全球名校课程作业分享系列--斯坦福计算机视觉与深度学习CS231n之神经网络细解与优化尝试
Posted 寒小阳
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了全球名校课程作业分享系列--斯坦福计算机视觉与深度学习CS231n之神经网络细解与优化尝试相关的知识,希望对你有一定的参考价值。
课程作业原地址:CS231n Assignment 1
作业及整理:编写:@土豆 && @郭承坤 && @寒小阳
时间:2018年2月。
出处:http://blog.csdn.net/han_xiaoyang/article/details/79278882
To-Do:
[x] 统一所有的数学符号和代码符号
[x] 统一所有的术语名称
[x] 术语的英文词汇对应
[x] 线性模型的名字是?perceptron?
[x] 损失函数的计算公式和符号是否严格和合适?
[x] denominator layout?
- [ ] BN梯度的证明
- [x] bn_param[‘running_mean’] = running_mean
bn_param[‘running_var’] = running_var
(我是盗图大仙,所有图片资源全部来源于网络,若侵权望告知~)
本文是什么?
本文以CS231n的Assignment2中的Q1-Q3部分代码作为例子,目标是由浅入深得搞清楚神经网络,同时以图片分类识别任务作为我们一步一步构建神经网路的目标。
本文既适合仅看得懂一点Python代码、懂得矩阵的基本运算、听说过神经网络算法这个词的朋友,也适合准备学习和正在完成CS231n课程作业的朋友。
本文内容涉及:很细节的Python代码解析 + 神经网络中矩阵运算的图像化解释 + 模块化Python代码的流程图解析
本文是从Python编程代码的实现角度理解,一层一层拨开神经网络的面纱,以搞清楚数据在其中究竟是怎么运动和处理的。希望可以为小白,尤其是为正在学习CS231n课程的朋友,提供一个既浅显又快捷的观点,用最直接的方式弄清楚并构建一个神经网络出来。所以,此文不适合章节跳跃式阅读。
本文不是什么?
不涉及艰深的算法原理,忽略绝大多数数学细节,也尽量不扯任何生涩的专业术语,也不会对算法和优化处理技术做任何横向对比。
CS231n课程讲师Andrej Karpathy在他的博客上写过一篇文章Hacker’s guide to Neural Networks,其中的精神是我最欣赏的一种教程写作方式:“My exposition will center around code and physical intuitions instead of mathematical derivations. Basically, I will strive to present the algorithms in a way that I wish I had come across when I was starting out.”
“…everything became much clearer when I started writing code.”
废话不多说,找个板凳坐好,慢慢听故事~
待折腾的数据集
俗话说得好:皮裤套棉裤,里边有缘故;不是棉裤薄,就是皮裤没有毛!
我们的神经网络是要用来解决某特定问题的,不是家里闲置的花瓶摆设,模型的构建都有着它的动机。所以,首先让我们简单了解下要摆弄的数据集(CIFAR-10),最终的目标是要完成一个图片样本数据源的分类问题。
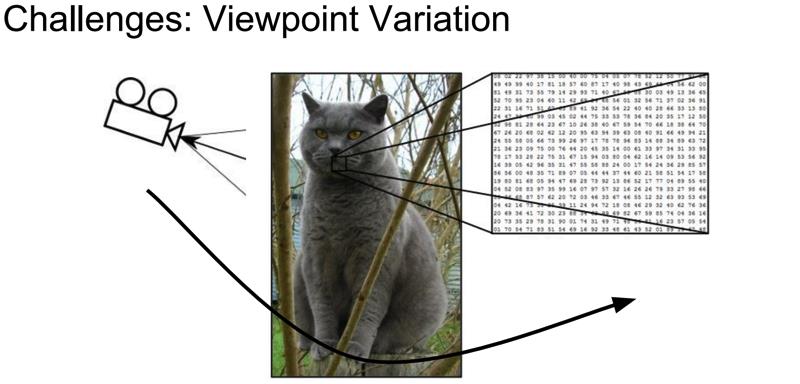
图像分类数据集:CIFAR-10。
这是一个非常流行的图像分类数据集是CIFAR-10。这个数据集包含了60000张
32×32
32
×
32
的小图像,单个像素的数值范围都在0-255之间。每张图像都对应于是10种分类标签(label)中的一种。此外,这60000张图像被分为包含带有标签的50000张图像的训练集和包含不带有标签的10000张图像的测试集。

上图是图片样本数据源CIFAR-10中训练集的一部分样本图像,从中你可以预览10个标签类别下的10张随机图片。
小结:
在我们的故事中,只需要记得这个训练集是一堆
32×32
32
×
32
的RGB彩色图像作为训练目标,一个样本图像共有
32×32×3
32
×
32
×
3
个数据,每个数据的取值范围0~255,一般用x来标记。每个图还配有一个标签值,总共10个标签,以后我们都用y来标记。(悄悄告诉你的是:每个像素点的3个数据维度是有序的,分别对应红绿蓝(RGB))
关于神经网络,你起码应该知道的!
