4.机器学习实战之朴素贝叶斯
Posted Wang_AI
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了4.机器学习实战之朴素贝叶斯相关的知识,希望对你有一定的参考价值。
上一篇:决策树
1. 简单理论介绍
1.1 贝叶斯定理
了解贝叶斯定理之前,需要先了解下条件概率。P(A|B)表示在事件B已经发生的条件下事件A发生的概率:
P(A|B)=P(AB) P(B)daf afdfd
假如我们已经知道了P(A|B),但是现在我们想要求P(B|A),也就是在事件A发生的条件下事件B发生的概率,这时贝叶斯定理就派上用场了。
P(B|A)=P(A|B)P(B) P(A)daf afdfd
1.2 朴素贝叶斯分类原理
朴素贝叶斯分类是以贝叶斯定理为基础的,之所以称为“朴素”,是因为整个过程只做最原始、最简单的假设。假设我们现在有一个训练数据集,该数据集的特征向量为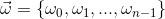 ,n表示特征的个数,同时也有该数据集的类别标签向量
,n表示特征的个数,同时也有该数据集的类别标签向量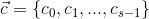 ,s表示类别的个数,现在就是要计算
,s表示类别的个数,现在就是要计算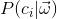 ,i=[0,s-1],也就是说根据现有的这些特征来计算它所属类别标签中的每个类别的概率,最后取概率最大的分类标签为结果。那么如何计算呢?由贝叶斯定理可得:
,i=[0,s-1],也就是说根据现有的这些特征来计算它所属类别标签中的每个类别的概率,最后取概率最大的分类标签为结果。那么如何计算呢?由贝叶斯定理可得:
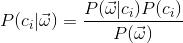
假设特征之间互相独立,则:
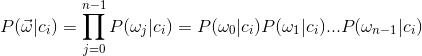
由于分母P(w)的值都一样,所以只需计算分子就可以了,即:
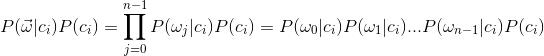
接下来我们用一个例子来说明下朴素贝叶斯分类原理,该例子来源于阮一峰的《朴素贝叶斯分类器的应用》。根据某社区网站的抽
样统计,该站10000个账号中有89%为真实账号(设为C0),11%为虚假账号(设为C1),P(C0)=0.89,P(C1)=0.11。
接下来,就要用统计资料判断一个账号的真实性。假定某一个账号有以下三个特征:
W0: 日志数量/注册天数
W1: 好友数量/注册天数
W2: 是否使用真实头像(真实头像为1,非真实头像为0)
W0 = 0.1
W1 = 0.2
W2 = 0根据上面的三个特征去判断这个账号是否真实。
方法是计算P(W0|C=0)P(W1|C=0)P(W2|C=0)P(C=0)和P(W0|C=1)P(W1|C=1)P(W2|C=1)P(C=1)的值,如果前者大,说明为真实账
号,否则为虚假账号。
虽然上面这些值可以从统计资料得到,但是这里有一个问题:W0和W1是连续变量,不适宜按照某个特定值计算概率。一个技巧是
将连续值变为离散值,计算区间的概率。比如将W0分解成[0, 0.05]、(0.05, 0.2)、[0.2, +∞]三个区间,然后计算每个区间的概率。在
我们这个例子中,W0等于0.1,落在第二个区间,所以计算的时候,就使用第二个区间的发生概率。
P(W0|C=0) = 0.5, P(W0|C=1) = 0.1
P(W1|C=0) = 0.7, P(W1|C=1) = 0.2
P(W2|C=0) = 0.2, P(W2|C=1) = 0.9
因此:
P(W0|C=0)P(W1|C=0)P(W2|C=0)P(C=0)
= 0.5 x 0.7 x 0.2 x 0.89
= 0.0623
P(W0|C=1)P(W1|C=1)P(W2|C=1)P(C=1)
= 0.1 x 0.2 x 0.9 x 0.11
= 0.00198
可以看到,虽然这个用户没有使用真实头像,但是他是真实账号的概率,比虚假账号高出30多倍,因此判断这个账号为真。
1.3 朴素贝叶斯分类的优缺点
优点:计算简单,在数据量很大时计算速度很快
缺点:假设特征之间是相互独立的
2. 文本向量
在本篇文章中我们想要使用朴素贝叶斯分类器来将留言板上的留言内容分为两类:侮辱性言论和正常言论,分别用1和0来表示。但是这儿有一个问题就是,如何让计算机出识别这些文本呢?这时我们可以考虑将文本转换成文本向量。文本向量其实就是特征向量。
我们先来了解几个概念,我们将留言板上的每一条留言内容称为文档,而文档(在这里指每一条留言内容)是由词条组成的,词条的是指字符的任意组合,在这里你可以将它认为是单词,同时我们将所有留言内容称为文档库。关系如下图:
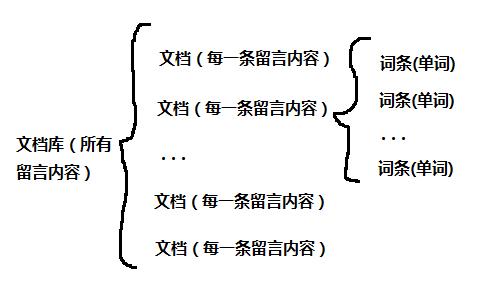
