恒源云(GpuShare)_无监督的QG方法
Posted AI酱油君
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了恒源云(GpuShare)_无监督的QG方法相关的知识,希望对你有一定的参考价值。
文章来源 | 恒源云社区
原文地址 | 通过摘要信息问题生成改进无监督问答
原文作者 | Mathor
上海于昨日宣布要开始在全市范围内开展新一轮切块式、网格化核酸筛查!【恒源云】云墩墩☁️ 提醒小伙伴们,不管居家还是出门,都要注意防疫哦~
也许是居家的小伙伴真的很多,也许是春天来了大家积极性增强,社区技术贴那是一个接一个的发啊!

今天呢,给大家带来老朋友Mathor的文章。
正文开始
1 Abstract
问题生成(QG)是为给定的 < p a s s a g e , a n s w e r > <passage,answer> <passage,answer>pair 生成似是而非的问题的任务。基于模板的QG使用语言信息启发式将陈述句转换为疑问句,对于监督QG使用现有的问答(QA)数据集来训练系统,以生成给定段落和答案的问题。
- 启发式缺点:生成的问题与它们的声明性对应问题紧密相关。
- 监督方法:它们与用作训练数据的QA数据集的域/语言紧密相关。
本文提出无监督的QG方法:使用从摘要中启发式生成的问题作为QG系统的训练数据的来源。(利用启发式方法将陈述性摘要句子转化为合适的问句)
- 本文使用的启发式方法:依赖句法分析、命名实体识别、语义角色标注等。
通过无监督QG产生问题,然后将产生的问题与原始文章结合,以端到端训练神经QG模型。
1 Introduction
问题生成的目的是在给定一组输入段落和相应答案的情况下产生有意义的问题。
早期QG的研究基于模板生成,但这样的问题缺乏多样性,并且与相应的陈述句子有很高的词汇重叠度,例如: S t e p h e n H a w k i n g a n n o u n c e d t h e p a r t y i n t h e m o r n i n g Stephen\\ Hawking\\ announced\\ the\\ party\\ in\\ the\\ morning Stephen Hawking announced the party in the morning 的句子生成的问题,以Stephen Hawking(斯蒂芬·霍金)为候选答案跨度,可能是Who announced the party in the morning?(谁在早上宣布了聚会?),可以看到生成的问题和陈述句之间有很高的词汇重叠。这在问题系统中是不可取的,因为问题中强烈的词汇线索会使它成为一种很差的真正意义上的理解。
后来神经seq2seq模型成为QG的主导,通常从人类创建的QA数据集获得 < p a s s a g e , a n s w e r , q u e r y > <passage,answer,query> <passage,answer,query>三元组训练,这种方法限制了对数据集的领域和语言的应用,并且需要大量的时间和资金。
本文提出一种新的无监督方法,将QG描述成一个摘要-提问过程(summarization-questioning)。通过使用免费获得的摘要数据,对摘要进行依存关系分析、命名实体识别和语义角色标注,然后应用启发式方法根据解析的摘要生成问题。
图一显示了一个实例(通过使用不同候选答案span的摘要句子的语义角色标注启发式生成的示例问题):
问题要从摘要中产生而不是原始段落中,因此摘要是作为问题和段落之前的桥梁存在的,最后生成的问题和段落的词汇重叠部分也较少,这种方法是可行的,因为摘要中包含了段落中最重要的信息,在语义上也和段落接近。另外摘要数据要比QA数据集获取要容易的多,因为许多QA数据集是专门为训练QA系统而创建的。
2 Realated Work
在无监督QA中,使用基于QG模型的合成数据而不是现有的QA数据集来训练QA模型。代替求助于现有的QA数据集,采用了无监督的QG方法,例如无监督的神经机器翻译Unsupervised Question Answering by Cloze Translation、Template-Based Question Generation from Retrieved Sentences for Improved Unsupervised Question Answering。Harvesting and Refining Question-Answer Pairs for Unsupervised QA提出了基于模板/规则的问题生成方法,并将检索到的段落和被引用的段落作为源段落,以缓解段落和问题之间的词汇相似问题。
3 Methodology
本文提出的方法使用合成的QG数据,然后使用一些启发式方法从摘要数据创建QG数据来训练QG模型。