下图是将神经网络算法以神经元的形式绘制的两个图例,想必同志们早已见怪不怪了。
但是,你起码应该知道的是其中各种约定和定义:
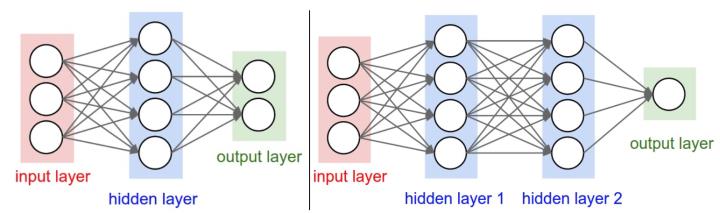
左边是一个2层神经网络,一个隐藏层(蓝色层)有4个神经元(也可称为单元(unit))组成,输出层(绿色)由2个神经元组成,输入层(红色)是3个”神经元”。右边是一个3层神经网络,两个隐藏层,每层分别含4个神经元。注意:层与层之间的神经元是全连接的,但是层内的神经元不连接(如此就是所谓全连接层神经网络)。
这里有个小坑:输入层的每个圈圈代表的可不是每一张图片,其实也不是神经元。应该说整个纵向排列的输入层包含了一张样本图片的所有信息,也就是说,每个圈圈代表的是某样本图片对应位置的像素数值。可见对于CIFAR-10数据集来说,输入层的维数就是 32×32×3 32 × 32 × 3 ,共3072个圈圈呢!至于输出层的神经元数也是依赖数据集的,就CIFAR-10数据集来说,输出层维数必然是10,即对应数据集的10个标签。至于中间的隐藏层可以有多少层,以及每层的神经元个数就都可以任意啦!你说牛不牛?!
在接下来我们的故事中,要从代码实现的角度慢慢剖析,先从一个神经元的角度出发,再搞清楚一层神经元们是如何干活的,然后逐渐的弄清楚一个含有任意神经元个数隐藏层的神经网络究竟是怎么玩的,在故事的最后将会以CIFAR-10数据集的分类问题为目标一试身手,看看我们构造的神经网络究竟是如何工作运转的。
所谓的前向传播
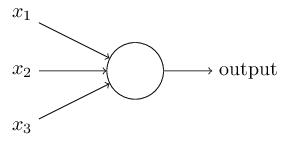
一个神经元的本事
我们先仅前向传播而言,来谈谈一个神经元究竟是做了什么事情。
前向传播,这名字起的也是神乎其神的,说白了就是将样本图片的数据信息,沿着箭头正向传给一个带参数的神经网络层中咀嚼一番,然后再吐出来一堆数据再喂给后面的一层吃(如此而已,居然就叫做了前向/正向传播了,让人忍不住吐槽一番)。那么,对于一个全连接层(fully-connected layer) 1
的前向传播来说,所谓的“带参数的神经网络层”一般就是指对输入数据源(此后用”数据源”这个词来表示输入层所有输入样本图片数据总体)先进行一个矩阵乘法,然后加上偏置,得到数字再运用激活函数”修饰”,最后再反复迭代罢了(后文都默认使用此线性模型)。
是不是晕了?别着急,我们进一步嚼碎了来看看一个神经元(处于第一隐藏层)究竟是如何处理输入层传来的一张样本图片(带有猫咪标签)的?

上面提到过,输入数据源是一张尺寸为 32×32 32 × 32 的RGB彩色图像,我们假定输入数据 xi x i 的个数是 D D 的话(即是有 D D 个),那这个。为了普遍意义,下文继续用大写字母 D D 来表示一张图片作为数据源的维数个数(如果该神经元位于隐藏层,则大写字母表示本隐藏层神经元的神经元个数,下一节还会提到)。
显然,一张图片中的 D D 个数据包含了判断该图片是一支猫的所有特征信息,那么我们就需要”充分利用”这些信息来给这张样本图片”打个分”,来评价一下这张图像究竟有多像猫。
不能空口套白狼,一张美图说明问题:
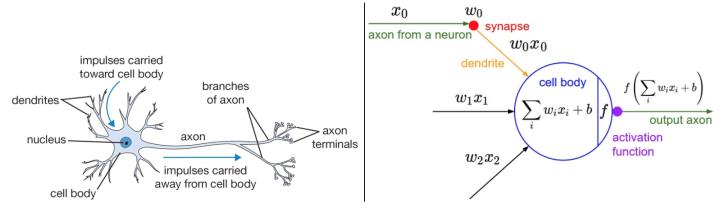
左图不用看,这个一般是用来装X用的,并不是真的要严格类比。虽然最初的神经网络算法确实是受生物神经系统的启发,但是现在早已与之分道扬镳,成为一个工程问题。关键我们是要看右图的数学模型(严格地说,这就是传说中的感知器perceptron)。
如右图中的数学模型所示,我们为每一个喂进来的数据
xi
x
i
都对应的”许配”一个”权重”参数
wi
w
i
,再加上一个偏置
b
b
,然后一股脑的把他们都加起来得到一个数(scalar):
上面的代数表达式看上去很繁杂,不容易推广,所以我们把它改写成