机器学习实战—— 朴素贝叶斯代码实现
Posted 人工智能爱好者社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习实战—— 朴素贝叶斯代码实现相关的知识,希望对你有一定的参考价值。
在上一篇我们通俗易懂讲解了朴素贝叶斯算法,本节我们用Python实现一下。
本次实战内容为20类新闻文本的多分类。
数据可以通过如下代码直接下载:
#20类新闻文本的数据内容(下载数据需要一定时间)
# 从sklearn.datasets里导入新闻数据抓取器fetch_20newsgroups。
from sklearn.datasets import fetch_20newsgroups
# 与之前预存的数据不同,fetch_20newsgroups需要即时从互联网下载数据。
news = fetch_20newsgroups(subset='all')
# 查验数据规模和细节。
print(len(news.data))
print(news.data[0])
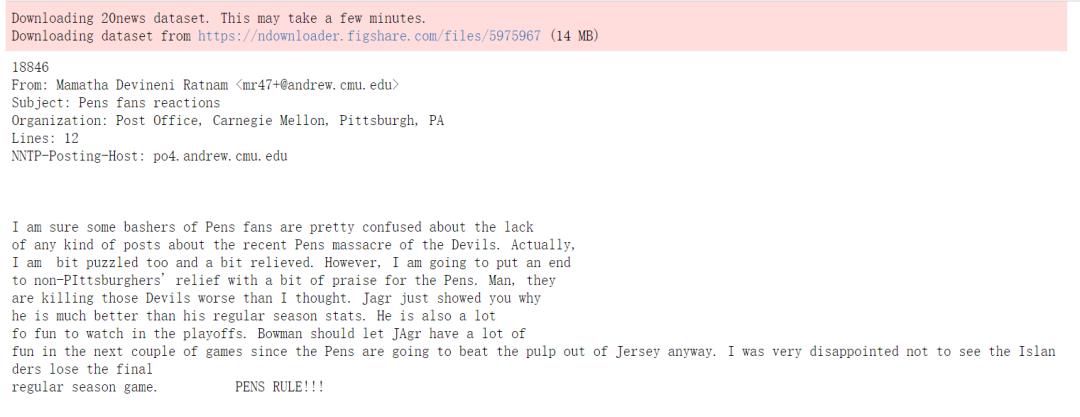
通过上面内容可以看到有18846条数据。
然后打印了第一篇新闻的内容。
之后进行训练集和测试集划分:
# 从sklearn.cross_validation 导入 train_test_split。
from sklearn.cross_validation import train_test_split
# 随机采样25%的数据样本作为测试集。
X_train, X_test, y_train, y_test = train_test_split(news.data, news.target, test_size=0.25, random_state=33)
由于数据是文本,通常将其转为向量,然后导入朴素贝叶斯模型进行训练和预测:
# 从sklearn.feature_extraction.text里导入用于文本特征向量转化模块将文本转化为特征向量。属于特征抽取
from sklearn.feature_extraction.text import CountVectorizer
vec = CountVectorizer()
X_train = vec.fit_transform(X_train)
X_test = vec.transform(X_test)
# 从sklearn.naive_bayes里导入朴素贝叶斯模型。
from sklearn.naive_bayes import MultinomialNB
# 从使用默认配置初始化朴素贝叶斯模型。
mnb = MultinomialNB()
# 利用训练数据对模型参数进行估计。
mnb.fit(X_train, y_train)
# 对测试样本进行类别预测,结果存储在变量y_predict中。
y_predict = mnb.predict(X_test)
之后打印输出分类结果报告:
# 从sklearn.metrics里导入classification_report用于详细的分类性能报告。
from sklearn.metrics import classification_report
print('The accuracy of Naive Bayes Classifier is', mnb.score(X_test, y_test))
print(classification_report(y_test, y_predict, target_names = news.target_names))
我们可以看到,结果如下:
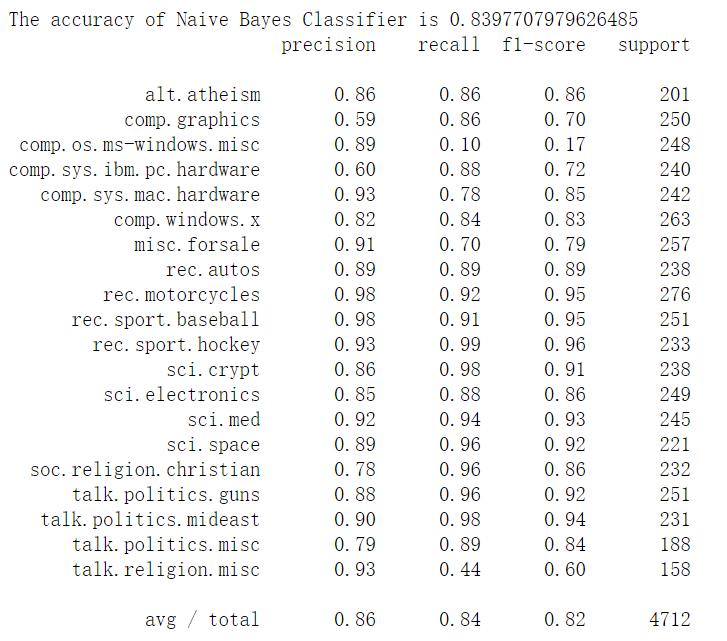
给出了20类和总结果的各项评估指标,包括准确率、召回率、F1分数、样本量情况。
这就是朴素贝叶斯的代码实现,是不是很容易呢?
朴素贝叶斯被广泛应用于海量互联网文本分类任务,由于其较强的特征条件独立假设,使得模型预测所需要估计的参数规模大大减小,极大节约了内存消耗和计算时间。
但是,正因为这种强假设的限制,模型训练时无法将各个特征之间的联系考量在内,使得模型在特征关联性较强的分类任务上性能表现不佳!
【人工智能社群】已经成立,旨在打造真正有价值,能交流,一起学习成长的社群,并且每月送书不断!现备注城市+昵称+研究方向,扫码添加好友后立即进群。
▲长按扫码
以上是关于机器学习实战—— 朴素贝叶斯代码实现的主要内容,如果未能解决你的问题,请参考以下文章