带你读论文丨异常检测算法及发展趋势分析
Posted 华为云
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了带你读论文丨异常检测算法及发展趋势分析相关的知识,希望对你有一定的参考价值。
摘要:本文根据对现有基于深度学习的异常检测算法的调研,介绍现有的深度异常检测算法,并对深度异常检测算法的未来发展趋势进行大致的预测。
本文分享自华为云社区《【论文阅读】异常检测算法及发展趋势分析》,原文作者:MUR11。
异常检测问题是很多实际应用场景中的一个重要问题。本文根据对现有基于深度学习的异常检测算法的调研,介绍现有的深度异常检测算法,并对深度异常检测算法的未来发展趋势进行大致的预测。
一、异常检测应用场景
异常检测在实际生产生活中有大量的应用。例如:从信用卡交易记录中找出潜在的盗刷或套现记录、在交通监控视频中找出违法的交通参与者、在医学影像中找出病变的组织、在网络中找出找出入侵者、从物联网传输的信号中找出异常传输等。
当前大部分异常检测场景高度依赖人工,对于人力有大量的需求。未来随着老龄化加剧、工作人口减少,使用算法代替人工进行异常是大势所趋。
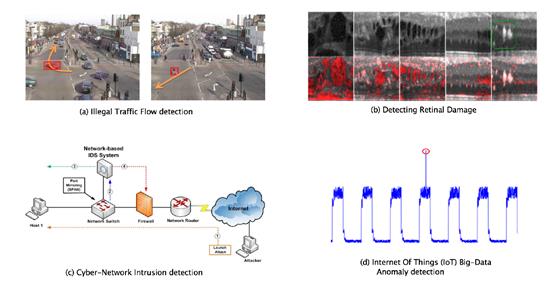
二、常见异常类型
常见的异常类型可以分为三类:
- 点异常:单个样本/采样点明显偏离其他所有样本/采样点的分布。例如:在信用卡交易记录中,如果一个用户日常的交易都是小额交易,突然出现的一笔大额交易就是一个点异常。
- 条件异常:单个样本/采样点与其他一些条件的联合分布明显偏离其他样本/采样点的情况,称为条件异常。例如:某地一年内的气温变化范围为-10度到40度,正常情况下每日气温应该在上述范围内。但是如果夏季的某一天温度达到-5度,虽然当天温度仍在正常范围内,但是结合季节来看则是一个明显的异常,这类异常属于条件异常。
- 群体异常:单个样本/采样点正常,但是大量样本/采样点整体呈现出异常。例如:仍以信用卡交易记录为例,如果一个用户日常的交易都是小额交易,某一天突然出现了10笔小额交易,且每笔交易的金额相同,虽然从每笔交易来看都符合用户的使用习惯,但是这10笔交易结合在一起看却存在异常,该类异常属于群体异常。
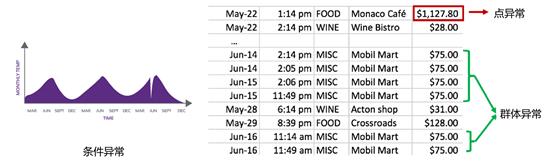
上述三类异常中,条件异常经过一定的转换后等价于点异常,因此实际上常见的异常类型只有点异常、群体异常两种。当前业界的研究和应用主要集中在点异常的检测上,下文也将重点介绍点异常的检测算法。
三、异常检测算法
当前主流的异常检测算法通常基于深度学习技术,按照使用的监督信息可以分为有监督方法、无监督方法、半监督方法。此外,也有一些将深度学习技术和传统的非深度学习技术结合在一起的异常检测算法。下面对这几类方法分别展开介绍。
3.1深度有监督方法
深度有监督学习是目前深度学习研究最充分、应用最广泛的一类方法。利用这类方法进行异常检测时,包括数据收集、模型训练、模型推理三个阶段:
- 数据收集:收集正常样本、异常样本,并对样本进行标注;
- 模型训练:使用标注好的样本训练模型,以基于图像的异常检测为例,常见的模型包括图像分类模型(判断样本是否异常)、目标检测模型(大致定位图像中异常的位置)、语义分割模型(精确定位图中异常的区域);
- 模型推理:将待分析的样本喂给模型,模型经过运算后,输出结果。
这类方法的优点是实现简单、精度高,缺点是需要收集大量的正常样本和异常样本并进行标注。实际中,异常样本往往是很稀缺的,通常难以收集足够数量的异常样本来训练模型,因此也就无法应用深度有监督异常检测方法。