图2中展示了本文的模型(答案和问题是基于问题生成启发式的摘要生成的,答案与文章结合形成编码器的输入,问题被用作解码器输出的ground-truth):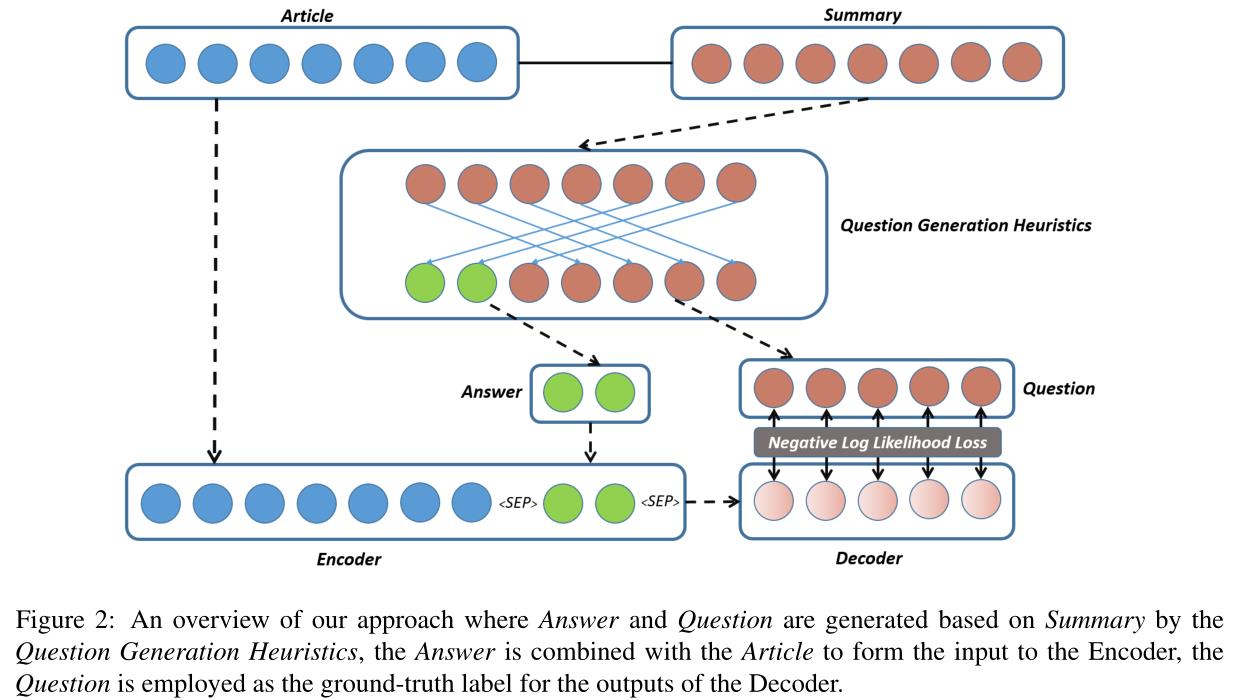
3.1 QUESTION GENERATION
为了避免生成与相应说明性语句高度相似的琐碎问题,本文采用摘要数据作为连接生成的问题和原始文章的桥梁。
- 对摘要句进行依存分析(DP),然后是命名实体识别和语义角色分析(SRL)
- DP被用来识别主要动词(动词根)和其他成分(助动词)的一种手段。
- NER负责摘要句子中的所有实体,以便于发现要生成的最合适的问句。
- 语句分析的关键是SRL,被用来获取摘要句子的所有语义框架,每个框架有一个动词和一组论元组成,这些论元对应于句子中的短语。
- 例如,参数可以包括AgentAgentAgent(其发起由动词描述的动作)、PatientPatientPatient(其进行该动作)以及一组修饰符参数,如ARG-TMP或ARG-LOC
- 根据论元类型和NER标签从论元生成疑问句,这意味着可以共同确定wh-words
图1中的示例:给出SRL分析[
U
2
’
s
l
e
a
d
s
i
n
g
e
r
B
o
n
o
A
R
G
−
0
U2’s\\ lead\\ singer\\ Bono\\ ARG-0
U2’s lead singer Bono ARG−0]has [
h
a
d
V
E
R
B
had\\ VERB
had VERB] [
e
m
e
r
g
e
n
c
y
s
p
i
n
a
l
s
u
r
g
e
r
y
A
R
G
−
1
emergency\\ spinal\\ surgery\\ ARG-1
emergency spinal surgery ARG−1] [
a
f
t
e
r
s
u
f
f
e
r
i
n
g
a
n
i
n
j
u
r
y
w
h
i
l
e
p
r
e
p
a
r
i
n
g
f
o
r
t
o
u
r
d
a
t
e
s
A
R
G
−
T
M
P
after\\ suffering\\ an\\ injury\\ while\\ preparing\\ for\\ tour\\ dates\\ ARG-TMP
after suffering an injury while preparing for tour dates ARG−TMP]。根据这三个论点可以生成图1中所示的三个问题。
3.2 TRAINING A QUESTION GENERATION MODEL
本文使用的摘要数据由 < p a s s a g e − s u m m a r y > <passage-summary> <passage−summary>对组成。问题是使用3.1节中描述的启发式方法从摘要中生成的,这样就有了 < p a s s a g e − s u m a r y > <passage-sumary> <passage−sumary>对和 < s u m m a r y − q u e s t i o n − a n s w e r > <summary-question-answer> <summary−question−answer>三元组,然后我们将它们组合成 < p a s s a g e − a n s w e r − q u e s t i o n > <passage-answer-question> <passage−answer−question>三元组,以训练QG模型。
本文训练一个端到端的seq2seq模型,而不是部署一个管道,首先生成摘要,然后再生成问题,以消除生成过程中错误积累的风险。通过使用这些QG数据来训练神经生成模型,期望该模型学习summary和问题生成的组合。换句话说,这样的知识可以通过QG数据隐含地注入到神经生成模型中。
为了训练问题生成模型,本文将每个段落和答案连接起来,形成一个序列:
p
a
s
s
a
g
e
<
S
E
P
>
a
n
s
w
e
r
<
S
E
P
>
passage<SEP>answer<SEP>
passage<SEP>answer<SEP>,其中
<
S
E
P
>
<SEP>
<SEP>是用于分隔段落和答案的特殊符号。这个序列是输入,目标输出(目标)是question。本文使用BART进行生成,通过以下负对数似然损失函数进行优化:

其中
q
i
q_i
qi是question的第
i
i
i个token,C、AC、AC、A表示上下文和答案。
4 Experiments
4.1 EXPERIMENT SETUP
4.1.1 Question Generation
Datasets本文使用BBC新闻网站抓取的XSUM的新闻摘要数据来测试提出的方法。XSUM包括226,711个 < p a s s a g e − s u m m a r y > <passage-summary> <passage−summary>对,每个摘要包含一个句子。
