机器学习实战之朴素贝叶斯
Posted Python中文社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习实战之朴素贝叶斯相关的知识,希望对你有一定的参考价值。
.jpg")
1.1、简介
贝叶斯分类是一类分类算法的总称,这类算法均以贝叶斯定理为基础,故统称为贝叶斯分类。已知某条件概率,如何得到两个事件交换后的概率,也就是在已知P(A|B)的情况下如何求得P(B|A)。这里先解释什么是条件概率:P(A|B)表示事件B已经发生的前提下,事件A发生的概率,叫做事件B发生下事件A的条件概率。其基本求解公式为:
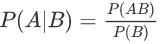
贝叶斯定理之所以有用,是因为我们在生活中经常遇到这种情况:我们可以很容易直接得出P(A|B),P(B|A)则很难直接得出,但我们更关心P(B|A),贝叶斯定理就为我们打通从P(A|B)获得P(B|A)的道路。贝叶斯公式即为:
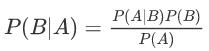
1.2、简介朴素贝叶斯分类原理
基础思想:对于给出的待分类项,求解在此项出现的条件下各个类别出现的概率,哪个最大,就认为此待分类项属于哪个类别。算法步骤如下:
1、找到一个已知分类的待分类项集合,这个集合叫做训练样本集。
2、统计得到在各类别下各个特征属性的条件概率估计,即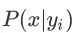
3、如果各个特征属性条件独立,有如下推导:
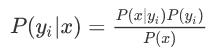
因为分母对于所有类别为常数,要找概率最大的类别,我们找到分子最大的就行。又因为各特征属性是条件独立的,所以:
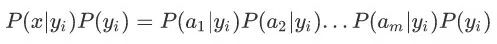
注意:如果某个类别的概率为0,那么整个概率的乘积为0,为避免这种现象的产生,我们引入Laplace校准,可以初始化所有的类别出现的频率为1。
1.3、Python实践朴素贝叶斯分类
以在线社区的留言板为例。为了不影响社区的发展,我们要屏蔽侮辱性的言论,所以要构建一个快速过滤器,如果某条留言使用了负面或者侮辱性的语言,那么就将该留言标识为内容不当。过滤这类内容是一个很常见的需求。对此问题建立两个类别:侮辱类和非侮辱类,使用1和0分别表示。接下来首先给出将文本转换为数字向量的过程,然后介绍如何基于这些向量来计算条件概率,并在此基础上构建分类器,实现文档分类。
1、准备数据:从文本中构建词向量
我们将把文本看成单词向量或者词条向量,也就是说将句子转换为向量。考虑出现在所有文档中的所有单词,再决定将哪些词纳入词汇表或者说所要的词汇集合,然后必须要将每一篇文档转换为词汇表上的向量。
import numpy as np
import math
def load_set():
# 词表到向量的转换函数
posting_list = [['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'],
['maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid'],
['my', 'damn', 'is', 'so', 'cute', 'I', 'love', 'him'],
['stop', 'posting', 'stupid', 'worthless', 'garbage'],
['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop', 'him'],
['quit', 'buying', 'worthless', 'dog', 'food', 'stupid']]
class_vec = [0, 1, 0, 1, 0, 1]
return posting_list, class_vec
def create_set(data_set):
voc_set = set()
# set函数只能处理1*n的list
for document in data_set:
voc_set = voc_set | set(document)
# 求并集
return list(voc_set)
def set2vec(voc_set, input_set):
return_vec = [0] * len(voc_set)
for word in input_set:
if word in voc_set:
return_vec[voc_set.index(word)] = 1
# 关于list的index方法,返回查找对象在list中的索引位置
return return_vec以斑点犬网站上的留言为例,第一篇文档,转换后的词向量结果为:
print(set2vec(word_set, word_list[0]))[0, 0, 1, 0, 1, 1, 1, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0]
2、训练算法:从词向量计算概率
