R语言聚类算法在新媒体中的场景应用
Posted 壹看板
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了R语言聚类算法在新媒体中的场景应用相关的知识,希望对你有一定的参考价值。
— 壹看板导读 —
DT时代,大数据、机器学习对各行各业的从业者并不陌生,机器学习应用场景比较集中在医疗、保险、金融等大数据量级领域。新媒体领域中,大数据可以为我们解决什么场景下的问题呢?本篇文章将给出如何利用聚类算法对新媒体文章内容价值做评估的解决方案,为今后文章内容采编做指导,用R语言实现自动和半自动化。
什么是聚类?“物以类聚,人以群分”
对事物进行分类是人们认识事物的出发点,也是人们认识世界的一种重要方法。聚类就是将数据分组成多个类别(cluster),使得同一个类别的对象之间具有较高的相似度,不同类别的对象相异。
新媒体文章价值评估就是对历史发布在新媒体的文章进行研究分类,数据量级越大效果越明显,针对每类的文章下定义标签,为今后文章的内容和采编方向做指导。
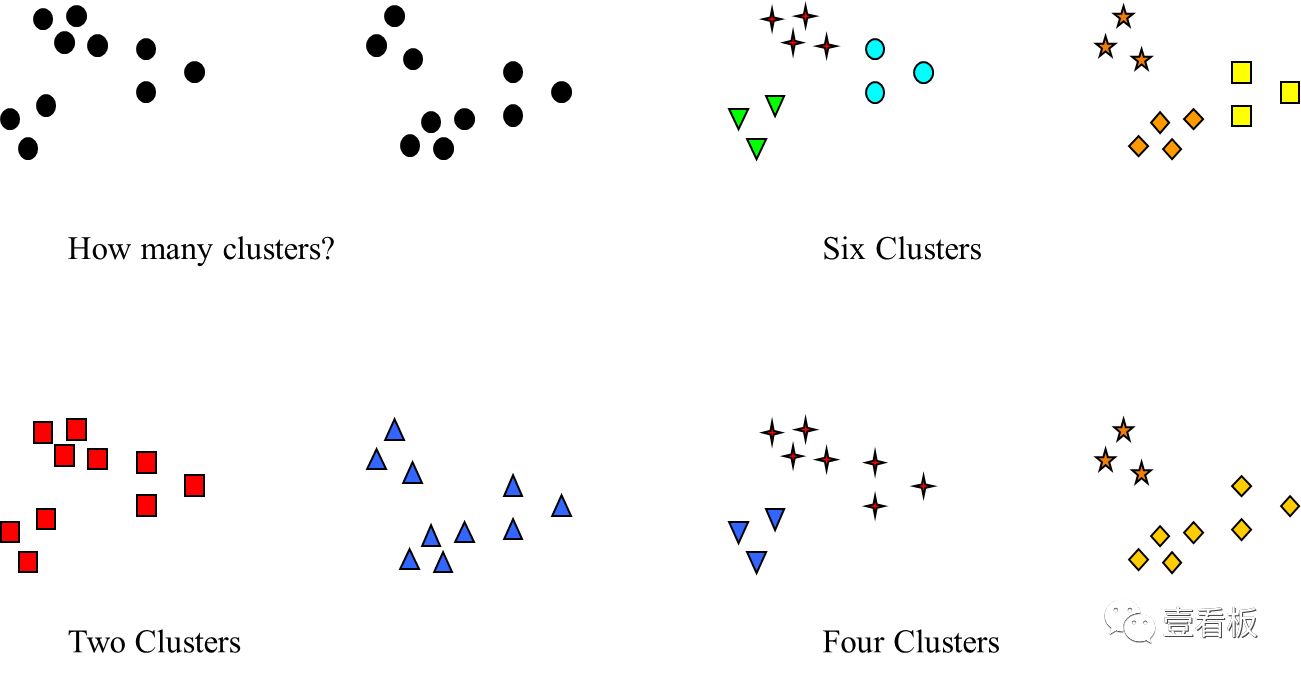
聚类图解

聚类指标需要根据业务结果来选择,对新媒体运营影响比较大的指标可以选入模型。
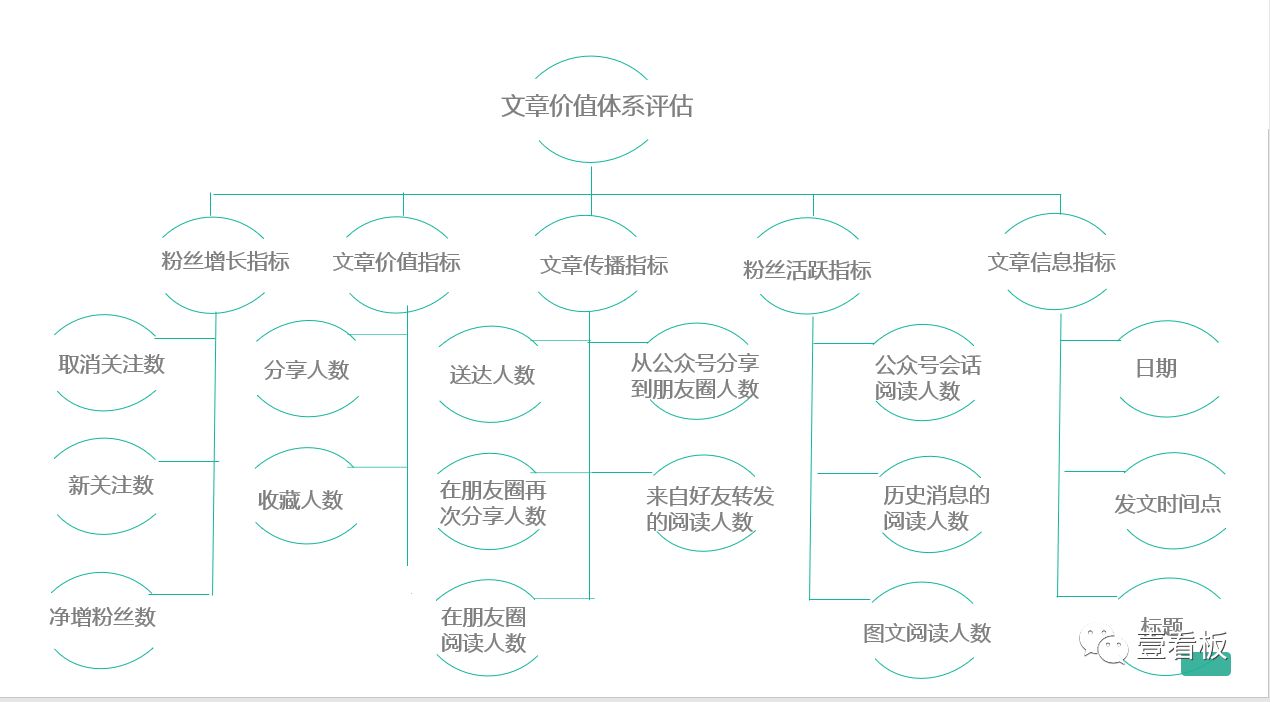
指标框架
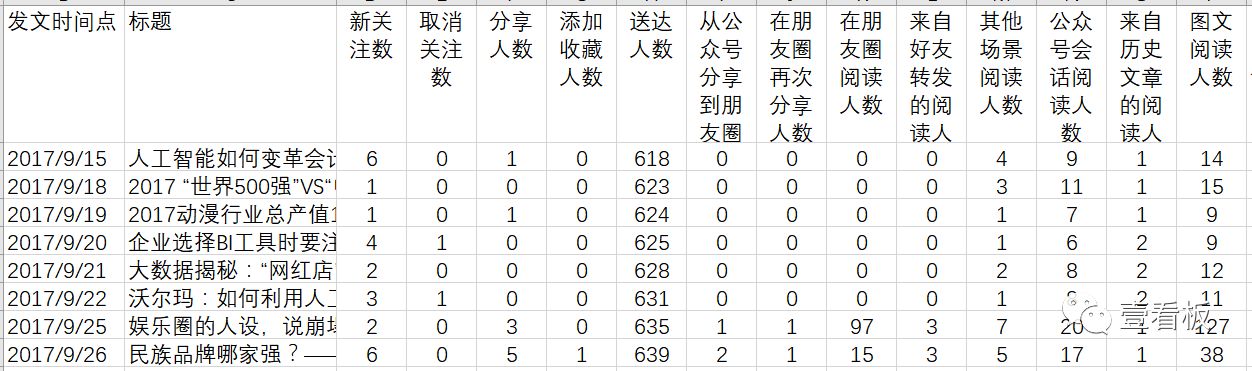
注:该演示数据仅60条,且值都比较小,文章聚类效果会稍不明显,仅用于提供思路,做文章分析建议以1年以上历史数据分析。
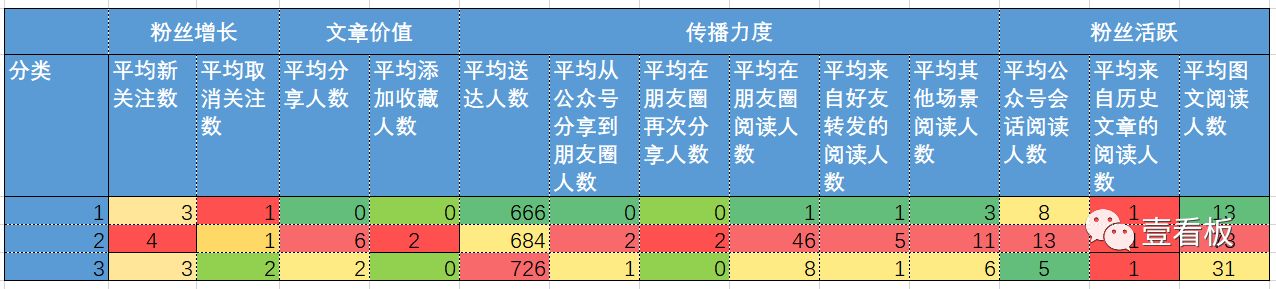