QG Details使用AllenNLP来获取摘要句子的依存关系树、命名实体和语义角色标签。
删除满足以下三个条件中的三元组:
- 超过480个token的文章(超过最大BART输入长度);
- 文章中答案跨度中不超过55%的token的文章(以确保答案和短文之间有足够的词汇重叠)
- 5个记号以下的问题(非常短的问题可能删除了太多的信息);
一共产生了14,830个 < p a s s a g e − a n s w e r − q u e s t i o n > <passage-answer-question> <passage−answer−question>个三元组
4.1.2 Unsupervised QA
Datasets在六个抽取的问答数据集上进行了实验,分别是SQuAD1.1、NewsQA、Natural Questions、TriviaQA、BioASQ和DuoRC。
本文使用SQuAD1.1、NewsQA和TriviaQA的官方数据,对于Natural Questions、BioASQ和DuoRC,使用MRQA发布的预处理数据。
Unsupervised QA Training Details为了生成合成的QA训练数据,本文利用维基转储(Wikidumps),首先删除所有html标签和引用链接,然后提取长度超过500个字符的段落,从维基转储的所有段落中抽取60k个段落。使用Spacy和AllenNLP的NER工具包来提取段落中的实体提及。
然后,删除满足以下三个条件中的一个或多个的段落,即答案对:
- 少于20个单词而超过480个单词的段落;
- 没有提取答案的段落,或者由于文本tokenization而提取的答案不在段落中;
- 由单个代词组成的答案。
将段落和答案连接成形式 p a s s a g e < S E P > a n s w e r < S E P > passage<SEP>answer<SEP> passage<SEP>answer<SEP>的序列,然后输入到训练好的BART-QG模型中获得相应的问题。这产生了20k个合成QA对,然后将其用于训练无监督QA模型。
4.2 RESULTS
使用生成的2万个合成问答对来训练BERT QA模型,并首先在基于维基百科的三个基准问答数据集SQuAD1.1、Natural Questions和TriviaQA的验证集上验证了该模型的性能。本文方法的结果如表1和表2所示。

无监督的基线:
- Unsupervised Question Answering by Cloze Translation采用无监督神经机器翻译训练QG模型,生成4M个合成QA实例来训练QA模型
- Harvesting and Refining Question-Answer Pairs for Unsupervised QA使用依存关系树来生成问题,并使用被引用的文档作为段落
4.3 EFFECT OF DIFFERENT HEURISTICS不同启发式的效果
- N a i v e − Q G \\mathrmNaive-QG Naive−QG只使用摘要句作为上下文(不是原始段落 ),只用适当的问句替换答案的span。例如 S t e p h e n H a w k i n g a n n o u n c e d t h e p a r t y i n t h e m o r n i n g Stephen\\ Hawking\\ announced\\ the\\ party\\ in\\ the\\ morning Stephen Hawking announced the party in the morning的句子,以 p a r t y party party为答案span, N a i v e − Q G \\mathrmNaive-QG Naive−QG产生的问题会是 S t e p h e n H a w k i n g a n n o u n c e d w h a t i n t h e m o r n i n g ? Stephen\\ Hawking\\ announced\\ what\\ in\\ the\\ morning? Stephen Hawking announced what in the morning?。采用摘要句作为输入,问题作为目标输出,形成QG训练数据。
-
S
u
m
m
a
r
y
−
Q
G
Summary-QG
Summary−QG使用摘要的原
以上是关于恒源云(GpuShare)_无监督的QG方法的主要内容,如果未能解决你的问题,请参考以下文章
恒源云(Gpushare)_UNIRE:一种可以共享标签空间的方法
恒源云(Gpushare)_UNIRE:一种可以共享标签空间的方法