论文泛读115多样化的预训练上下文编码改进了文档翻译
Posted 及时行樂_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文泛读115多样化的预训练上下文编码改进了文档翻译相关的知识,希望对你有一定的参考价值。
贴一下汇总贴:论文阅读记录
论文链接:《Diverse Pretrained Context Encodings Improve Document Translation》
一、摘要
我们提出了一种新架构,用于通过合并多个预训练文档上下文信号来适应句子级序列到序列转换器,并评估 (1) 生成这些信号的不同预训练方法对翻译性能的影响,(2) 并行的数量文档上下文可用的数据,以及 (3) 以源上下文、目标上下文或源上下文和目标上下文为条件。NIST 汉英、IWSLT 和 WMT 英德任务的实验支持四个一般性结论:使用预训练的上下文表示显着提高了样本效率,足够的并行数据资源对于学习使用文档上下文至关重要,联合调节多个上下文表示优于任何单一表示,并且源上下文比目标端上下文对翻译性能更有价值。我们最好的多上下文模型始终优于现有的最好的上下文感知转换器。
二、结论
我们引入了一种架构和训练方案,能够将来自多个预训练的屏蔽语言模型的表示合并到一个转换器模型中。我们表明,这种技术可以用来创建一个更强大的句子级模型,并在有足够的文档数据的情况下,进一步升级到一个基于上下文信息的文档级模型。通过消融和其他实验,我们建立了文档扩充和多阶段训练,作为面对数据稀缺时训练文档级模型的有效策略。对于这些模型来说,源端的上下文就足够了,而目标端的上下文几乎不会增加额外的价值。
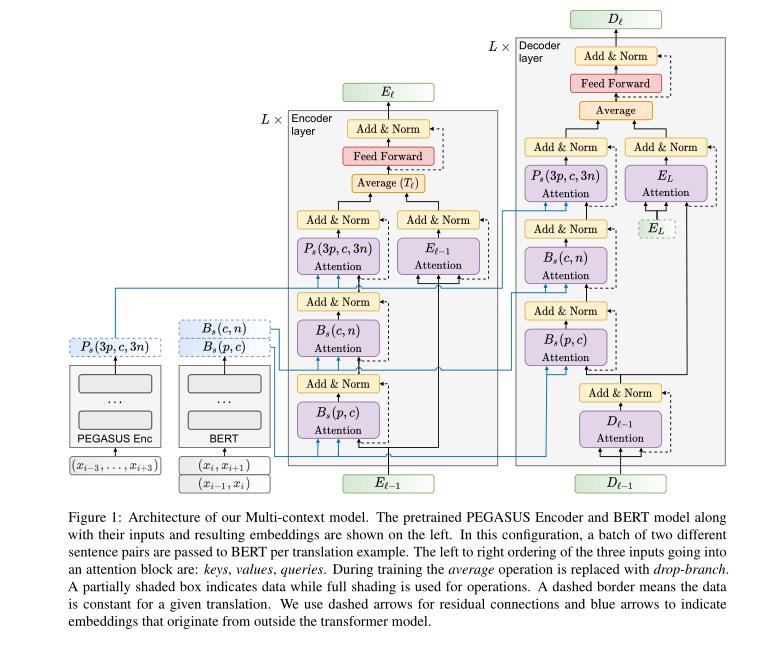
三、model
Multi-context model的架构。左侧显示了预处理后的PEGASUS编码器和BERT模型及其输入和结果嵌入。在这种配置中,每个翻译示例向BERT传递一批两个不同的句子对。进入注意块的三个输入从左到右的顺序是:键、值、查询。在训练过程中,平均操作用分支代替。部分阴影框表示数据,而全阴影用于操作。虚线边框表示对于给定的翻译,数据是恒定的。我们使用虚线箭头表示剩余连接,蓝色箭头表示源自变压器模型外部的嵌入。
以上是关于论文泛读115多样化的预训练上下文编码改进了文档翻译的主要内容,如果未能解决你的问题,请参考以下文章
论文泛读193LICHEE:使用多粒度标记化改进语言模型预训练
论文泛读193LICHEE:使用多粒度标记化改进语言模型预训练