代码函数中的输入参数为文档矩阵,以及由每篇文档类别标签所构成的向量 。首先,计算文档属于侮辱性文档的概率,即 p_abusive 。因为这是一个二类分类问题,所以可以通过 1-p_abusive 得到 P(0) 。对于多于两类的分类问题,则需要对代码稍加修改。需要初始化程序中的分子变量和分母变量 。由于w中元素如此众多,因此可以使用NumPy数组快速计算这些值。 for 循环中,要遍历训练集 trainMatrix 中的所有文档。一旦某个词语(侮辱性或正常词语)在某一文档中出现,则该词对应的个数( p1Num 或者 p0Num )就加1,而且在所有的文档中,该文档的总词数也相应加1 。对于两个类别都要进行同样的计算处理。最后,对每个元素除以该类别中的总词数 。
def train(train_matrix, train_category):
# 朴素贝叶斯分类器训练函数
num_train = len(train_matrix)
num_words = len(train_matrix[0])
p_abusive = sum(train_category)/float(num_train)
p0num = np.ones(num_words)
p1num = np.ones(num_words)
p0_denom = 2.0
p1_denom = 2.0
p0vec = []
p1vec = []
for i in range(num_train):
if train_category[i] == 1:
p1num += train_matrix[i]
p1_denom += sum(train_matrix[i])
else:
p0num += train_matrix[i]
p0_denom += sum(train_matrix[i])
for i in range(num_words):
p0vec.append(math.log(p0num[i] / p0_denom))
p1vec.append(math.log(p1num[i] / p1_denom))
# 取对数是为了防止多个很小的数相乘使得程序下溢出或者得到不正确答案。
return p_abusive, p0vec, p1vec3、对文档进行分类
导入另外两篇我们不知道分类的文档,通过已经训练好的朴素贝叶斯算法来对其进行分类,函数classify()是选取分类概率最大的类别。
def classify(vec2classify, p0vec, p1vec, pclass1):
p0 = sum(vec2classify * p0vec) + math.log(pclass1)
p1 = sum(vec2classify * p1vec) + math.log(1.0-pclass1)
if p1 > p0:
return 1
else:
return 0
if __name__ == "__main__":
word_list, class_list = load_set()
word_set = create_set(word_list)
train_mat = []
for j in range(len(word_list)):
train_mat.append(set2vec(word_set, word_list[j]))
p_a, p0v, p1v = train(train_mat, class_list)
test_entry = ['love', 'my', 'dalmation']
this_doc = np.array(set2vec(word_set, test_entry))
print("%s is classified as:%d"%(test_entry, classify(this_doc, p0v, p1v, p_a)))
test_entry = ['stupid', 'garbage']
this_doc = np.array(set2vec(word_set, test_entry))
print("%s is classified as:%d"%(test_entry, classify(this_doc, p0v, p1v, p_a)))文档分类结果为:
[‘love’, ‘my’, ‘dalmation’] is classified as:0
[‘stupid’, ‘garbage’] is classified as:1
Python中文社区作为一个去中心化的全球技术社区,以成为全球20万Python中文开发者的精神部落为愿景,目前覆盖各大主流媒体和协作平台,与阿里、腾讯、百度、微软、亚马逊、开源中国、CSDN等业界知名公司和技术社区建立了广泛的联系,拥有来自十多个国家和地区数万名登记会员,会员来自以公安部、工信部、清华大学、北京大学、北京邮电大学、中国人民银行、中科院、中金、华为、BAT、谷歌、微软等为代表的政府机关、科研单位、金融机构以及海内外知名公司,全平台近20万开发者关注。
▼ 点击下方阅读原文,免费成为社区会员
以上是关于机器学习实战之朴素贝叶斯的主要内容,如果未能解决你的问题,请参考以下文章
NBC朴素贝叶斯分类器 ————机器学习实战 python代码