现在我们要构建文本向量,在这儿就是将文档(一条留言内容)转换为一个向量。有两种构建方法:词集模型(set-of-words model)和词袋模型(bag-of-words model)。
2.1 词集模型
我们先介绍词集模型。首先我们需要从文档库(即所有的留言内容中)找到所有的词条(单词),将这些单词称为词汇表。如果要对某一文档构建文本向量,首先先创建一个长度为词汇表长度的向量,该向量的每一个元素为1或0,1代表词汇表中的词条在该文档(一条留言内容)中出现过,0则相反。例如,词汇表为{‘my’,'name',‘is’,'tom','and',‘home’,‘is’,‘Beijing’,'am',‘bag’,‘ok’},某一条留言内容为“my name is tom,and my home is Beijing”,将它转为文本向量就是[1,1,1,1,1,1,1,1,0,0,0],文本向量前8个元素为1表示词库表中的前8个词条在该留言内容中出现过,后3个元素为0表示词库表中的最后3个词条在该留言内容中未出现过。注意,虽然,“my”这个词条在该留言内容中出现过两次,但是我们仍然只记为1。也就是说词集模型中向量的元素内容表示词条是否在词汇表中出现过。
2.2 词袋模型
现在来介绍下词袋模型,词袋模型中向量的元素内容表示词条出现在词汇表中的次数。例如上面的“my”,出现两次,如果用词袋模型表示,则文本向量为[2,1,1,1,1,1,1,1,0,0,0]。一般来说使用词袋模型的效果会更好一些。
3. 代码实现
3.1 准备数据
# 准备数据
def loadDataSet():
postingList=[['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'],
['maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid'],
['my', 'dalmation', 'is', 'so', 'cute', 'I', 'love', 'him'],
['stop', 'posting', 'stupid', 'worthless', 'garbage'],
['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop', 'him'],
['quit', 'buying', 'worthless', 'dog', 'food', 'stupid']]
classVec = [0,1,0,1,0,1] #1代表侮辱性言论,0代表正常言论
return postingList,classVec
3.2 创建词汇表
# 创建词汇表
def createVocabList(dataSet):
vocabSet = set([]) #create empty set
for document in dataSet:
vocabSet = vocabSet | set(document) #创建两个集合的并集
return list(vocabSet)
3.3 构建文本向量
# 词集模型文本向量
# vocabList:词汇表,inputSet:文本内容
def setOfWords2Vec(vocabList, inputSet):
returnVec = [0]*len(vocabList)# 创建一个长度为词汇表长度的集合
for word in inputSet:
if word in vocabList:
returnVec[vocabList.index(word)] = 1#出现就赋值为1
else: print "the word: %s is not in my Vocabulary!" % word
return returnVec
# 词库模型文本向量
def bagOfWords2VecMN(vocabList, inputSet):
returnVec = [0]*len(vocabList)
for word in inputSet:
if word in vocabList:
returnVec[vocabList.index(word)] += 1#出现一次就将次数加1
else: print "the word: %s is not in my Vocabulary!" % word
return returnVec
测试上面的效果:
listOppsts,listClasses = loadDataSet()
myVocabList = createVocabList(listOppsts)
print '词汇表:',myVocabList
print '词集模型向量:',setOfWords2Vec(myVocabList,listOppsts[0])#将第一条留言内容转成词集模型向量
print '词袋模型向量:',bagOfWords2VecMN(myVocabList,listOppsts[0])#将第一条留言内容转成词袋模型向量
