斯坦福大学计算机视觉课程cs231n——第一课:课程介绍 计算机视觉概述
Posted 平什么阿
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了斯坦福大学计算机视觉课程cs231n——第一课:课程介绍 计算机视觉概述相关的知识,希望对你有一定的参考价值。
什么是计算机视觉?计算机视觉,顾名思义,就是针对视觉数据的研究。在我们的世界,过去短短几年里视觉数据爆炸式增长到夸张的地步。基于一项2015年的研究,预计到2017年,互联网上80%的数据都是视频。所以,如何用算法来开发这些可以利用和理解的数据变得十分重要,但是视觉数据对于计算机非常难理解,有时我们把视觉数据称为互联网的暗物质,将它与物理学中的暗物质类比,物理学中讲暗物质占宇宙质量的很大一部分,我们知道这是因为各种天体间存在万有引力,但我们不能直接观察到它,视觉数据也是一样,它占据了互联网数据的很大一部分,但是我们很难去探知并理解这些数据到底是什么。有一来自YouTube的实例统计,大概每秒钟会有长达5小时的内容被上传到YouTube。谷歌虽然有很多员工,但是没有人可以坐下来一直观看并给每个视频打上注释,所以如果他们想为观众推荐相关视频,甚至想要通过投放广告赚钱,开发一项技术至关重要。除此之外,计算机视觉还是一个跨学科领域,与物理医学生物等等紧紧融合,与我们的生活息息相关。
一、视觉发展历史
1.物种大爆炸
视觉的历史可以追溯到很久很久以前,实际约5亿4千3百万年前,地球全部被水覆盖,少量的物种在海洋中游荡,生物并不活跃。但是大约在5亿4千年前发生了一件非凡的事,生物学家对化石研究发现,短短1千万年里,动物物种数量爆炸式增长,这一现象被生物学家称之为物种大爆炸(Evolution’s Big Bang)。关于这一现象的成因,尽管有很多相关理论,但这件事多年来仍是未解之谜。几年前,澳大利亚生物学家安德鲁·帕克(Andrew Parker)提出了一种很有说服力的理论,通过对古化石的研究,他发现距今5亿4千万年前第一次有动物进化出了眼睛,视力功能的出现,促进了物种数量的爆炸,动物们可以看见东西了,一旦有了视力,生物开始变得积极主动,生物为了生存开始进化竞赛,这就是动物拥有视觉的开端。
现如今,视觉成为了动物,尤其是智慧动物最重要的感知器官。在人类大脑皮层中,几乎一半的神经元与视觉有关,这项最重要的感知系统,使我们可以生存、运动、工作、操作器物、娱乐、沟通等等。

