贪心算法,用最简单的逻辑解决最复杂的问题
Posted 银河系算法指南
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了贪心算法,用最简单的逻辑解决最复杂的问题相关的知识,希望对你有一定的参考价值。
扫码二维码
获取更多内容
银河系算法指南

1.贪心算法
假设你去菜市场买菜,去了以后才发现菜市场只供应下面的四种食品了,但是告诉你说现在清仓大甩卖,所有商品一律1块钱一斤处理。如果你的购物篮只能携带3斤左右的商品的情况下,怎么选择才能保证买到的商品最划算呢?
食物名称 |
每斤/单价(原价) |
剩余 |
牛肉 |
20元 |
4斤 |
蔬菜 |
3元 |
10斤 |
三文鱼 |
50元 |
2斤 |
西瓜 |
2元 |
20斤 |
考虑最划算,就是折扣最大的情况,我们只要挑原来单价最贵的就可以,你可以选择买下所有剩余的2斤的三文鱼,还可以再选择买1斤的牛肉,这时候你实际食物总价值为60元。尽管我想没有人会去菜市场按这种方式买菜,但是不可否认这是一种最符合要求的购买方式。
整个计算方式描述起来就是,首先计算每个物品的单价,其次永远选择单价最高的,如果单价最高的已经使用完了,则选择次高的,直到达到容量限制。这种每次都选择当前来看最佳的选择,而不管后面的选择的方式这就是贪心算法
2.动态规划的区别
与贪心算法比较类似的是动态规划算法,我们之前在讲LCS(最长公共子序列)的时候有讲过,这里我们举个例子来比较一下,假设有一个小偷,闯入一家商店中抢东西,他只能携带五公斤重量的商品,而这个商店中只有三样商品,他该如何选择呢?
商品名称 |
价值 |
重量 |
单反相机 |
12000元 |
3公斤 |
iPad |
6000元 |
1公斤 |
笔记本电脑 |
10000元 |
2公斤 |
这个例子我们是否可以按照上面的单价算法来计算呢,我们可以尝试一下:
由于我们这边的限制条件是重量,因此我们先计算每个商品的每公斤实际价值。
iPad每公斤有6000元 (按公斤计算Really?)
笔记本电脑是每公斤5000元
单反相机每公斤4000元
选择单价最高的,我们首先选择拿最高的iPad
选择拿单价次高的笔记本电脑,这时候总重量3公斤,
选择拿单反相机,因为超出了最大重量的限制无法完成。