运行结果:
词汇表: ['cute', 'love', 'help', 'garbage', 'quit', 'I', 'problems', 'is', 'park', 'stop', 'flea', 'dalmation', 'licks', 'food', 'not', 'him', 'buying', 'posting', 'has', 'worthless', 'ate', 'to', 'maybe', 'please', 'dog', 'how', 'stupid', 'so', 'take', 'mr', 'steak', 'my']
词集模型向量: [0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 1]
词袋模型向量: [0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 1]
3.4 训练算法:文本向量计算概率
我们已经得到了特征向量(即文本向量),现在要做的是根据这些特征向量去计算每个类别下各个特征的概率,类似于我们上面例子中从统计资料中得到概率这一过程。
import numpy as np
# 从训练文档的特征向量中计算各个类别下特征的概率
# trainMatrix:训练文档的特征向量(MxN),trainCategory:训练文档的类别标签(1xM)
# M表示训练集的个数,N表示词汇表长度,也就是特征个数
def trainNB0(trainMatrix,trainCategory):
m = len(trainMatrix)# 训练文档的个数
n = len(trainMatrix[0])# 词汇表长度,也就是词条的个数,也就是特征个数。
p0Num = np.zeros(n); p1Num = np.zeros(n) #change to ones()
p0Denom = 0.0; p1Denom = 0.0 #change to 2.0
for i in range(m):
if trainCategory[i] == 1:#类别为侮辱性言论
p1Num += trainMatrix[i]#得到一个向量,该向量元素的值为词汇表中的每个词条在侮辱性言论(c=1)类别里出现的次数
p1Denom += sum(trainMatrix[i])#得到侮辱性言论类别词条出现的总数
else:# 类别为正常言论
p0Num += trainMatrix[i]#同上
p0Denom += sum(trainMatrix[i])#同上
p1Vect = p1Num/p1Denom#计算在侮辱性言论类别下每个词条出现的概率,p1Vect是一个向量,向量的元素为P(w=0|c=1),P(w=1|c=1),...,P(w=n|c=1)
p0Vect = p0Num/p0Denom
pAbusive = sum(trainCategory)/float(m)# 计算侮辱性言论文档在整个训练文档中出现的概率,即P(c=1)
return p0Vect,p1Vect,pAbusive
测试下上面方法的效果:
listOppsts,listClasses = loadDataSet()
myVocabList = createVocabList(listOppsts)#得到词汇表
trainMat = []#创建一个空列表
for postinDoc in listOppsts:
trainMat.append(setOfWords2Vec(myVocabList,postinDoc))#将每一个文档(每一个评论内容)转为文本向量,并存入trainMat中
p0V,p1V,pAb = trainNB0(trainMat,listClasses)#训练分类器,得到p0V,p1V,pAb
print 'P(c=1):',pAb
print 'p(w|c=1):',p1V
print 'p(w|c=0):',p0V
运行结果:
P(c=1): 0.5
p(w|c=1): [ 0. 0. 0. 0.05263158 0.05263158 0. 0.
0. 0.05263158 0.05263158 0. 0. 0.
0.05263158 0.05263158 0.05263158 0.05263158 0.05263158 0.
0.10526316 0. 0.05263158 0.05263158 0. 0.10526316
0. 0.15789474 0. 0.05263158 0. 0. 0. ]
p(w|c=0): [ 0.04166667 0.04166667 0.04166667 0. 0. 0.04166667
0.04166667 0.04166667 0. 0.04166667 0.04166667 0.04166667
0.04166667 0. 0. 0.08333333 0. 0.