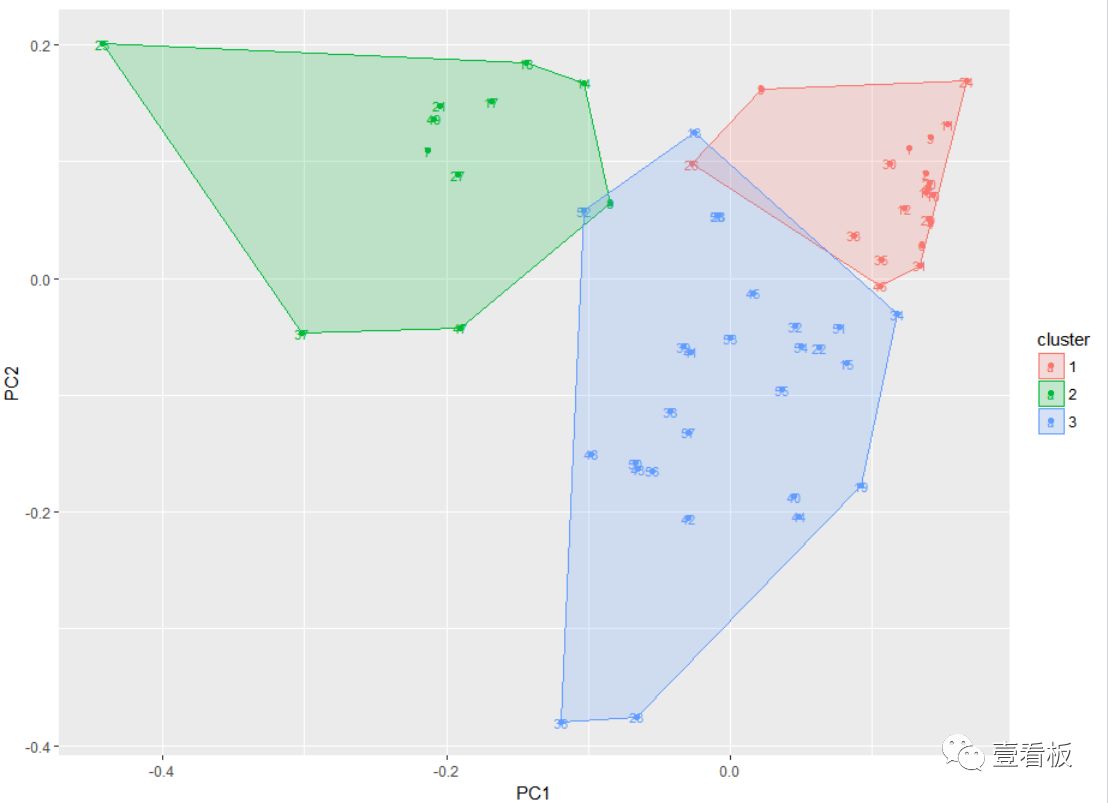
数据结果展示
基于以上,针对新媒体文章的指标,可以将文章数据做解读并归结为3类:
第一类:粉丝增长一般,文章价值比较差,传播力度比较差,粉丝不活跃;
第二类:粉丝增长比较好,文章比较有价值,传播力度比较强,粉丝比较活跃;
第三类:粉丝取关人数多,文章价值一般,传播力度一般,粉丝不活跃;
接下来则需要运营人员针对每类文章进行单篇的具体分析:为什么好,又为什么差——找到这一类文章整体的特点,建立文章价值的评估,然后今后文章的采编和内容方向就很容易把控了。

R代码供参考
---------END----------
ps:想进群交流分享怎么办?
更有福利
数据大牛干货传授~
以上是关于R语言聚类算法在新媒体中的场景应用的主要内容,如果未能解决你的问题,请参考以下文章