带你读论文丨基于视觉匹配的自适应文本识别
Posted 华为云
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了带你读论文丨基于视觉匹配的自适应文本识别相关的知识,希望对你有一定的参考价值。
摘要:ECCV2020 通过视觉匹配的方法来做文本识别,解决文档识别中的文本识别多样性和泛化性问题
本文分享自华为云社区《论文解读二十三:基于视觉匹配的自适应文本识别》,作者: wooheng。

引言
本文工作目标是文本识别的泛化和灵活性,之前的文本识别方法[1,2,3,4]在很多的单一场景下都取得了很好的效果,但是一旦推广到另一个包含新字体和新语言的场景,要么使用大量数据重新训练,或者针对每个新样本进行微调。
本文基于一个关键点:文本是有限数量离散实体的重复序列,重复的实体是文本字符串中的字符和字形,即文本行图像中字符/符号的视觉表示。假设可以访问字形示例(即字符的裁剪图像),并要求视觉编码器在给定的文本行图像中定位这些重复的字形。视觉编码器的输出是一个相似度图,它将文本行中每个空间位置与字母表中每个字形的视觉相似度编码,如图1所示。解码器摄取该相似度图以推断最可能的字符串。图2总结了所提出的方法。

图1 用于文本识别的视觉匹配。当前的文本识别模型从预定义(固定)字母表中学习特定于字符形状(字形)的判别特征。我们训练我们的模型来建立给定字符字形(顶部)和要识别的文本行图像(左侧)之间的视觉相似性。这使得模型高度适应看不见的字形、新字母表(不同的语言),并且无需进一步训练即可扩展到新的字符类,例如英语→希腊语。更亮的颜色对应于更高的视觉相似性。
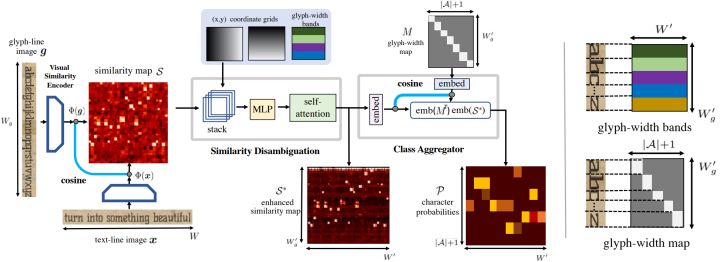
图2 自适应视觉匹配的架构。本文将文本识别问题转化为给定文本线图像中字形样本的视觉匹配问题。左图:体系结构图。视觉编码器 Φ 嵌入字形 g 和文本行 x ,并生成相似性映射S,该映射S对每个字形的相似性进行评分。然后,解决(潜在)不完全视觉匹配中的模糊性,以产生增强的相似性映射S*。最后,使用M中包含的真实字形宽度,将相似性分数聚合到输出类概率P。右图:说明字形宽度如何编码到模型中。字形宽度带(顶部)的高度与其相应字形示例的宽度相同,其标量值是以像素为单位的字形宽度。字形宽度映射(底部)是一个二进制矩阵,字母表A中的每个字符都有一列;这些列通过将相应的行设置为非零值(=1)来指示字形线图像中字形的范围。
2.模型结构
本文的模型通过视觉匹配定位给定的文本行图像中的字形样本来识别给定的文本行图像。它将文本行图像和包含一组样本的字母图像作为输入,并预测N个类上的概率序列作为输出,其中N等于字母图像中给出的样本数。对于推理,字形线图像是通过并排连接参考字体的单个字符字形来组装的,然后可以读取该字体中的文本线。
该模型有两个主要部分:(1)视觉相似性编码器(第2.1节),它输出编码文本行图像中每个字形的相似性的相似性图,和(2)一个与字母无关的解码器(第2.2节),它接收这个相似性映射以推断最可能的字符串。在第2.3节中,我们详细介绍了训练目标。图2给出了模型的简明示意图。
2.1 视觉相似性编码器
输入:所有目标字母的字形;要识别的文本行图像
目的:得到目标字母的字形在要识别的文本行图像中的位置
使用视觉编码器 Φ 对字形 g 和文本行 x 进行编码,并且生成相似图 S ,表示每一个字形和文本行的每一个位置的相似度。使用余弦距离计算相似度。

