论文泛读177使用递归神经张量网络从自然语言需求中提取细粒度因果关系
Posted 及时行樂_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文泛读177使用递归神经张量网络从自然语言需求中提取细粒度因果关系相关的知识,希望对你有一定的参考价值。
贴一下汇总贴:论文阅读记录
一、摘要
[上下文:] 因果关系(例如,如果 A,则 B)在功能需求中很普遍。对于 AI4RE 的各种应用,例如从需求中自动推导出合适的测试用例,自动提取这样的因果陈述是基本的必要条件。[问题:] 我们缺乏一种能够以细粒度形式从自然语言需求中提取因果关系的方法。具体而言,现有方法不考虑原因和结果之间的组合。它们也不允许将原因和结果拆分为更细粒度的文本片段(例如,变量和条件),使得提取的关系不适用于自动测试用例推导。[目标和贡献:] 我们解决了这一研究差距并做出了以下贡献:首先,我们提出了因果树库,这是第一个完全标记的二叉分析树语料库,代表 1,571 个因果要求的组成。其次,我们提出了一种基于递归神经张量网络的细粒度因果关系提取器。我们的方法能够恢复用自然语言编写的因果陈述的组成,并在因果树库的评估中获得了 74% 的 F1 分数。第三,我们公开了我们的开放数据集以及我们的代码,以促进在 RE 社区中自动提取因果关系的讨论。我们的方法能够恢复用自然语言编写的因果陈述的组成,并在因果树库的评估中获得了 74% 的 F1 分数。第三,我们公开了我们的开放数据集以及我们的代码,以促进在 RE 社区中自动提取因果关系的讨论。我们的方法能够恢复用自然语言编写的因果陈述的组成,并在因果树库的评估中获得了 74% 的 F1 分数。第三,我们公开了我们的开放数据集以及我们的代码,以促进在 RE 社区中自动提取因果关系的讨论。
二、结论
因果关系是一种广泛使用的语言模式,用来描述功能需求中的预期系统行为(例如,如果A和B,那么C)。自动提取这些因果关系至少支持两个RE用例:自动派生合适的测试用例,以及自动检测需求依赖。然而,现有的方法不能以合理的性能提取因果关系。此外,它们仅以粗粒度的形式提取因果关系,使得它们不适合上述用例。我们解决了这一研究空白,并提出了一个基于RNTN的细粒度因果提取器。我们在自己标注的数据集上训练RNTN,该数据集由1571个因果要求组成:因果树库。我们的数据集是第一个完全标记的二进制解析树的语料库,表示功能需求中因果关系的组成。我们的评估提升了我们方法的可行性。具体来说,我们训练的RNTN能够通过检测NL句子中的27个不同片段(例如,变量、条件、原因)来恢复因果关系的组成。然而,我们的评估也揭示了RNTN的一个主要限制,这对其在实践中的适用性构成了威胁。由于二进制解析树的自下而上的构造,下层的预测错误会传播到上层,导致对组合的部分或完全误解。因此,今后的工作应侧重于提高所提出方法的稳健性。目前,我们正致力于将我们的方法与预先训练的BERT嵌入相结合,以使RNTN对于预测还不在其训练词汇表中的单词更加健壮。到目前为止,我们的方法仅限于提取明确的因果关系。未来的工作应该旨在将提取的范围也扩展到隐含的因果关系。
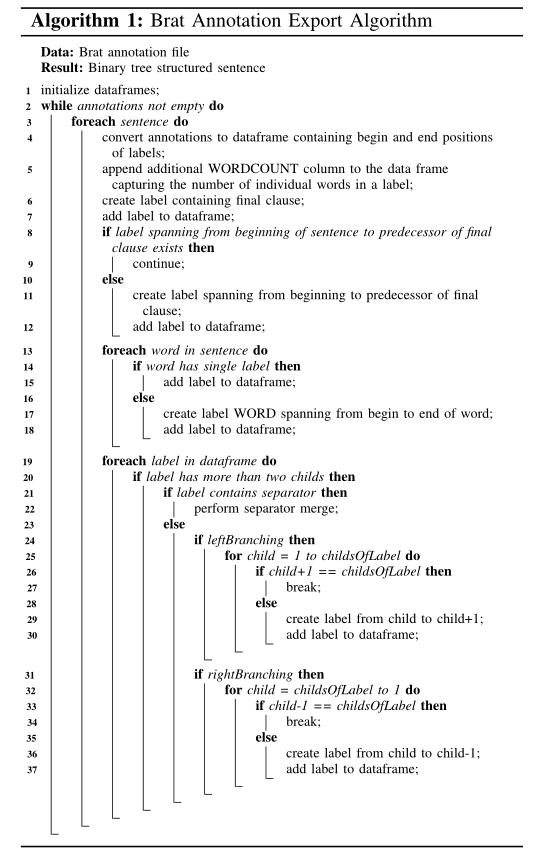
三、算法
布莱特标注导出算法:
以上是关于论文泛读177使用递归神经张量网络从自然语言需求中提取细粒度因果关系的主要内容,如果未能解决你的问题,请参考以下文章