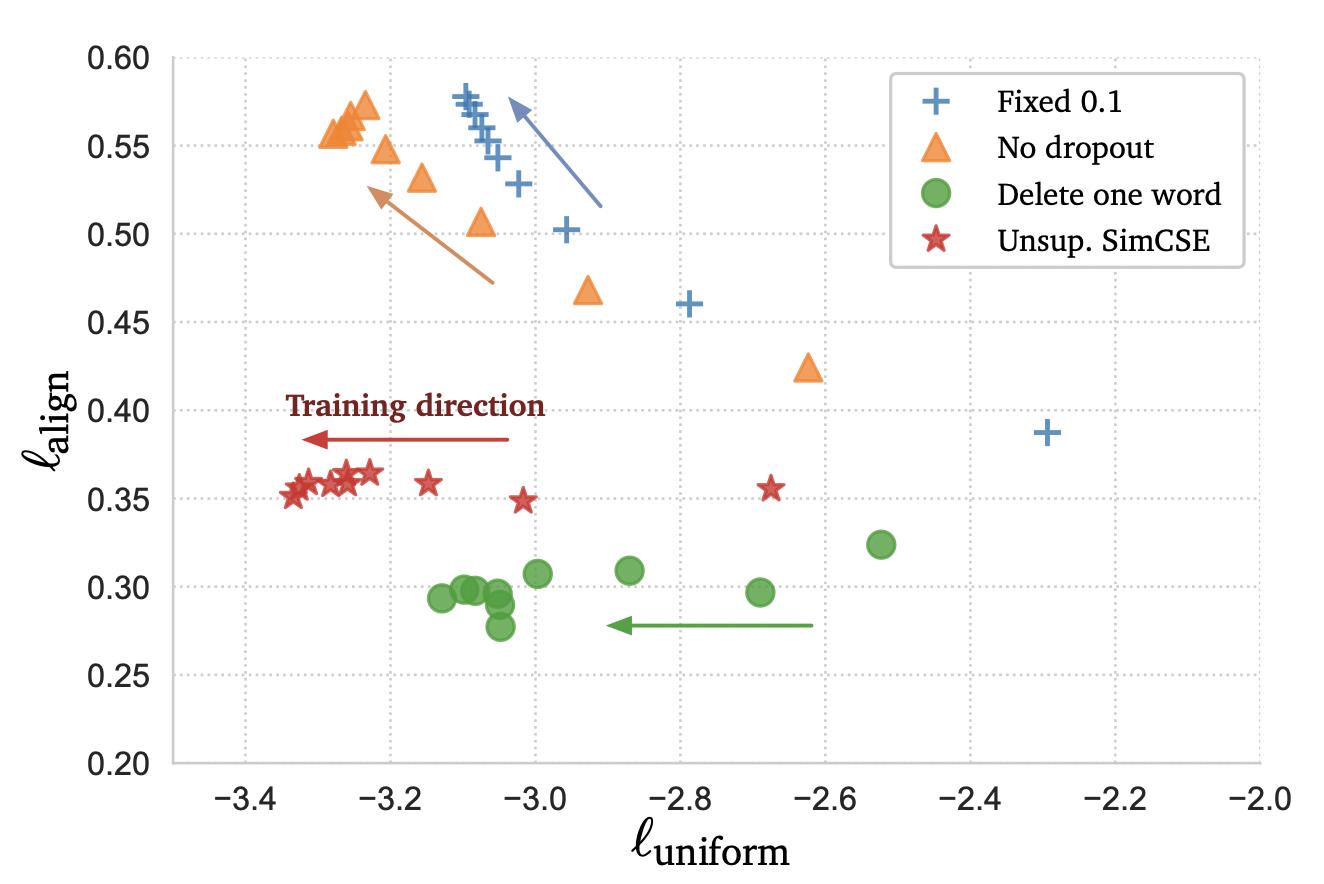
xi+进行改变,可以看到,追加显式数据扩增方法均会不同程度降低模型性能,效果最接近Dropout的是删除一个单词,但是删除一个单词并不能对uniformity带来很大的提升,作者也专门做了个实验来证明,如下图所示:
Connection to Anisotropy
近几年不少研究都提到了语言模型生成的语义向量分布存在各向异性的问题,在探讨为什么Contrastive Learning可以解决词向量各向异性问题前,我们先来了解一下,什么叫各向异性。具体来说,假设我们的词向量设置为2维,如果各个维度上的基向量单位长度不一样,就是各向异性(Anisotropy)
例如下图中,基向量是非正交的,且各向异性(单位长度不相等),计算
x
1
x
x_1x
x1x与
x
2
x_2
x2的cos相似度为0,
x
1
x_1
x1与
x
3
x_3
x3的余弦相似度也为0。但是我们从几何角度上看,
x
1
x_1
x1与
x
3
x_3
x3其实是更相似的,可是从计算结果上看,
x
1
x_1
x1与
x
2
x_2
x2和
x
3
x_3
x3的相似度是相同的,这种不正常的原因即是各向异性造成的

SimCSE的作者证明了当负样本数量趋于无穷大时,对比学习的训练目标可以渐近表示为:

稍微解释一下这个式子,为了方便起见,接下来将 1 τ E ( x , x + ) ∼ p pos [ f ( x ) T f ( x + ) ] \\frac1\\tau\\mathop\\mathbbE\\limits_(x,x^+)\\sim p_\\textpos\\left[f(x)^Tf(x^+)\\right] τ1(x,x+)∼pposE[f(x)Tf(x+)]称为第一项, E x ∼ p data [ log E x − ∼ p data [ e f ( x ) T f ( x − ) / τ ] ] \\mathop\\mathbbE\\limits_x\\sim p_\\textdata\\left[\\log \\mathop\\mathbbE\\limits_x^-\\sim p_\\textdata\\left[e^f(x)^Tf(x^-)/\\tau\\right]\\right] x∼pdataE[log以上是关于恒源云_[SimCSE]:对比学习,只需要 Dropout?的主要内容,如果未能解决你的问题,请参考以下文章