论文泛读124在自然语言生成的 Pretrain-Finetune 范式中桥接子词间隙
Posted 及时行樂_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文泛读124在自然语言生成的 Pretrain-Finetune 范式中桥接子词间隙相关的知识,希望对你有一定的参考价值。
贴一下汇总贴:论文阅读记录
论文链接:《Bridging Subword Gaps in Pretrain-Finetune Paradigm for Natural Language Generation》
一、摘要
预训练-微调范式的一个众所周知的局限性在于它由一刀切的词汇表造成的不灵活性。这可能会削弱将预训练模型应用于自然语言生成 (NLG) 任务时的效果,尤其是对于具有显着差异的上游和下游任务之间的子词分布。为了解决这个问题,我们通过额外的嵌入传输步骤扩展了 vanilla 预训练-微调管道。具体来说,引入了即插即用的嵌入生成器,以根据其形态相似的嵌入的预训练嵌入来生成任何输入令牌的表示。因此,也可以有效地初始化下游任务中不匹配标记的嵌入。我们在预训练-微调方式下对各种 NLG 任务进行了实验。
二、结论
在这篇论文中,我们指出,一种适合所有人的子词词汇,尽管它包罗一切的优势,并不是流行的训练前微调范式的首选解决方案。造成上下游模型间的子词差异,对粒度不合适和表达不足的词给出了具体的表现形式。因此,我们提出了一种新的即插即用嵌入生成器嵌入转移策略。实证结果表明:
- 1)本方法在克服子词差异方面具有普遍的有效性
- 2)嵌入迁移可以提高计算效率
- 3)嵌入生成器可以通过直接平均输入嵌入或应用可训练成分来实现,后者的性能更好,但依赖于较少的训练。
由于我们的方法对模型架构和任务是透明的,我们相信它可以被广泛应用,并进一步提高预训练模型的灵活性和适用性。
三、模型
预训练的微调管道:
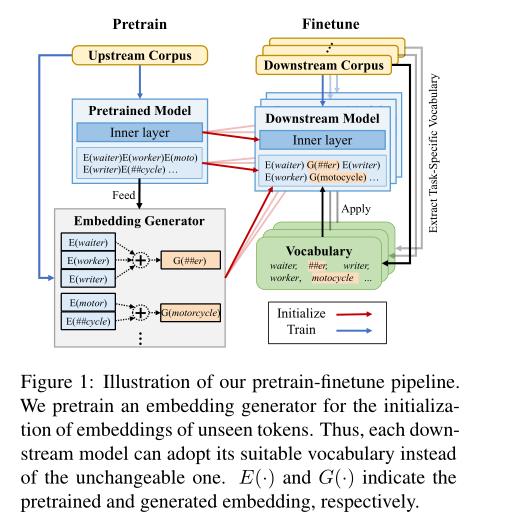
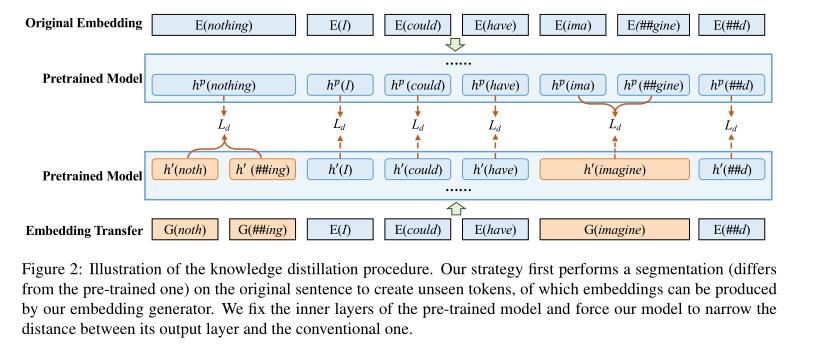
知识蒸馏过程:
以上是关于论文泛读124在自然语言生成的 Pretrain-Finetune 范式中桥接子词间隙的主要内容,如果未能解决你的问题,请参考以下文章
论文泛读154ERNIE 3.0:大规模知识增强语言理解和生成的预训练