2.人类让机器获得视觉
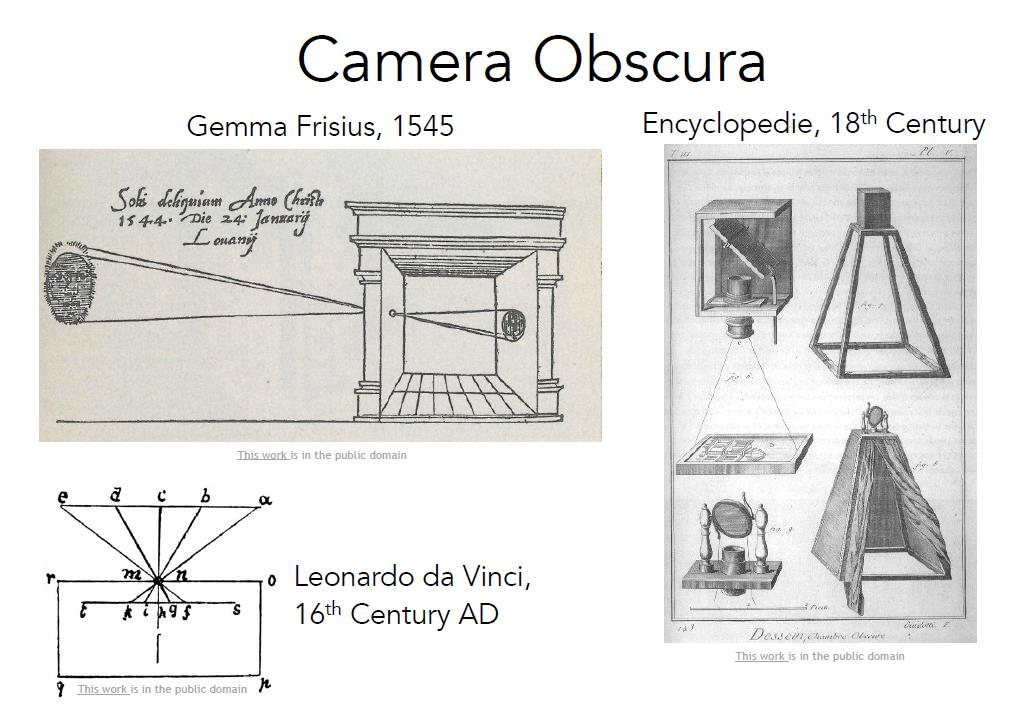
前面讲到了生物的视觉,那么人类让机器获得视觉,又或者说照相机的历史又是怎样的呢?我们现在已知最早的照相机要追溯到17世纪文艺复兴时期的暗箱,这是一种通过小孔成像的相机,这和动物早期的眼睛非常相似,通过小孔接受光线,再到后面的平板收集信息并且投影成像。随着科技的发展,照相机如今已经非常普及,摄像头已经成为手机或其他装置上,最常用的传感器之一。
3.视觉机理的研究
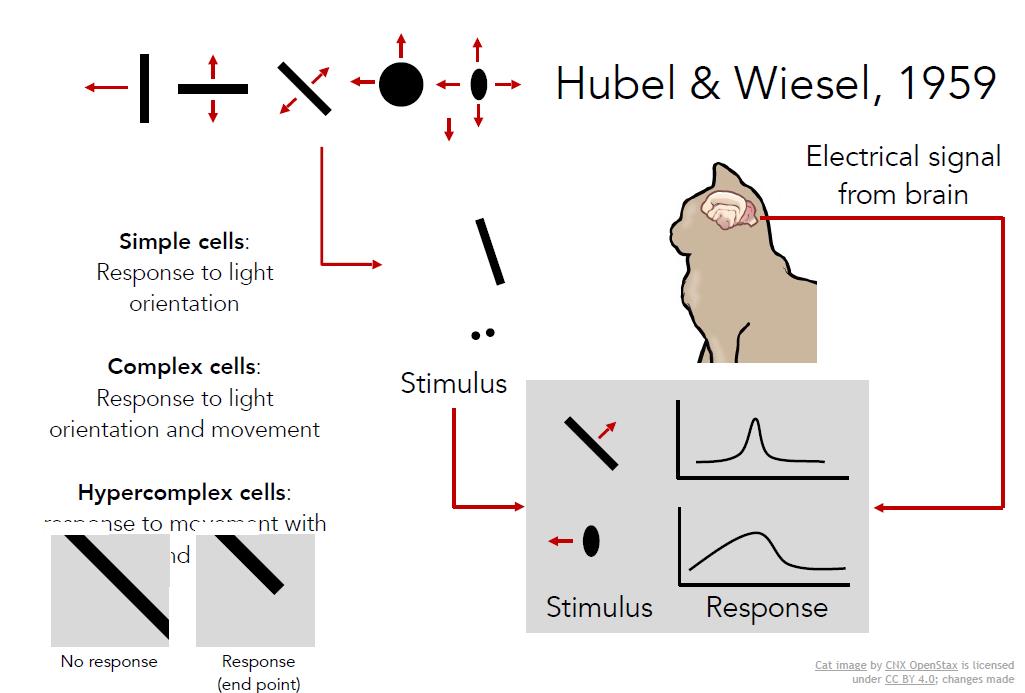
生物学家早就开始研究视觉的机理。其中最具影响力、并启发了计算机视觉研究的,要数五六十年代休伯尔(Hubel)和韦泽尔(Wiesl)使用电生理学的研究。他们的问题是“哺乳动物的视觉处理机制是怎样的”。他们认为存在一种大脑视觉处理机制,利用与人类相似的猫做实验进行研究,他们将电极插进主要控制猫视觉的后脑上初级视觉皮层,然后观察何种刺激会引起视觉皮层神经的激烈反应。他们发现猫大脑皮层的初级视觉皮层,有各种各样的细胞,其中最重要的细胞是当朝着某个特定方向运动时,对定向边缘产生回应的细胞。他们发现视觉处理是始于视觉世界的简单结构,面向边缘,沿着视觉处理途径的移动,信息也在变化,大脑不断建立复杂的视觉信息,直到它可以识别更为复杂的视觉世界。
二、计算机视觉发展历史
1.现实世界的表示
计算机视觉的历史要从60年代初开始。《Block World》是1963年Larry Roberts出版的一部作品,被认为是计算机视觉第一篇博士论文,其中视觉世界被简化为简单的集合形状,其目的时能够识别他们并重建这些形状是什么。从那时起,计算机视觉领域蓬勃发展,现如今已经在全球范围内已经拥有众多的研究人员,虽然还没有弄清楚人类视觉的原理,但是这个领域已经成为人工智能最重要和发展最快的领域之一。

