R语言实现密度聚类
Posted 数据分析艺术
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了R语言实现密度聚类相关的知识,希望对你有一定的参考价值。
1 在R中实现该算法的为fpc包中的函数dbscan()。基本格式如下:
dbscan(data, eps, MinPts = 5, scale = FALSE, method = c("hybrid", "raw", "dist"), seeds = TRUE, showplot = FALSE, countmode = NULL)
其中,data表示待聚类数据集或者距离矩阵;eps为划分样本点的半径;MinPts为密度半径;scale表示是否标准化;method中"hybrid"表示data为距离矩阵,"raw"表示data为原始数据;dist表示data为原始数据集且计算局部聚类矩阵;showplot表示是否输出聚类结果示意图。
首先安装并加载该软件包。
install.packages("fpc")
library(fpc)
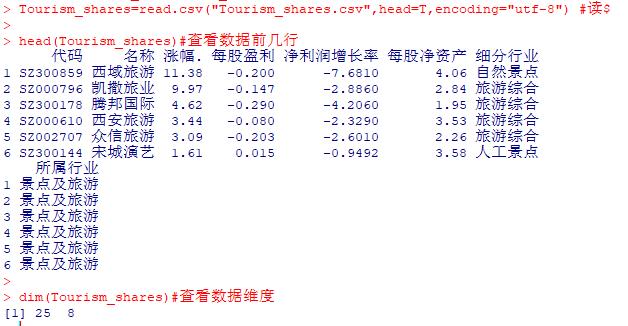
2 读取数据集。
Tourism_shares=read.csv("Tourism_shares.csv",head=T,encoding="utf-8") #读取数据集
head(Tourism_shares)#查看数据前几行
dim(Tourism_shares)#查看数据维度
3 通过不断调整eps和Minpts参数,查看聚类结果,直到border(噪声点)最少。
ds1=dbscan(na.omit(Tourism_shares[,3:6]),eps=2,MinPts=2);ds1
ds2=dbscan(na.omit(Tourism_shares[,3:6]),eps=3,MinPts=3);ds2
#计算距离之后的聚类
ds3=dbscan(dist(na.omit(Tourism_shares[,3:6])),eps=4,MinPts=2);ds3
上面的结果分别把样本分为了6类、2类、4类。
4 绘制聚类效果图。上述算法训练中,ds2的噪声点最少。从图形中可以看到聚类效果。
plot(ds2,na.omit(Tourism_shares[,3:6]),main="raw;eps=3,MinPts=3 ")
以上是关于R语言实现密度聚类的主要内容,如果未能解决你的问题,请参考以下文章