恒源云(GpuShare)_MaskFormer:语义分割可以不全是像素级分类
Posted AI酱油君
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了恒源云(GpuShare)_MaskFormer:语义分割可以不全是像素级分类相关的知识,希望对你有一定的参考价值。
文章来源 | 恒源云社区
原文地址 | MaskFormer
原文作者 | 咚咚
论文:Per-Pixel Classification is Not All You Need for Semantic Segmentation
论文地址:https://arxiv.org/pdf/2107.06278.pdf
代码地址: https://bowenc0221.github.io/maskformer

摘要
- 目前研究多将语义分割算法作为一种像素级的分类算法,而将实例分割作为一种mask分类算法
- 论文的重要观点是:mask分类任务能够同时有效解决语义和实例级的分割任务
- 基于上述观念,提出了MaskFormer,一种预测二值mask(每个mask用于预测一个类别)的mask分类模型
- 实验显示,MaskFormer在ADE20K和COCO分割任务上实现state-of-the-art
从像素级分类到mask级分类
- 首先介绍像素级分类和mask级分类
- 随后介绍本文的mask级分类算法
- 最后提出了两个不同的前向传播算法
像素级分类
大家应该对像素级分类很熟悉了,可以用公式表达为 y = p i ∣ p i ∈ Δ k i = 1 H ⋅ W y=\\lbrace p_i|p_i \\in\\Delta^k\\rbrace_i=1^H \\cdot W y=pi∣pi∈Δki=1H⋅W,其中 Δ K \\Delta^K ΔK,具体含义就是一张图像上每个像素点的K类别概率分布
最后使用cross entropy对每个像素进行loss计算
MASK级分类

mask级分类将分割任务拆分为两个部分:
- 将图像分割成N个区域(N不需要等于类别K),使用二进制 m i ∣ m i ∈ [ 0 , 1 ] H × W i = 1 N \\lbrace m_i|m_i \\in[0,1]^H \\times W\\rbrace_i=1^N mi∣mi∈[0,1]H×Wi=1N表示
- 这N个区域的每个区域内部是属于同一个类别,所以还需要对其进行类别预测,可以表示为 z = ( p i , m i ) i = 1 N z=\\lbrace (p_i,m_i)\\rbrace_i=1^N z=(pi,mi)i=1N,这里的类别概率分布 p i ∈ Δ K + 1 p_i \\in \\Delta^K+1 pi∈ΔK+1包含无对象no object 类别
由于N不需要等于类别K,这就意味着会存在多个区域属于同一个类别,这时mask级分类可以适用于语义分割和实例级分割任务
上述就是mask级分类的两个组成部分,但这会引出下一个问题,如何构造标签?
- 将一般标签改造成 z g t = ( c i g t , m i g t ) ∣ c i g t ∈ 1 , … , K , m i g t ∈ 0 , 1 H × W i = 1 N g t z^gt=\\lbrace (c_i^gt,m_i^gt)|c_i^gt \\in \\1,…,K\\,m_i^gt \\in \\ 0,1\\^H \\times W \\rbrace_i=1^N^gt zgt=(cigt,migt)∣cigt∈1,…,K,migt∈0,1H×Wi=1Ngt,其中 N g t N^gt Ngt可以认为是类别个数
- 预测生成的区域块数量N一般会大于标签中的区域块 N g t N^gt Ngt,为了后续能够进行对一对匹配,所以两者数量需要一致,因此添加一系列无对象tokens使两者数量相同
进一步就是要考虑如何将标签和预测结果中的不同区域进行匹配
- 作者发现使用二值匹配算法bipartite matching 比使用固定匹配算法trivial fixed matching 算法要好
- 借鉴DETR的匹配思路,联合类别和mask预测对i和j进行匹配: − p i ( C j g t ) + L m a s k ( m i , M j g t ) -p_i (C_j^gt)+\\mathcalL_mask(m_i,M_j^gt) −pi(Cjgt)+Lmask(mi,Mjgt)
基于匹配的结果,最终的损失函数为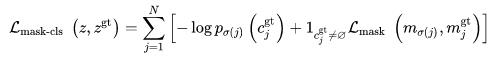
MASKFORMER

整个模型分成三个模块(如上图所示):
- 像素级模块用于提取像素级特征嵌入
- Transformer模块,用于计算N个区域嵌入
- 分割模块,基于上述两个嵌入计算预测类别
像素级模块
就是一个编码器-解码器结构,输入大小为H×W的图像,输出为
ε
p
i
x
e
l
∈
R
c
ε
×
H
×
W
\\varepsilon_pixel \\in \\mathbb R ^c_\\varepsilon \\times H \\times W
εpixel∈Rcε×H×W
的特征图
Transformer模块
将像素级模块中编码器的输出特征图和N个可学习的位置嵌入作为Transformer解码器的输入, 输出为
Q
∈
R
C
Q
×
N
\\mathcal Q \\in \\mathbbR^C_\\mathcalQ \\times N
Q∈RCQ×N
分割模块
- 对于Transformer模块的输出Q,使用线性分类层和softmax进行类别输出,得到类别概率 p i ∈ Δ K + 1 i = 1 N \\lbrace p_i \\in\\Delta^K+1\\rbrace _i=1^N pi∈ΔK+1i=1N
- 使用带有两个隐藏层的MLP将Q转化为 ε m a s k ∈ R c ε × N \\varepsilon_mask \\in \\mathbb R ^c_\\varepsilon \\times N εmask∈Rcε×N,并与 ε p i x e l \\varepsilon_pixel εpixel进行点乘和sigmoid操作,得到二值mask预测, m i [ h , w ] = s i g m o i d ( ε m a s k [ : , i ] T ⋅ ε p i x e l [ : , h , w ] ) m_i[h,w]=sigmoid(\\varepsilon_mask[:,i]^T\\cdot\\varepsilon_pixel[:,h,w]) mi[h,w]=sigmoid(εmask[:,i]T⋅εpixel[:,h,w]),其中每个预测值为 m i ∈ [ 0 , 1 ] H × W m_i \\in[0,1]^H \\times W mi∈[0,1]H×W,一共有N个
训练过程中,联合使用cross entropy classification loss 和binary mask loss L mask \\mathcalL_\\text mask Lmask (与DETR一样,联合focal loss和dice loss权重求和)
前向传播过程
提出了两种前向传播算法
- 针对全景和语义分割,提出了general inference
- 专门针对语义分割,提出了semantic inference
作者并发现,前向传播的策略更大程度上依赖于评价指标而不是任务
General inference 以上是关于恒源云(GpuShare)_MaskFormer:语义分割可以不全是像素级分类的主要内容,如果未能解决你的问题,请参考以下文章 恒源云(Gpushare)_UNIRE:一种可以共享标签空间的方法
上文所述,我们知道
p
i
∈
Δ
K
+
1
i
=
1
N
,
m
i
∈
[
0
,
1
]
H
×
W
\\lbrace p_i \\in\\Delta^K+1\\rbrace _i=1^N,m_i \\in[0,1]^H \\times W
pi∈ΔK+1i=1N,m<