论文泛读199将预训练的 Transformers 微调为变分自动编码器
Posted 及时行樂_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文泛读199将预训练的 Transformers 微调为变分自动编码器相关的知识,希望对你有一定的参考价值。
贴一下汇总贴:论文阅读记录
论文链接:《Finetuning Pretrained Transformers into Variational Autoencoders》
一、摘要
文本变分自动编码器 (VAE) 因后验崩溃而臭名昭著,这种现象是模型的解码器学会忽略来自编码器的信号。因为众所周知,富有表现力的解码器会加剧后部崩溃,所以 Transformer 作为文本 VAE 的组件的采用有限。现有的研究将 Transformers 合并到文本 VAE 中(Li 等人,2020 年;Fang 等人,2021 年)使用大规模预训练减轻后部塌陷,这种技术在没有大量计算资源的情况下对大多数研究社区来说是不可用的。我们提出了一个简单的两阶段训练方案,只需微调即可将序列到序列的 Transformer 转换为 VAE。由此产生的语言模型在某些内部指标上可与大规模预训练的基于 Transformer 的 VAE 竞争,而在其他指标上则达不到要求。为了促进培训,我们全面探讨了文献中常见的后部塌陷缓解技术的影响。我们发布代码以实现可重复性。
二、结论
在文献中,对于KL在训练V-AE中的最佳值还没有一致的意见。总的来说,我们发现在两个阶段0.15和0.4之间的去噪方案,加上低(0.5) KL阈值,在重建和潜在表示质量之间取得了良好的平衡。
三、模型
VAE模型:
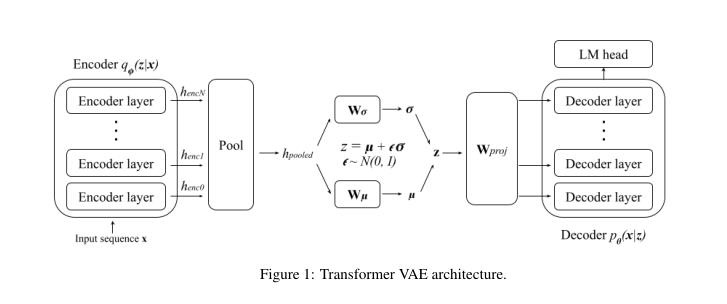
- KL损失的权重被设置为零,使得我们的模型的目标函数类似于AE的目标函数。比较了不同的输入去噪百分比、编码器池策略、潜在维度大小和解码器冻结配置。
- 恢复KL损失,并进行全VAE训练。我们比较了不同的输入去噪百分比、编码器池策略、KL退火计划和KL阈值。
以上是关于论文泛读199将预训练的 Transformers 微调为变分自动编码器的主要内容,如果未能解决你的问题,请参考以下文章