但这是最优解吗?貌似不是,毕竟我们肉眼也可以看到单反+笔记本电脑的组合价值最高。因此上面的算法对于这种情况是无效的
这里的区别就是空闲率的问题,我们选择笔记本和IPad后,其实还有两公斤的闲置,没有使用。由于这里商品不能被拆分,空闲容量导致整体有效价值的降低,这就是算法中经典的0-1背包问。
向背包中填充物品,其中1和0代表了物品要么拿走,要么不拿。前面的选择会影响后面的选择,这种问题只能依赖动态规划的方式去解决。
3.霍夫曼编码
单纯讲概念虽然比较简单但是很难让人理解到底有啥用处。其实你可能每天都在接触到贪心算法的一些应用,比如说霍夫曼编码,这种编码被广泛的应用于数据压缩协议中。而数据压缩又是我们经常使用的,你看的图片jpeg, png,听的音乐mp3,压缩的文件zip,gzip,bzip等都有他的使用,另外上网使用的http协议中传输的数据很多也是通过这种编码方式压缩后才传输的。
接下来我们讲一下霍夫曼编码的原理,其实并没有想象的那么复杂。
3.1 霍夫曼编码的原理
在计算机中,每个字母至少占用一个字节的大小,也就是我们所说使用ASCII码来表示的方式,如果采用Unicode编码还要更大一些,但是每个字母之间出现的频率是不同的,有一些字母比如a,e出现的概率要远大于x,z出现的概率。下面是wiki上给出的字母频率表,可以看出差距其实还是挺大的。
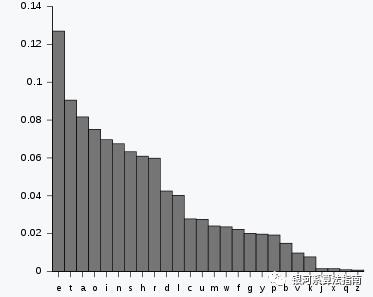
霍夫曼编码就是利用频率不对等的情况,将每个字母的定长编码通过变长的方式实现,我们举一个例子就清楚了。
假设我们有个文本只包含a-f六个字母,每个字母定长编码如下,我们可以给他们都分配一个变长的编码,频率越高给的编码长度越短,这样总体来说编码的总的长度也会大幅度得到削减。
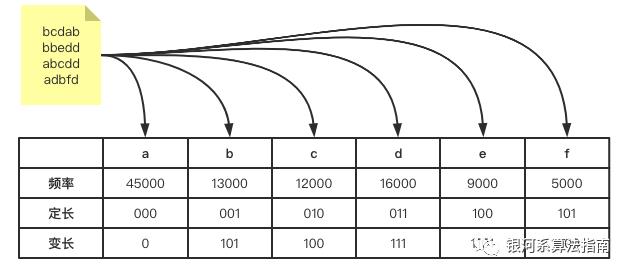
3.2 编码流程
霍夫曼编码的目的就是给出频率与编码的映射关系,得到上面的变长字符编码表,根据该表进行压缩处理,每次存储数据的时候不再使用定长的方式处理,而是通过查阅编码表进行字符和二进制的转换。如何才能构造出映射表呢?我们这里就需要使用到贪心算法来完成了啦。
在编码过程中我们的宗旨就是频率越高,编码长度越短,而频率越低则编码长度越长,这样从而实现总体的收益是最大的。霍夫曼编码通过树形结构来实现上面的目的,通过一步步的形成子树求解当前最优解,最终形成全局最优解。的具体流程如下:
