论文泛读155对文本类型的对抗性攻击实验
Posted 及时行樂_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文泛读155对文本类型的对抗性攻击实验相关的知识,希望对你有一定的参考价值。
贴一下汇总贴:论文阅读记录
论文链接:《Experiments with adversarial attacks on text genres》
一、摘要
基于预先训练的变形金刚的神经模型,如BERT或XLM-RoBERTa,证明了SOTA在许多自然语言处理任务中的结果,包括非主题分类,如体裁识别。然而,通常这些方法对测试文本的微小改动表现出较低的可靠性。一个相关的问题涉及训练语料库中的主题偏见,例如,特定体裁中特定主题的单词的流行可以欺骗体裁分类器识别该体裁中关于该主题的任何文本。为了缓解可靠性问题,本文研究了攻击类型分类器的技术,以了解转换模型的局限性并提高其性能。虽然简单的文本攻击(例如基于使用tf-idf提取的关键字进行单词替换的攻击)无法欺骗像XLM-RoBERTa这样强大的模型,但我们表明,基于嵌入的算法可以用与它们相似的单词替换一些最“重要”的单词,例如TextFooler,在很大一部分情况下能够影响模型预测。
二、结论
在本文中,我们证明了XLM-RoBERTa流派分类器对简单的攻击方法是有抵抗力的,例如tf-idf关键词的替换,这与传统的基于特征的方法不同,后者对关键词非常敏感。与此同时,即使是XLM-RoBERTa分类器也可能被基于单词的对抗性攻击所欺骗,这些攻击使用了类似于文本愚人的机制。在基线分类器的情况下,训练语料库中超过35%的英语文本可以被成功打破,对于俄语,提高到50%以上。成功攻击的文本数量可以被认为是估计分类器鲁棒性的一个重要指标——被破坏的文本数量越少,分类器就越难被破坏,这意味着更高的鲁棒性。我们还在攻击结果中发现了一些重要的模式,特别是USE的阈值几乎不影响被攻击文本的数量;攻击对俄语来说更有效;替换候选项的数量越多,robust classifier与原始候选项的可靠性差异就越小。
我们的实验证明了文本混合器在通过对抗攻击提高类型分类器鲁棒性方面的有效性。例如,添加断开的文本(带有它们的原始标签)可以提高整体准确性,而新集合中的文本不能被同一组对抗性攻击断开,从而意味着更健壮的分类器。我们也尝试了有针对性的攻击,但是能够被破坏的文本更少,并且在有针对性的攻击文本上训练的分类器比来自无针对性的攻击的分类器表现更差。
三、model
- 1.培训基线分类;
- 2.通过在流派之间交换主题关键词来攻击XLM-RoBERTa分类器;
- 3.用文本混合器攻击XLM-RoBERTa分类器;
- 4.对XLM-RoBERTa分类器执行有针对性的攻击;
- 5.通过使用受到成功攻击的文本训练新的XLM-RoBERTa分类器;
tf-idf:

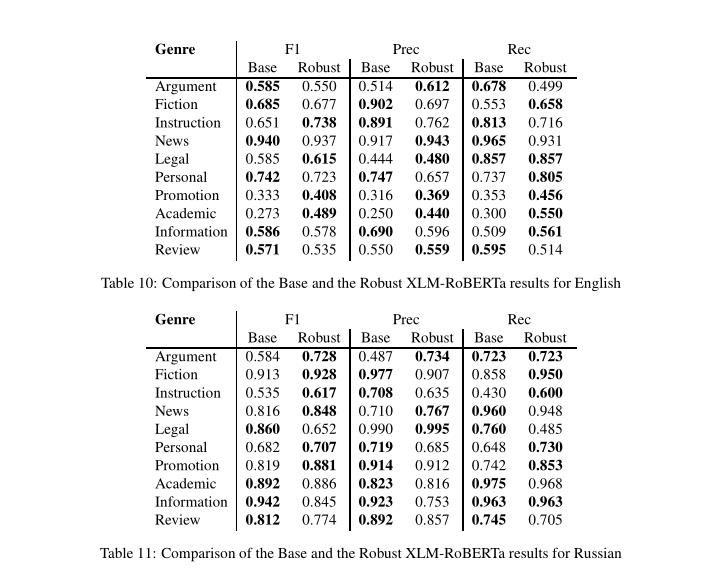
在英语和俄语中的结果:
以上是关于论文泛读155对文本类型的对抗性攻击实验的主要内容,如果未能解决你的问题,请参考以下文章