论文泛读193LICHEE:使用多粒度标记化改进语言模型预训练
Posted 及时行樂_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文泛读193LICHEE:使用多粒度标记化改进语言模型预训练相关的知识,希望对你有一定的参考价值。
贴一下汇总贴:论文阅读记录
论文链接:《LICHEE: Improving Language Model Pre-training with Multi-grained Tokenization》
一、摘要
基于大型语料库的语言模型预训练在构建丰富的上下文表示方面取得了巨大成功,并在各种自然语言理解 (NLU) 任务中取得了显着的性能提升。尽管取得了成功,但目前大多数预训练语言模型,如 BERT,都是基于单粒度标记化训练的,通常使用细粒度字符或子词,这使得它们很难学习粗粒度的精确含义。单词和短语。在本文中,我们提出了一种简单而有效的预训练方法 LICHEE,以有效地合并输入文本的多粒度信息。我们的方法可以应用于各种预训练的语言模型并提高它们的表示能力。
二、结论
本文提出了一种新的语言模型预训练的多语方法LICHEE,它既适用于自回归语言模型,也适用于自编码语言模型。在我们的方法中,细粒度嵌入和粗粒度嵌入被分别学习并集成为多粒度嵌入,然后被传递给语言模型的编码器。实验表明,与现有的多粒度方法相比,LICHEE在中英文下游任务上显著提高了模型性能,并显著提高了推理速度。
三、框架
LICHEE的整体结构:
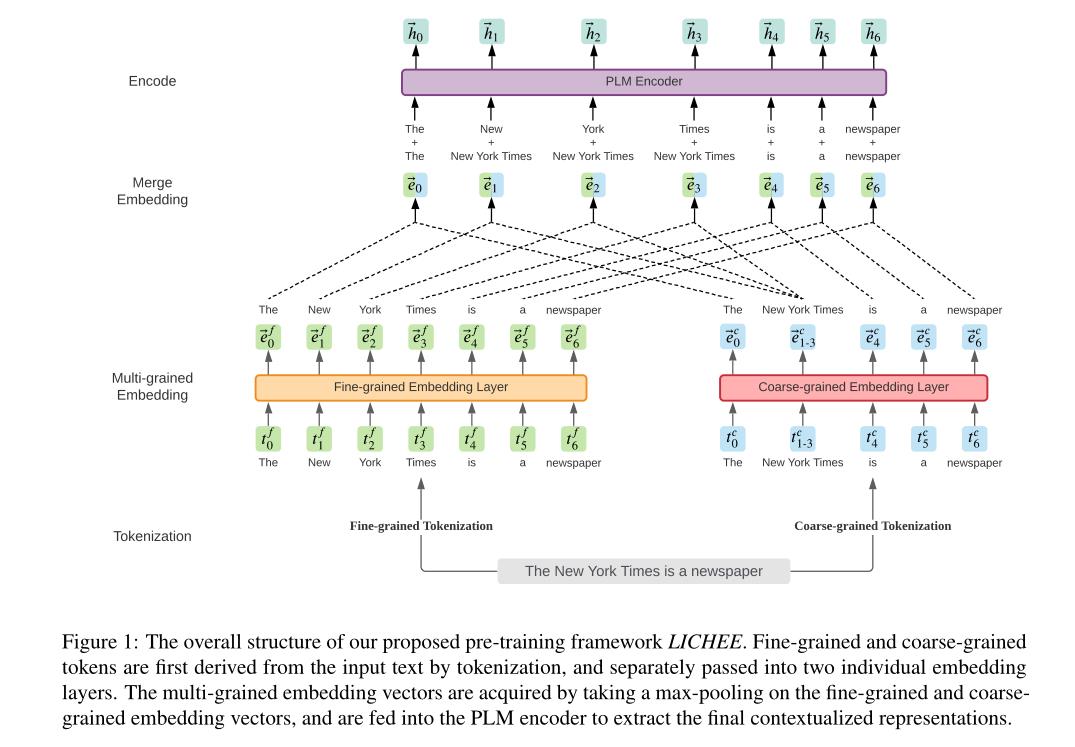
是一个通用的多粒度语言模型预处理框架。
- 自回归
- 自编码任务的预处理方法
- 微调细节
以上是关于论文泛读193LICHEE:使用多粒度标记化改进语言模型预训练的主要内容,如果未能解决你的问题,请参考以下文章
论文泛读193LICHEE:使用多粒度标记化改进语言模型预训练
论文泛读177使用递归神经张量网络从自然语言需求中提取细粒度因果关系