论文泛读180反向翻译任务自适应预训练:提高文本分类的准确性和鲁棒性
Posted 及时行樂_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文泛读180反向翻译任务自适应预训练:提高文本分类的准确性和鲁棒性相关的知识,希望对你有一定的参考价值。
贴一下汇总贴:论文阅读记录
一、摘要
在大型文本语料库上预训练并在下游文本语料库上进行微调并在下游任务上进行微调的语言模型 (LM) 已成为若干自然语言处理 (NLP) 任务的事实上的训练策略。最近,一种使用任务相关数据重新训练预训练语言模型的自适应预训练方法显示出显着的性能改进。然而,由于用于重新预训练 LM 的数据量相对较少,当前的自适应预训练方法在任务分布上存在欠拟合。为了完全使用自适应预训练的概念,我们提出了一种反向翻译任务自适应预训练 (BT-TAPT) 方法,该方法通过使用反向翻译来扩展任务数据来增加用于 LM 重新预训练的任务特定数据量。 LM 到目标任务域。
二、结论
在本文中,我们提出了一种新的自适应预处理方法——BT-TAPT,用于在任务数据不足时将最小均方误差推广到任务域。与仅使用与任务相关的未标记数据的TAPT形成对比的是,提议的 BT-TAPT基于反向翻译生成增强数据,并将其用于进一步重新预处理LMs。
在六个文本分类数据集上的实验表明,该算法不仅提高了分类精度,而且减小了偏差。此外,BT-TAPT算法对于小数据集更为实用,并且对各种噪声具有鲁棒性。未来的工作将考虑将BT-TAPT应用于其他自然语言处理任务,如问答或摘要。
三、model
BT-TAPT过程:对于预处理后的LM,首先,我们用任务数据对其进行预处理。随后,我们进一步使用基于反向翻译的扩充任务数据对其进行预处理。最后,使用原始任务数据对进一步预处理的LM进行微调。
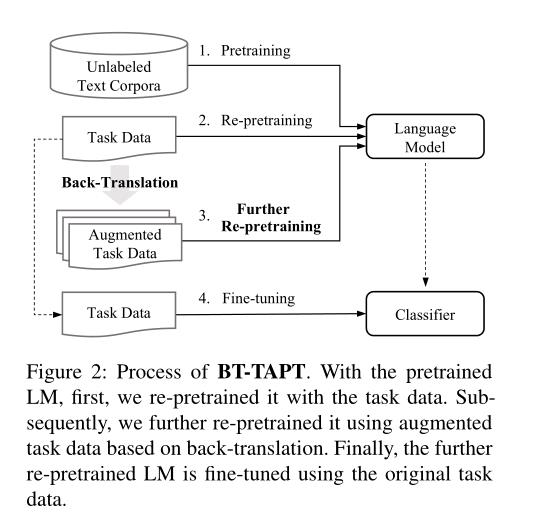
- 提出了一种新的自适应预处理方法(BT-TAPT),该方法利用基于反向翻译的扩展下游任务语料库将最小均方误差推广到任务分配。
- 增强下游任务的性能。
- BT-TAPT对有噪声的文本数据表现出更好的鲁棒性。
以上是关于论文泛读180反向翻译任务自适应预训练:提高文本分类的准确性和鲁棒性的主要内容,如果未能解决你的问题,请参考以下文章
论文泛读199将预训练的 Transformers 微调为变分自动编码器