论文泛读145从知识图中评估模板和基于 ML 的用户可读文本生成
Posted 及时行樂_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文泛读145从知识图中评估模板和基于 ML 的用户可读文本生成相关的知识,希望对你有一定的参考价值。
贴一下汇总贴:论文阅读记录
论文链接:《An evaluation of template and ML-based generation of user-readable text from a knowledge graph》
一、摘要
知识图谱的典型用户友好渲染是可视化和自然语言文本。在后一种 HCI 解决方案中,数据驱动的自然语言生成系统受到越来越多的关注,但由于存在内容丢失、幻觉或重复等错误,它们的性能往往优于基于模板的系统。尚不清楚这些错误中的哪些与文本所针对的人类的低质量判断显着相关,这阻碍了根据错误对改进人类评估的影响来解决错误。我们利用专家和众包评估对人类创作的文本、模板生成的文本和序列到序列模型生成的文本进行了一项实验,评估了它们可能的关联。结果表明,有错误的人类创作文本与人类对自然性和质量的低判断之间没有显着关联。机器学习生成的文本丢失或产生幻觉与人类对自然性和质量的低判断之间也没有显着关联。因此,这两种方法似乎都是为知识图设计自然语言界面的可行选择。
二、结论
这篇论文首次尝试确定文本与内容丢失、幻觉、语法错误以及人类对质量和自然性的低判断之间是否存在显著关联。在维基人员数据集的知识库上测试的两个内部开发的NLG系统显示:
- 人类创作的文本与人类对自然性和质量的低判断没有显著关联
- 机器学习生成的文本中出现的缺失或幻觉片段也与人类对自然性和质量的低判断没有显著关联。
因此,解决这些错误中的一个不一定会导致感知的自然性和质量的显著改善,因此这两种方法仍然可以用于生成知识图的自然语言界面。
三、model
两个系统:
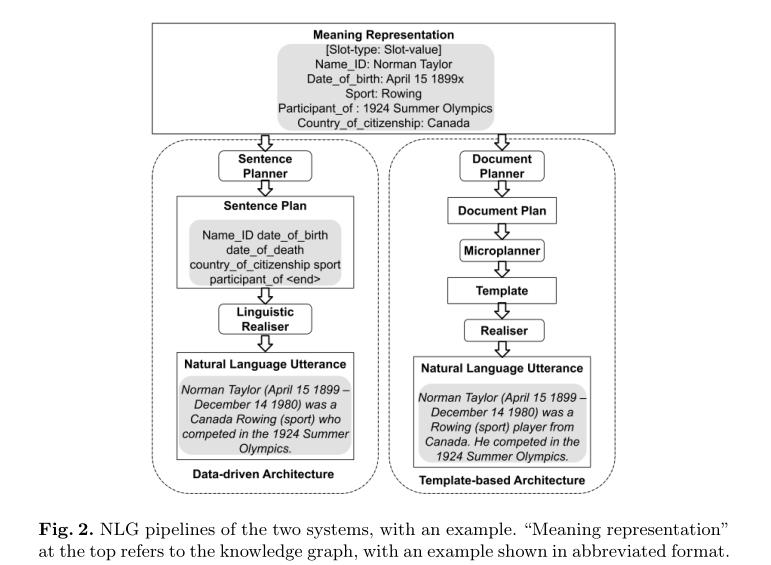
评估程序:
- A:原文;
- B:知识库中对应的元组;
- C和D:由我们的系统生成的文本,根据流畅性、清晰度和自然度进行评估。

以上是关于论文泛读145从知识图中评估模板和基于 ML 的用户可读文本生成的主要内容,如果未能解决你的问题,请参考以下文章