论文泛读73文本相似性分析,用于描述性答案的评估
Posted 及时行樂_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文泛读73文本相似性分析,用于描述性答案的评估相关的知识,希望对你有一定的参考价值。
贴一下汇总贴:论文阅读记录
论文链接:《Text similarity analysis for evaluation of descriptive answers》
一、摘要
考虑到智能系统在教育领域的必要性,本文提出了一种基于文本分析的自动方法,用于自动评估考试中的描述性答案。特别地,研究集中在将自然语言处理和数据挖掘的智能概念用于计算机辅助考试评估系统。本文提出了一种公平评估答卷的架构。在这种体系结构中,考官为给定的问题集创建示例答题纸。通过使用文本摘要,文本语义和关键字摘要的概念,可以计算每个答案的最终分数。文本相似性模型基于暹罗曼哈顿LSTM(MaLSTM)。这项研究的结果与人工评分的作业和其他现有系统进行了比较。
二、结论
因此,随着机器学习和计算智能的进步,有即将到来的系统帮助改善当前的教育系统。本文介绍了一个这样的智能自动系统,用于根据考官提供的某些理想因素来评估描述性答案。根据文中给出的结果,该系统在实际应用中表现良好。所使用的概念是基于自然语言处理领域下的文本分析和文本摘要。如果答案由图形、图表、方程式、数字或任何此类数学或图形表示组成,则当前模型无法评估答案。
这项研究的未来目标是研究模型的这些局限性。此外,作者正在努力在流程中部署一种高级光学字符识别(OCR) [Sharma等人,2013]工具,甚至可以通过将手写答案扫描到系统中来评估它们。作者也在努力扩展这项研究,其中模型还将分析学生在结果声明时在学生仪表板上犯了什么错误
三、System Architecture(系统架构)
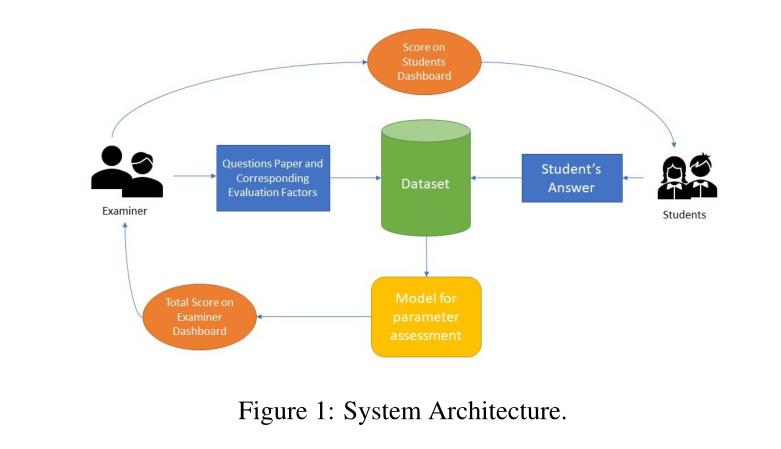
提交答案与理想答案之间的相似度比较(采用MaLSTM)。
error的计算公式:
E
(
e
r
r
o
r
)
=
1
m
∑
i
=
1
m
(
A
E
−
M
E
)
2
E(error)=\\frac 1m\\sum_{i=1}^m(AE-ME)^2
E(error)=m1i=1∑m(AE−ME)2
其中,“AE”是自动系统生成的分数,“ME”是手动评估分配的分数
以上是关于论文泛读73文本相似性分析,用于描述性答案的评估的主要内容,如果未能解决你的问题,请参考以下文章