论文泛读120预测文本相似性领域自适应的成功
Posted 及时行樂_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文泛读120预测文本相似性领域自适应的成功相关的知识,希望对你有一定的参考价值。
贴一下汇总贴:论文阅读记录
论文链接:《Predicting the Success of Domain Adaptation in Text Similarity》
一、摘要
迁移学习方法,特别是域适应,有助于利用一个域中的标记数据来提高另一个域中某个任务的性能。但是,目前尚不清楚哪些因素会影响域适应的成功。本文模拟了文本相似度的几个候选者之间的适应成功和最合适源域的选择。我们使用描述性域信息和跨域相似性度量作为预测特征。虽然大多是积极的,但结果也指出了一些难以预测适应成功的领域。
二、结论
我们研究了在具有特定未标记目标域的迁移学习设置中,从候选集中选择最相关的标记数据集作为源域的问题。实验的重点是文本相似性任务和自动编码方法。请注意,建议的过程可以扩展到其他自然语言处理任务和其他无监督的数据挖掘方法。我们使用描述性领域信息和跨领域相似性度量作为预测特征来模拟数据挖掘和数据挖掘的成功,并根据它们的相关性对源领域进行排名。
在未来的工作中,我们打算研究多源域适配设置中的源选择,使用多个源域进行数据传输/数据分析。确定额外的适应成功因素,可以更好地预测复杂领域如P AWS和Quora的DT/DA的成功,并学习成功阈值(在这里,我们将其固定在80%)是其他的研究途径。其他可能性包括尝试各种文本表示(如单词包)和模型(如基于变压器的)。
三、建模
领域转移和适应成功的建模过程:
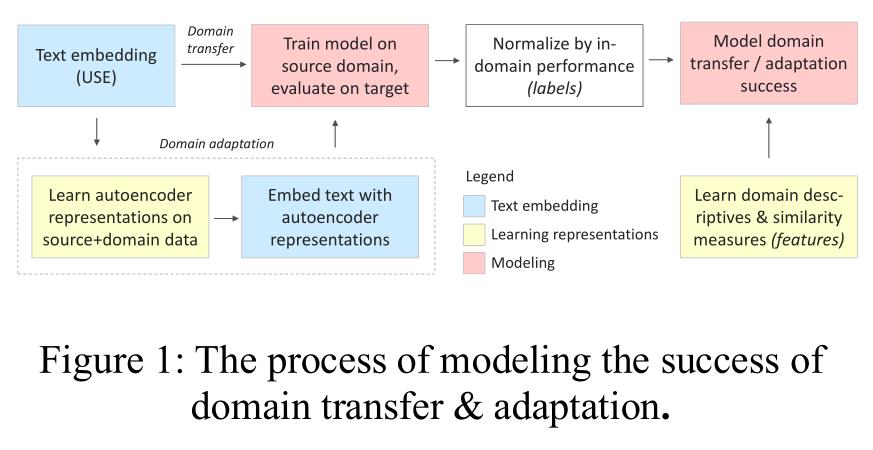
有关迁移学习,感觉自己了解的还不是很多,需要进一步的深入。
以上是关于论文泛读120预测文本相似性领域自适应的成功的主要内容,如果未能解决你的问题,请参考以下文章
论文泛读180反向翻译任务自适应预训练:提高文本分类的准确性和鲁棒性