David Marr,麻省理工学院视觉科学家,70年代后期撰写著作 《VISION》,其中包括他是如何理解视觉的,我们应该如何处理计算机视觉开发,甚至如何可以使计算机识别视觉世界的算法。他在书中指出为了拍摄一幅图像,并获得视觉世界最终全面3D表现的过程。
第一个过程就是原始草图,大部分边缘、端点、虚拟线条、曲线、边界等都被用其他元素表示。这是受到了神经学家的启发,休伯尔(Hubel)和韦泽尔(Wiesl)告诉我们视觉处理的早期阶段与诸如边缘之类的简单结构有很大关系。
边缘和曲线的下一个阶段是“2.5维草图”,我们开始将表面、深度信息、图层或视觉场景不连续地拼凑在一起。
然后最终将所有内容放在一起,并在表面和体积图等分层组织了一个3d模型。
这是一个非常理性化的过程,这种思维方式实际上已经在计算机领域 影响了几十年,这也是一个非常直观的方式,直接地考虑如何解构视觉信息。

七十年代另一个非常重要的开创性的问题被提出:我们如何越过简单的块状世界,开始识别或表示现实世界的对象。70年代没有可用的数据集,计算机速度非常慢,笔记本都还没出现的时代,但计算机科学家们已经开始思考如何识别和表示对象,这时斯坦福大学的帕洛阿尔托以及斯里兰卡提出了两种类似的想法,一种被称为广义圆柱体,一另种被称为图形结构,他们的基本思想都是每个对象都由简单的几何图单位组成。例如一个人可以通过广义的圆柱形形状拼接在一起,或者人也看可以由一些关键元素按照不同的间距组合在一起。

80年代,David Lowe思考如何重建或者识别由简单物体结构组成的视觉空间。这项研究是他尝试识别剃须刀,他通过线和边缘进行构建,其中大部分都是直线以及直线之间的组合。

2.目标识别与目标分割
从60到80年代,计算机视觉要解决物体识别的问题非常难,目前所提到工作都是极具野心和脑洞的尝试,但是他们仅仅停留在简单样本或少量样本阶段,没有产生很大的进展,没能输出可以在现实世界有用的东西
所以人们思考在思考解决视觉过程中出现的问题时,一个很重要的想法出现了:目标识别太难,我们首先该做的是目标分割。这个任务就是把一张图中的像素点归类到有意义的区域,我们可能不知道这些像素点组合到一起是一个人型,但是我们可以把这些属于人的像素点从背景中抠出来,这个过程就叫图像分割。有一项早期非常具有开创性的工作,是由Berkeley的Jitendra Malik和他的学生Jianbo Shi所完成的。

还有另一个问题先于其他计算机视觉问题有进展,那就是面部检测。大概在1999-2000年机器学习技术,特别是统计机器学习方法开始加速发展,涌现了大量方法,其中便出现了使用AdaBoost算法进行实时面部检测的做法,由Paul Viol和Michael Jones完成,这是在计算机芯片还非常非常慢的2001年完成的。在他们发表论文的五年后,2006年富士推出了第一个人脸检测相机,这是基础学科到实际应用的快速转化。

如何更好的目标识别,这是一个我们可以继续研究的领域。90年代末到2000的前十年有一个非常由影响力的思想方法就是基于特征的目标识别。David Lowe完成了一个影响深远的工作,叫SIFT特征匹配,例如这里一个stop表示去匹配另一个stop标识是非常难的,因为很多变化的因素,比如相机的角度,遮挡,视角,光线等等。但是有某些特征,他们往往能在变化中具有表现性和不变性,所以目标识别首要任务是在目标上确认这些关键特征,然后把这些特征与相似的目标进行匹配,比匹配整个目标要容易的多。

