论文泛读103文本摘要的噪声一致性训练
Posted 及时行樂_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文泛读103文本摘要的噪声一致性训练相关的知识,希望对你有一定的参考价值。
贴一下汇总贴:论文阅读记录
论文链接:《Noised Consistency Training for Text Summarization》
一、摘要
神经抽象摘要方法通常需要大量标记的训练数据。然而,由于时间、财务和专业知识的限制,标记大量摘要数据通常是令人望而却步的,这限制了摘要系统在实际应用中的实用性。在本文中,我们认为可以通过半监督方法克服这种限制:一致性训练,即利用大量未标记数据来提高小语料库上监督学习的性能。一致性正则化半监督学习可以将模型预测正则化为对应用于输入文章的小噪声保持不变。通过添加噪声未标记语料库来帮助规范一致性训练,该框架在不使用完整数据集的情况下获得了比较性能。
二、结论
我们的工作表明,使用无标签数据来提高抽象摘要模型的性能是可行的。我们提出了一种新的观点,即有效地使用一致性训练来改进在标签不足的数据集上的监督文本摘要。通过将简单的噪声注入操作替换为高级的数据增强方法,例如反向翻译,我们的方法在相同的一致性训练框架下,在具有部分标记和部分未标记数据的数据集之间带来了实质性的改进。我们的方法在不使用完整数据集的情况下获得了比较性能。未来的工作包括将我们的一致性训练框架移植到其他自然语言生成任务中,比如问答和对话生成。
三、简介
自动文本摘要的一个基本要求是,它通常需要大量带标签的数据才能正常工作。
利用大量未标记数据来解决文本摘要任务中标注不足的弱点的有效方法。
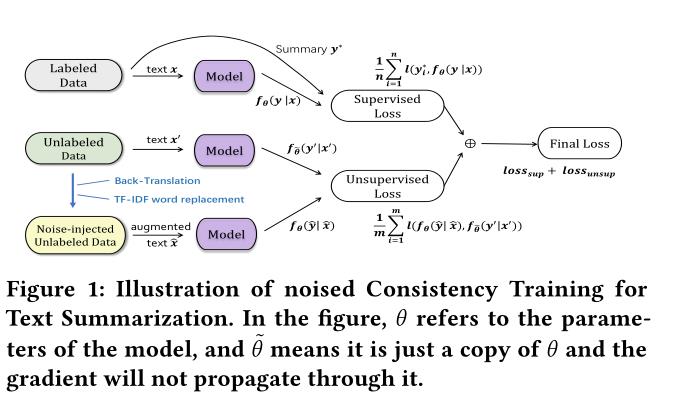
半监督学习的一致正则化利用未标记的数据并采用数据扩充方法来注入有噪声的数据,然后通过鼓励一致的预测来实施摘要模型以正则化半监督学习。
将未标记的文章转化为原始样本和噪声样本,以提高对大规模未标记语料库的文本摘要的监督学习。
- 反向翻译
将A翻译成B,再翻译成A - 单词替换与TF-IDF
选择分数低的替换单词
模型框架:
以上是关于论文泛读103文本摘要的噪声一致性训练的主要内容,如果未能解决你的问题,请参考以下文章