论文泛读74Lawformer:中国法律长文件的预训练语言模型
Posted 及时行樂_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文泛读74Lawformer:中国法律长文件的预训练语言模型相关的知识,希望对你有一定的参考价值。
贴一下汇总贴:论文阅读记录
论文链接:《Lawformer: A Pre-trained Language Model for Chinese Legal Long Documents》
一、摘要
法律人工智能(LegalAI)旨在通过人工智能技术(尤其是自然语言处理(NLP))使法律制度受益。最近,受通用领域中预训练语言模型(PLM)成功的启发,许多LegalAI研究人员致力于将PLM应用于法律任务。但是,利用PLM来解决法律任务仍然具有挑战性,因为法律文件通常包含数千个令牌,这远远超过主流PLM可以处理的长度。在本文中,我们发布了基于Longformer的预训练语言模型,称为Lawformer,用于理解中国法律长文件。我们在各种LegalAI任务上评估Lawformer,包括判决预测,相似案例检索,法律阅读理解和法律问题解答。
二、结论
在本文中,我们预训练了一个基于Longformer的语言模型,它包含了数千万个刑事和民事案件文档,我们称之为Lawformer。然后我们对Lawformer在几个典型的法律问题上的任务进行了评估,包括法律判断预测、相似案例检索、法律阅读理解和法律问题回答。结果表明,Lawformer可以在长序列输入的任务上实现显著的性能提升。虽然Lawformer可以提高法律文档理解的性能,但实验结果也表明挑战依然存在。
今后,我们将进一步探索法律知识的增广预训。众所周知,用法律知识来增强模型对于许多法律事务是非常必要的(钟等,2020a)。同时,我们还将探索生成性法律预习模式。在现实世界的法律实践中,从业者需要进行大量冗余的论文写作工作。一个强大的生成性法律预训练语言模型可以有利于法律专业人员提高工作效率。
综上所述,本文针对法律长文档理解发布了法律格式。未来,我们将尝试将法律知识整合到法律预训练语言模型中,并为法律语言任务预训练生成模型。
三、模型
预训练模型:滑动窗口机制
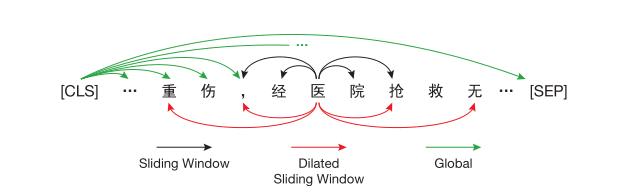
数据预处理为:当事人信息、事实描述、法院意见和判决结果。
基础模型为:

以上是关于论文泛读74Lawformer:中国法律长文件的预训练语言模型的主要内容,如果未能解决你的问题,请参考以下文章
论文泛读154ERNIE 3.0:大规模知识增强语言理解和生成的预训练
论文泛读171具有对抗性扰动的自监督对比学习,用于鲁棒的预训练语言模型