论文泛读146基于预训练语言模型的基于知识的对话系统
Posted 及时行樂_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文泛读146基于预训练语言模型的基于知识的对话系统相关的知识,希望对你有一定的参考价值。
贴一下汇总贴:论文阅读记录
论文链接:《A Knowledge-Grounded Dialog System Based on Pre-Trained Language Models》
一、摘要
我们展示了为第九届对话系统技术挑战赛 (DSTC9) Track 1 - Beyond Domain APIs: Task-oriented Conversational Modeling with Unstructured Knowledge Access(面向任务的非结构化知识访问对话建模)而开发的基于知识的对话系统。我们利用现有语言模型的迁移学习来完成此挑战轨道中的任务。具体来说,我们将任务分为四个子任务,并在每个子任务上微调了几个 Transformer 模型。我们进行了额外的更改,从而提高了性能和效率,包括将模型与传统实体匹配技术相结合,以及将指针网络添加到语言模型的输出层。
二、结论
我们为DSTC9 Track 1开发了一个基于知识的对话系统,它在基线上遵循流水线架构,在整体性能上优于基线。更重要的是,我们证明了这种性能水平可以用相对较低的计算成本来实现。我们采用了几种方法来提高训练和推理的效率。我们利用了预先训练好的语言模型的力量,并根据我们的任务对其进行了微调。此外,我们将实体选择与知识选择解耦,并采用基于N-gram和编辑距离的统计方法来过滤掉不相关的实体,从而大大减少了候选实体的数量,从而降低了计算成本。最后,我们的系统在自动评估的24个参与团队中排名第四,在响应质量的人工评估的12个决赛团队中排名第十。
三、model
系统架构:
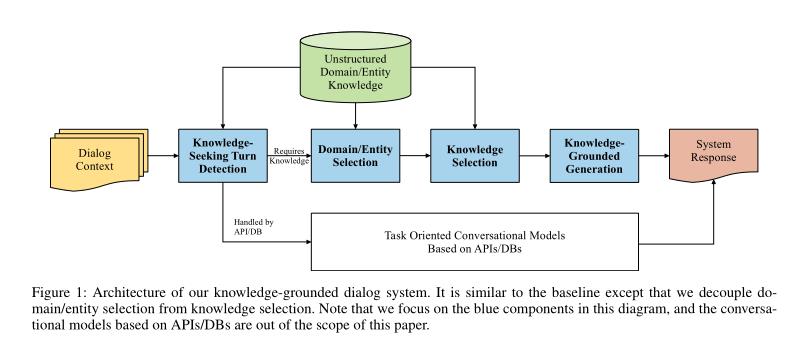
将知识选择的子任务分成两个更小的子任务:
- 1)领域/实体选择
- 2)领域/实体特定的知识选择。
以上是关于论文泛读146基于预训练语言模型的基于知识的对话系统的主要内容,如果未能解决你的问题,请参考以下文章
论文泛读200通过适配器使用预训练语言模型进行稳健的迁移学习
论文泛读193LICHEE:使用多粒度标记化改进语言模型预训练
论文泛读193LICHEE:使用多粒度标记化改进语言模型预训练