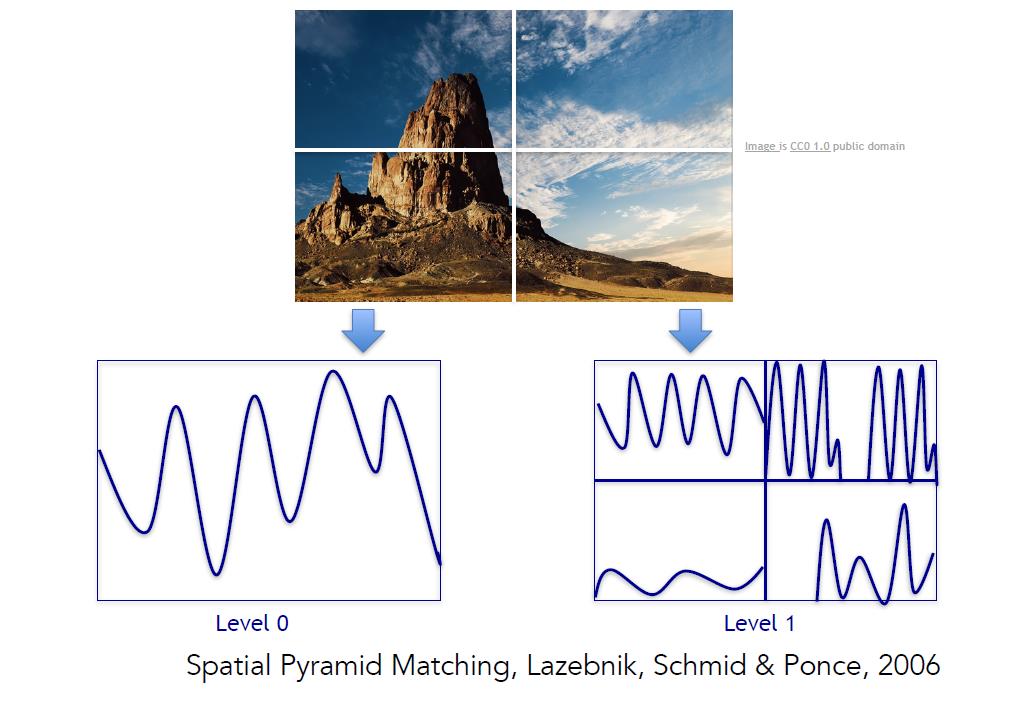
使用相同的构成要素的图片具有相似的表现特征,在这一领域的一项进展是识别整幅图的场景。空间金字塔匹配(Spatial Pyramid Matching)是一个非常典型的例子,其背后的思想是图片中有各种特征,这些特征可以告诉我们这是风景还是厨房或高速公路等,这个算法从图像的各部分像素抽取特征,并把他们放在一起,作为一个特征描述符,在特征描述符上再做一个支持向量机。
有个在人类认知方面很类似的工作正处于风口浪尖。其做法是把这些特征放在一起之后,研究如何在实际图片中比较合理地设计人体姿态和辨认人体姿态。这方面的工作有两个,一个被称为方向梯度直方图(histogram of gradients),另一个被称为可变形部件模型(deformable part models)。

三、数据集
从60到70到80年代一步步走到21世纪,有一件事一直在变化,那就是图片的质量,随着互联网、数码相机以及计算机视觉的发展,我们现在已经拥有了更好的数据。计算机视觉在21世纪早期指出了一个非常重要的基本问题,就是目标识别,但是21世纪才才开始拥有真正的标注数据集供我们衡量性能,其中很有影响力的数据集叫PASCAL Visual Object Challenge,这个数据集有20个类别,图中展示3个火车、飞机和人,其他的还有牛、瓶子、猫等等类别,数据集中每个种类有成千上万张图片。
这里有一张图表列举了2007-2012年在基准数据集上检测图像中20种目标的检测效果,可以看到在稳步提升。

