论文泛读89使用SpanBERT改进不同文本类型上的不良药物事件提取
Posted 及时行樂_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文泛读89使用SpanBERT改进不同文本类型上的不良药物事件提取相关的知识,希望对你有一定的参考价值。
贴一下汇总贴:论文阅读记录
论文链接:《Improving Adverse Drug Event Extraction with SpanBERT on Different Text Typologies》
一、摘要
近年来,互联网用户在社交媒体,博客和健康论坛上报告了不良药品事件(ADE)。由于报告数量众多,药物警戒正在寻求诉诸NLP来监控这些销售点。我们首次建议将SpanBERT架构用于ADE提取任务:流行的BERT转换器的这一新版本显示了具有多令牌文本跨度的改进功能。我们通过对具有不同文本类型(推文和博客文章)的两个数据集(SMM4H和CADEC)进行实验来验证我们的假设,发现SpanBERT与CRF的结合在两个方面均胜过所有竞争对手。
二、结论
我们将SpanBERT体系结构引入到从不同类型的文本中提取事件驱动程序的任务中。我们在两个广泛使用的数据集上进行了实验,分别包含非正式的推文和更长的博客帖子,SpanBERT在严格和部分F1-score上用最先进的模型获得了有竞争力的结果,在与严格指标的CRF相结合时优于所有这些结果。错误分析还表明,与其他方法相比,SpanBERT更有能力模拟不常见的单词和较长的实体提及的存在。我们的结果显示了模型在不同数据类型上的灵活性,以及它在模拟ADEs跨度边界时的更高精度。
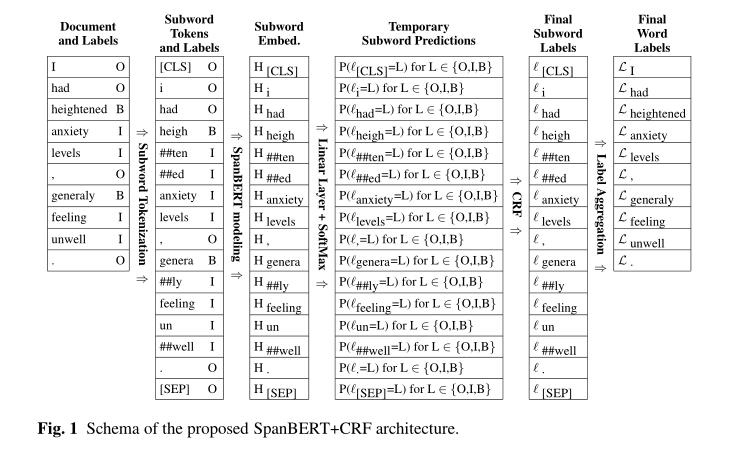
三、model
SpanBERT+CRF架构:
以上是关于论文泛读89使用SpanBERT改进不同文本类型上的不良药物事件提取的主要内容,如果未能解决你的问题,请参考以下文章