0.04166667 0. 0.04166667 0.04166667 0. 0.04166667
0.04166667 0.04166667 0. 0.04166667 0. 0.04166667
0.04166667 0.125 ]
P(c=1)的值为0.5,表示所有留言内容中有一半的留言内容是侮辱性言论,查看下我们创建的训练集,发现该值是正确的。词汇表中第一个词条是“cute”,在类别1中没有出现过,在类别0中出现过1次,对应的条件概率是0和0.04166667,说明计算正确。
3.5 改进分类器
利用朴素贝叶斯分类器对文档进行分类时,要计算多个概率的乘积以获得文档属于某类别的概率,即计算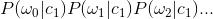 ,如果其中的一个概率为0,那么乘积也为0,为降低这种影响,可以将所有词条出现的次数初始化为1,并将分母初始化为2。另一个要解决的问题是下溢出。由于计算乘积时,每个概率值都比较小,所以很可能溢出,可以考虑使用对数来解决。在代数中有In(a*b) = In(a) + In(b)。修改后的分类器代码如下:
,如果其中的一个概率为0,那么乘积也为0,为降低这种影响,可以将所有词条出现的次数初始化为1,并将分母初始化为2。另一个要解决的问题是下溢出。由于计算乘积时,每个概率值都比较小,所以很可能溢出,可以考虑使用对数来解决。在代数中有In(a*b) = In(a) + In(b)。修改后的分类器代码如下:
import numpy as np
# 从训练文档的特征向量中计算各个类别下特征的概率
# trainMatrix:训练文档的特征向量(MxN),trainCategory:训练文档的类别标签(1xM)
# M表示训练集的个数,N表示词汇表长度,也就是特征个数
def trainNB0(trainMatrix,trainCategory):
m = len(trainMatrix)# 训练文档的个数
n = len(trainMatrix[0])# 词汇表长度,也就是词条的个数,也就是特征个数。
<span style="color:#CC0000;">p0Num = np.ones(n); p1Num = np.ones(n)</span> #change to ones()
p0Denom = 2.0; p1Denom = 2.0 #change to 2.0
for i in range(m):
if trainCategory[i] == 1:#类别为侮辱性言论
p1Num += trainMatrix[i]#得到一个向量,该向量元素的值为词汇表中的每个词条在侮辱性言论(c=1)类别里出现的次数
p1Denom += sum(trainMatrix[i])#得到侮辱性言论类别词条出现的总数
else:# 类别为正常言论
p0Num += trainMatrix[i]#同上
p0Denom += sum(trainMatrix[i])#同上
<span style="color:#CC0000;">p1Vect = np.log(p1Num/p1Denom)</span>#计算在侮辱性言论类别下每个词条出现的概率,p1Vect是一个向量,向量的每个元素表示P(w=0|c=1),P(w=1|c=1),...,P(w=n|c=1)
<span style="color:#CC0000;">p0Vect = np.log(p0Num/p0Denom)</span>#p0Vect向量的每个元素表示P(w=0|c=0),P(w=1|c=0),...,P(w=n|c=0)
pAbusive = sum(trainCategory)/float(m)# 计算侮辱性言论文档在整个训练文档中出现的概率,即P(c=1)
return p0Vect,p1Vect,pAbusive
3.6 使用分类器进行分类
# 朴素贝叶斯分类器
def classifyNB(vec2Classify, p0Vec, p1Vec, pClass1):
p1 = sum(vec2Classify * p1Vec) + np.log(pClass1) #element-wise mult
p0 = sum(vec2Classify * p0Vec) + np.log(1.0 - pClass1)
if p1 > p0:
return 1
else:
return 0
def testingNB():
listOPosts,listClasses = loadDataSet()
myVocabList = createVocabList(listOPosts)#得到词汇表
trainMat=[]
for postinDoc in listOPosts:#得到文档集的所有文本向量
trainMat.append(setOfWords2Vec(myVocabList, postinDoc))
p0V,p1V,pAb = trainNB0(np.array(trainMat),np.array(listClasses))
testEntry = ['love', 'my', 'dalmation']
thisDoc = np.array(setOfWords2Vec(myVocabList, testEntry))
print testEntry,'classified as: ',classifyNB(thisDoc,p0V,p1V,pAb)
testEntry = ['stupid', 'garbage']
thisDoc = np.array(setOfWords2Vec(myVocabList, testEntry))
print testEntry,'classified as: ',classifyNB(thisDoc,p0V,p1V,pAb)
测试结果:
testingNB()
运行结果:
['love', 'my', 'dalmation'] classified as: 0
['stupid', 'garbage'] classified as: 1
下一篇:Logistic回归
想学人工智能(Python、数据分析、机器学习、深度学习、推荐系统、强化学习),来公众号AI派看看吧!!

以上是关于4.机器学习实战之朴素贝叶斯的主要内容,如果未能解决你的问题,请参考以下文章