1. 获得每个字符和频率的数据
2. 将该数据放入一个按照频率进行排序的优先队列(优先队列可以看做是一种自动帮您维持优先顺序的列表结构,提供取最小值的操作)
3. 每次从队列中取两个最小频率元素进行合并,合并后结果重新放入优先队列中
4. 再次选择两个最小频率元素进行合并,重复上面的流程
5. 直到队列中只剩下一个元素后形成的结果即可导出为编码表。
举个例子,假设我们读取的文件,并扫描整个的文件获得其频率信息如下面所示,每个字符以及对应的频率都标记在节点上。

首先选择最小的两个元素,分别是对应频率为5000次的f和频率为9000次的e,注意我们总是将数值较小的放置在左边,合并的过程就是选择最小的两个元素,求和形成一个根节点,重新放置到优先队列中,队列自动执行排序后存入指定的位置。
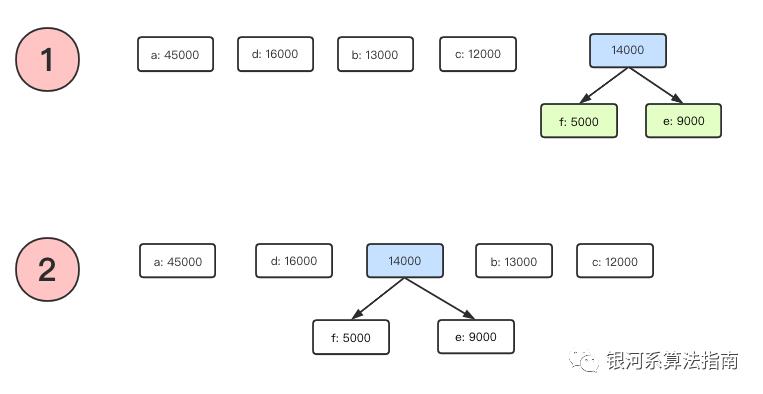
再次选择两个最小的元素分别是b节点和c节点,这两个节点同样执行上面的逻辑后整个的结果集合如下:
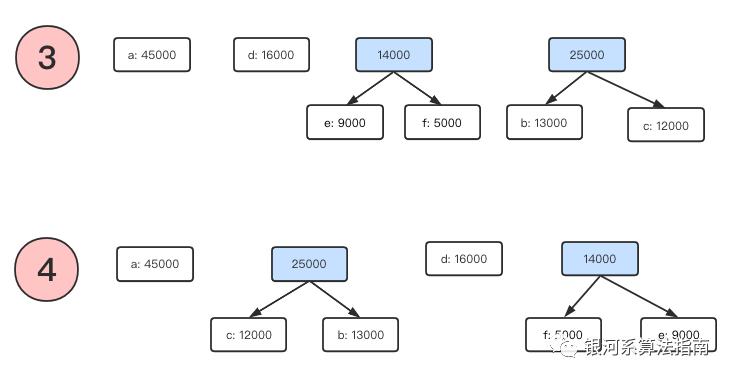
重复执行上面的处理逻辑,直到队列中值取完,无法再进行合并,也就是只有一个元素。
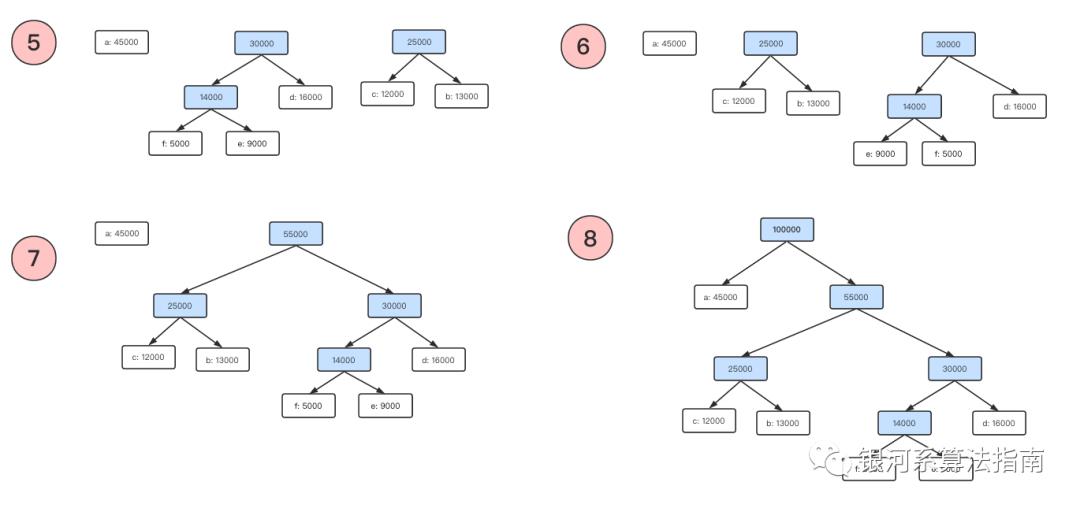
这时候仅有一个树形结构,整个合并阶段完成,之后进入标记阶段,其实并非真正的标记,我们只是对于树形的一种遍历,假如一颗树中左子树节点为当前节点的值+0,右子树结点为当前值+1,通过这种方式,最终得到整个的编码表。
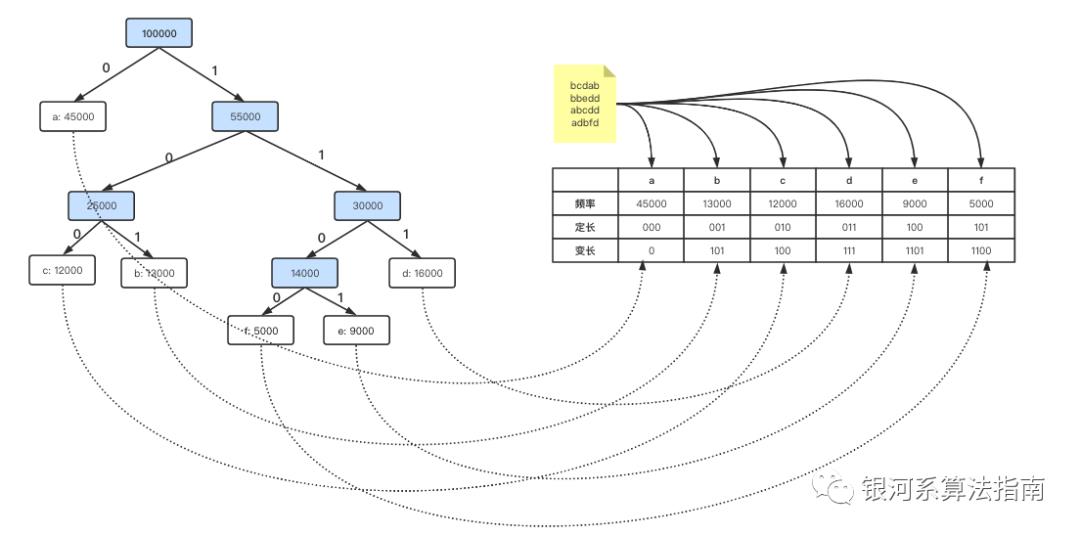
霍夫曼编码的原理和实现都并不复杂,其核心就是利用贪心算法来完成子问题的拆解,每个子问题都选择当前最优解来处理,最终一步步的合并成为全局的最优解。其他的针对贪心算法的典型应用还包括:
最小生成树问题,其中包含的Prim和Kruskal算法都是一种典型的贪心算法
最短路径问题,比如Dijkstra算法 (图算法,也是一个很酷的主题)
一些任务调度,资源调度算法中也有使用贪心算法实现资源的分配。
扫码二维码
获取更多内容
银河系算法指南
以上是关于贪心算法,用最简单的逻辑解决最复杂的问题的主要内容,如果未能解决你的问题,请参考以下文章