3.2 深度无监督方法
为了更好地应对实际应用中难以收集到足够数量的异常样本的情况,深度无监督异常检测方法通过建模正常样本,来间接地实现异常检测的功能。具体来说,深度无监督异常检测的步骤如下:
- 数据收集:收集大量正常样本;
- 模型训练:通过训练模型建模正常样本,常用的模型包括自编码器、生成对抗网络等;
- 模型推理:将待分析的样本喂给模型,得到模型的输出;
- 比对:通过比对待分析的样本和模型的输出之间的差异,基于事先设定的阈值判断是否存在异常。
该类方法是目前使用深度学习技术进行异常检测的主流方法,其中具有代表性的两类模型分别是自编码器和生成对抗网络。
3.2.1 自编码器
仍以图像异常检测任务为例。使用自编码器模型检测图像中的异常时,流程如下:
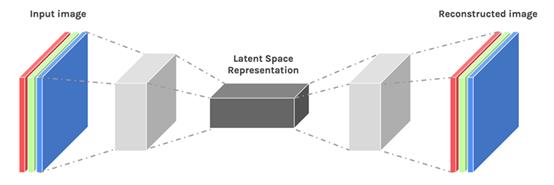
- 数据收集:收集大量正常的图片;
- 模型训练:模型结构如下图所示 [1]。训练时,模型的输入是正常的图片;训练的目标是使模型的输出与输入尽可能相同,常用的衡量指标包括像素级的L2损失、L1损失、SSIM损失等。这类方法的假设是:由于训练过程中模型只见过正常图片,因此无论输入什么样的图片,模型都会倾向于将输入图片重构为正常图片,因此异常图片的重构结果会和输入图片之间存在明显的差异;
- 模型推理:以待分析的图片作为模型的输入,模型经过运算后,输出一张经过模型重构的图像;
- 比对:通过判断输入图像和输出图像之间的像素级重构误差(一般通过L2损失或SSIM损失计算得到),通过将重构误差的值和事先设定的阈值进行比较,如果重构误差的值小于阈值,则判定不存在异常,否则认为图像中存在异常。
3.2.2 生成对抗网络
使用生成对抗网络模型检测图像中的异常时,流程如下:
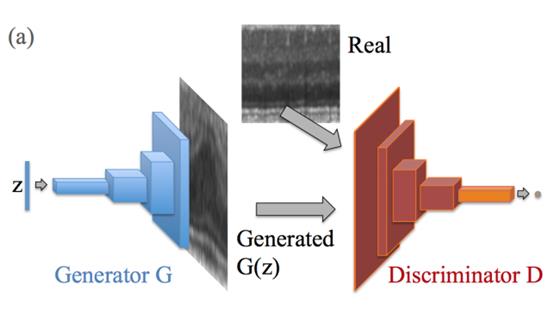
- 数据收集:收集大量正常的图片;
- 模型训练:模型结构如下图所示 [2]。训练时,模型的输入是正常的图片,训练的目标是使模型生成的图片和真实的正常图片具有相同的分布。该训练过程通过生成器和判别器两个子模型共同实现,其中判别器的目标是尽量区分出哪些图片是模型生成的,哪些是真实的;而生成器的目标是尽量生成逼真的图片,让判别器无法区分;
- 模型推理:通过特定的操作步骤,使生成器生成出和待分析图片尽可能相似的图片。例如:通过梯度反传的方法,迭代更新生成器的输入变量z,直到z通过生成器生成的输出和待分析的图像之间的相似度达到最大为止;
- 比对:通过判断待分析的图像和生成的图像之间的像素级差异(一般通过L2损失或SSIM损失计算得到),通过将差异的值和事先设定的阈值进行比较,如果差异的值小于阈值,则判定不存在异常,否则认为图像中存在异常。
3.2.3 小结
以上两个小节简单介绍了两种典型的深度无监督异常检测算法的实现步骤。从上述步骤可以看出,无监督异常检测算法通常是通过计算重构或生成的图像与实际图像之间的差异来判断是否存在故障。这种方法虽然不需要异常样本,更适合实际场景,但是缺点也比较明显——抗噪声干扰的能力比较差。由于像素级的差异不一定是实际的故障造成的,也有可能是污渍等无关痛痒的干扰造成的,而深度无监督异常检测算法无法区分这些不同的差异,因此在实际应用中,深度无监督异常检测算法的误报通常较多。
3.3 深度半监督方法
实际中有时也能收集到少量的异常样本,为了尽可能充分地利用这些异常样本提升异常检测算法的精度,学术界提出了一类深度半监督异常检测算法,该类算法的主要步骤如下:
- 数据收集:收集大量的图片,其中既包含正常图片,也包含异常图片;
- 模型训练:模型结构如下图所示 [3]。训练时,模型并不知道哪些是正常图片,哪些是异常图片,因此并不是通过有监督的方式进行识别,而是将传统非深度的One-class SVM的损失迁移到了深度学习模型中;
- 模型推理:将待分析的图片喂给模型,模型经过一系列运算后,得到一个数值作为输出,通过将该输出值与预先设置的阈值进行比较,如果输出值大于阈值则判定为异常,否则判定为正常。
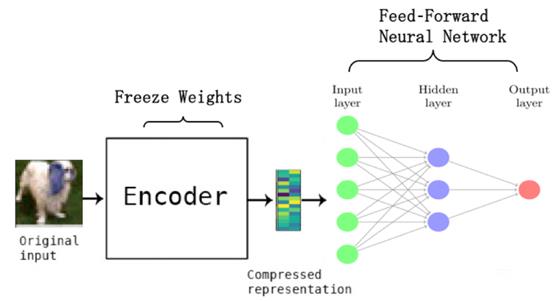
该类方法的优点是数据收集简单,并且可以端到端的进行表示学习和分类器的学习,但是往往训练过程中需要尝试大量的参数,训练耗时较长。
3.4 深度-非深度混合方法
除上述完全基于深度学习的异常检测算法外,近年来也有一些将深度学习和传统的非深度异常检测方法结合在一起的方法,如下图所示。这类方法中,深度学习模型仅作为特征提取器,而核心的识别异常的功能由传统异常检测算法实现。
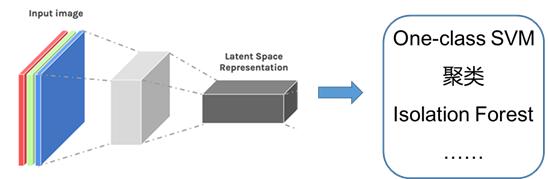
这类方法的优点是可以灵活组合不同的深度学习模型和非深度的异常检测算法,缺点是特征表示学习的过程和判定的过程割裂开了,导致判定的过程不能反作用于特征表示学习的过程,深度学习模型提取的特征不一定能够表征出异常,也不一定能够和后续的异常检测算法相匹配。
四、发展趋势
本节结合前文内容,对异常检测领域中几个有价值的研究场景进行总结,并对未来的研究趋势进行大致的预测:
- 深度有监督方法:当前深度有监督异常检测算法的精度虽然很高,但是由于这类方法高度依赖于大量有标注的正常样本和异常样本,因此在实际中很难找到能够应用的场景。如果想要扩大适用范围,未来如何在小样本条件下,得到泛化性能强的模型,是这类方法需要突破的重点和难点。
- 深度无监督方法:当前深度无监督异常检测算法对于数据的要求较低,适用范围也较大,但是由于这类方法抗干扰能力较差,实际中误报数量往往较多,影响了实际使用时的用户感受。因此,如何进一步建模噪声干扰或抑制噪声干扰,是这类方法未来研究的重点。
- 群体异常检测:群体异常检测是近年来刚刚兴起的研究方向,目前还处于起步阶段,未来的研究方向、方法仍然存在很大的不确定性,但是该方向有望成为未来的热点研究方向之一。
参考文献
[1] Paul Bergmann, Sindy Loewe, Michael Fauser, David Sattlegger, Carsten Steger. Improving Unsupervised Defect Segmentation by Applying Structural Similarity To Autoencoders. arXiv 2019.
[2] Thomas Schlegl, Philipp Seeböck, Sebastian M. Waldstein, Ursula Schmidt-Erfurth, Georg Langs. Unsupervised Anomaly Detection with Generative Adversarial Networks to Guide Marker Discovery. arXiv 2017.
[3] Raghavendra Chalapathy. Anomaly Detection Using One-Class Neural Networks. arXiv 2019.
以上是关于带你读论文丨异常检测算法及发展趋势分析的主要内容,如果未能解决你的问题,请参考以下文章