在同一时期,普林斯顿和斯坦福的一批人开始向这个领域提出一个更难的问题——我们是否具备了识别真实世界中每一个或大部分物体的能力。这个问题也是由机器学习中一个现象驱动的,就是大部分的机器学习算法,无论是图模型,还是支持向量机,或是AdaBoost都很可能会在训练过程中过拟合。部分原因是可视化数据非常复杂,正因为他们太复杂了,我们的模型往往维数比较高,输入高维模型,还有一堆参数要调优,当我们寻来你数据量不够时,很快就会产生过拟合现象,这样我们就无法很好地泛化。
ImageNet这一项目也由此而生,该项目汇集所有能找到的图片,包含世界万物,组建一个尽可能大的数据集,约耗时三年完成。使用WordNet字典进行排序,这个字典里有上万个物体类别,最终完成拥有22000类,14000万张图的数据集,这应该时当时AI领域最大的数据集,它将目标检测算法推到一个新的高度。

为了更好地推动目标检测的发展,从2009年开始,ImageNet团队组织了一场国际比赛,叫做ImageNet大规模视觉识别竞赛(ImageNet Large Scale Visual Recognition Challenge)。其测试集共有140万目标图像,1000种类别。下面是示例图片和算法,如果一个算法能输出概率最大的5个类别,其中有正确的对象,就被认为是识别成功。

四、卷积神经网络的出现和发展
ImageNet挑战赛从2010到2015年的图像分类结果如下图所示,其中X轴表示年份,Y轴表示错误率。到2012时年错误率已经低到与人类一样,这是一个很大的进步。有一个很特别的时刻,就是在2012年,前两年错误率都在25%左右,但是2012年突然下降了10%达到16%,那年的获奖算法是一种卷积神经网络模型,击败当时所有其他的算法,从那年开始神经网络包揽比赛冠军。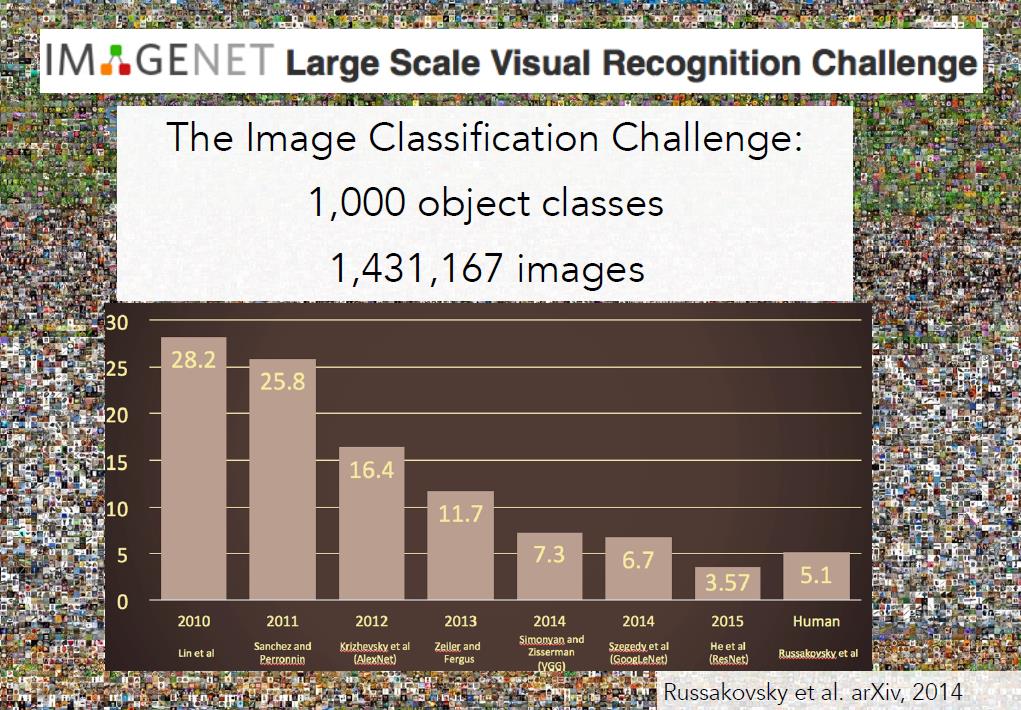
让我们来看看过去几年在ImageNet中获胜的算法。
2011年,Lin et al提出的方法首先计算特征,然后计算局部不变特征,经过一些池化操作和多层处理,最后的结果传给线性SVM。
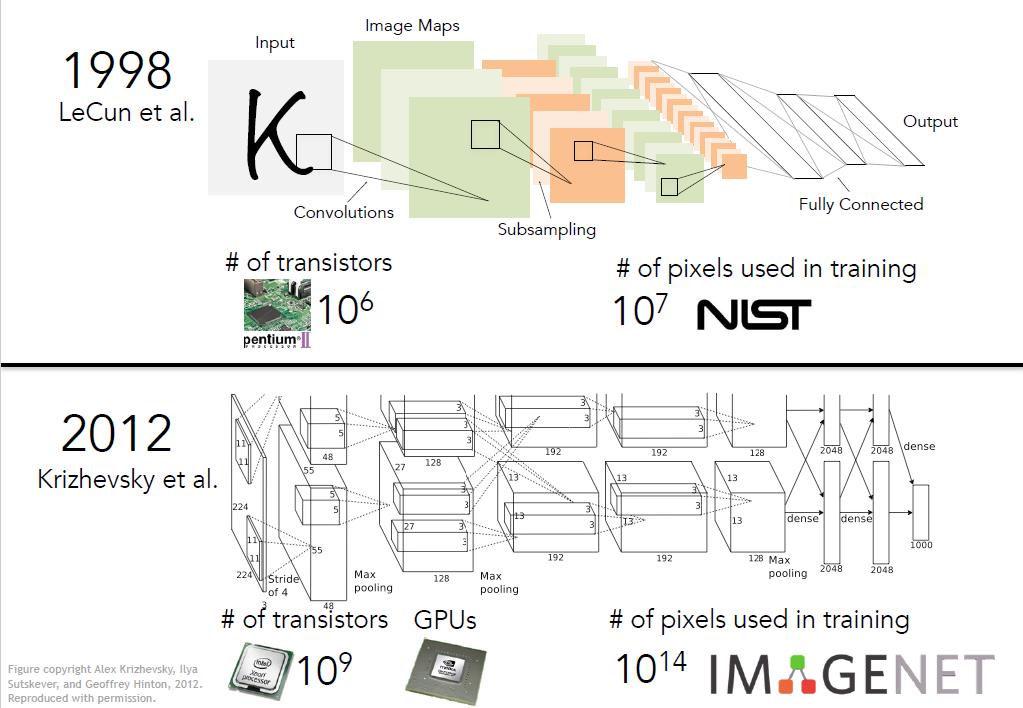
2012年出现了真正的突破,来自多伦多大学的Jeff Hinton小组和他当时的博士生Alex Krizhevsky和Ilya Sutskever创造了这个7层神经网络,AlexNET,从那年开始神经网络包揽比赛冠军,而这些网络的趋势也是每年都变得越来越深。
2014年,有了更深的网络,来自谷歌的GoogLeNET和来自牛津大学的VGG网络,有19层网络。
2015年这一现象更加疯狂,微软亚洲研究院的残差网络有152层。