编码器使用有两个残差块的 U-Net 实现,视觉相似度图由文本行和字形行图像沿编码特征宽度的所有位置之间的余弦距离得到。
2.2 字母无关编码器
字母无关解码器将相似性映射离散为沿文本行图像宽度的所有空间位置的样本中每个字形的概率。
一个简单的实现将预测在相似性映射中每个字形的范围上聚合的相似性得分的argmax或总和。然而,这种策略并不能克服相似性中的模糊性,也不能产生平滑/一致的字符预测。因此分两个步骤进行:首先,相似性消歧义通过考虑线图像中的字形宽度和位置,解决字母表中字形的歧义,产生增强的相似性映射(S*),其次,类聚合器通过聚合S*中每个字形的空间范围内的分数来计算字形概率。
消除相似性歧义
理想的相似性映射具有高相似性的方形区域。这是因为字形和文本行图像中字符的宽度将相同。因此将字形宽度与局部的x、y坐标一起使用小型MLP编码到相似度图中。x、y坐标的两个通道(标准化为[0,1])和字形宽度堆叠起来输入到MLP中。为了消歧义,本文使用一个自我注意模块并输出与S相同大小的增强相似性的映射S*。
类聚合器
将相似图S*映射到每个字形对应的示例字形的概率S∗→P,通过乘矩阵M实现 P = MS∗,其中 M = [ m1, m2 , . . . , m∣A∣]T,mi ∈ {0, 1}=[0,...,0,1,...,1,0,...,0],其中,非零值对应于字形图像中第i个字形的宽度。
推理阶段
在推理阶段使用贪婪算法解码。
3.训练损失函数
使用CTC损失监督字形示例P,以将预测与输出标签对齐。还在每个位置使用辅助交叉熵损失(L sim)来监督视觉编码器S的相似性映射输出。使用真实字符边界框来确定每个字符的空间跨度。总体训练由以下两部分损失组成。
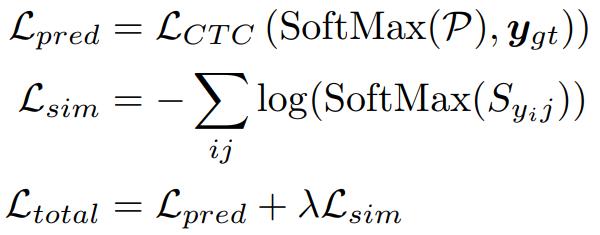
4.实验结果
本文与最先进的文本识别模型进行了比较,然后推广到新的字体和语言。

图3 VS-1、VS-2:泛化到具有/不具有已知测试字形和增加训练字体数量的新字体。FontSynth测试集上的错误率(以%为单位;↓为更好)。Ours-cross代表交叉字体匹配,其中测试字形未知,训练字体被用作字形样本,当样本字体从训练集中随机选择时显示mean和standard-dev,selected显示基于置信度自动选择的最佳匹配示例的结果。R、B、L和I对应于FontSynth训练集中的Regular,Bold,Light,Italic;OS代表Omniglot-Seq数据集。
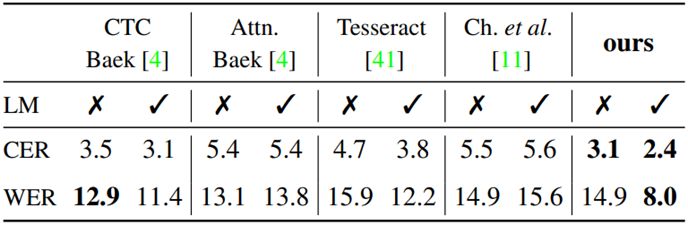
图4 VS-3:从合成数据到真实数据的推广。Google1000英文文档中仅在合成数据上训练模型的平均错误率(%;↓更好)。LM代表6-gram语言模型。
5.结论
本文提出一种文本识别方法,它可以推广到新颖的字体视觉风格(字体、颜色、背景等),并且不与特定的字母大小/语言挂钩。它通过将经典文本识别重新塑造为视觉匹配识别来实现这一目标,本文已经证明了匹配可以利用随机形状/字形进行训练。本文的模型可能是第一个one-shot序列识别的模型,与传统的文本识别方法相比拥有卓越的泛化能力,而不需要昂贵的适配/微调。虽然该方法已经被证明用于文本识别,但它适用于其他序列识别问题,如语音和动作识别。
参考文献
[1] Jeonghun Baek, Geewook Kim, Junyeop Lee, Sungrae Park, Dongyoon Han, Sangdoo Yun, Seong Joon Oh, and Hwalsuk Lee. What is wrong with scene text recognition model comparisons? dataset and model analysis. In Proc. ICCV, 2019.
[2] Zhanzhan Cheng, Yangliu Xu, Fan Bai, Yi Niu, Shiliang Pu, and Shuigeng Zhou. Aon: Towards arbitrarily-oriented text recognition. In Proc. CVPR, 2018.
[3] Chen-Yu Lee and Simon Osindero. Recursive recurrent nets with attention modeling for OCR in the wild. In Proc. CVPR, 2016.
[4] Baoguang Shi, Mingkun Yang, Xinggang Wang, Pengyuan Lyu, Cong Yao, and Xiang Bai. Aster: An attentional scene text recognizer with flexible rectification. PAMI, 2018.
以上是关于带你读论文丨基于视觉匹配的自适应文本识别的主要内容,如果未能解决你的问题,请参考以下文章