神经网络的突破在2012年,但是其发明可以追溯到更早之前。1998年,Yann LeCun 和他的伙伴在Bell实验室利用卷积神经网络进行数字识别,该网络的结构和2012年的AlexNet十分相似。
为什么神经网络仅仅在最近几年才开始流行?一是因为计算能力的提升,由于摩尔定理,计算机速度每年提高,芯片上晶体管数量90年代至今已经增长了好几个数量级,如今我们有了GPU这样的图像处理单元,他们具有超高的并行计算能力,非常适合卷积神经网络这类高强度计算。很多时候只是计算模型的扩展,就能得到更好的结果。另一个关键的原因就是数据,这些算法需要大量的数据,90年代并没有数据,而如今,2010后我们拥有了像PASCAL和ImageNet这样的高质量数据集合。
五、未来与挑战
在计算机视觉领域,我们正尝试制造一个和人拥有一样视觉能力的机器,这是个非常神奇有趣的领域,很多的问题等待着被挑战。诸如语义分割、知觉分组、动作识别、增强虚拟现实等等。随着感知器的发展,也将出现更多个有趣的问题。
毫无疑问,计算机视觉正在带领人类开创一个伟大的时代。

以上是关于斯坦福大学计算机视觉课程cs231n——第一课:课程介绍 计算机视觉概述的主要内容,如果未能解决你的问题,请参考以下文章
全球名校课程作业分享系列--斯坦福计算机视觉与深度学习CS231n之tensorflow实践
全球名校课程作业分享系列--斯坦福计算机视觉与深度学习CS231n之SVM图像分类
全球名校课程作业分享系列--斯坦福计算机视觉与深度学习CS231n之softmax图像多分类
全球名校课程作业分享系列--斯坦福计算机视觉与深度学习CS231n之特征抽取与图像分类提升