基于密度的图聚类算法 SCAN
Posted 大图计算
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于密度的图聚类算法 SCAN相关的知识,希望对你有一定的参考价值。
大家其实都知道DBSCAN,那是一个在欧几里得空间中对数据节点进行密度聚类的算法,其实图上也有一个基于密度聚类的聚类算法SCAN,最先由Xu等人发表在KDD 2007上。
一、概要
SCAN算法可用来检测网络中的社区、桥节点和离群点。它基于结构相似性度量对顶点进行聚类。该算法特点是:速度快,效率高,每个顶点只访问一次。
主要贡献是能够识别出桥节点和离群点两种特殊点。
二、观察
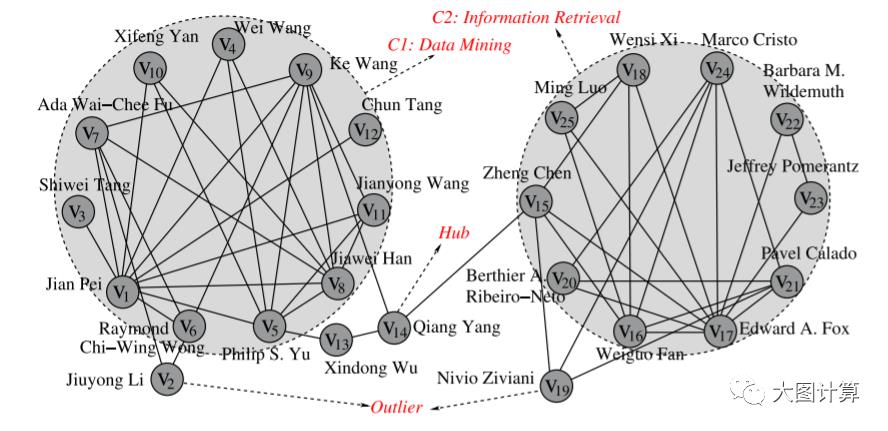
传统的社区发现算法并不区分网络中顶点的角色,因为网络中有些顶点是集群的成员;有些顶点是桥接许多集群但不属于任何集群的桥节点,而有些顶点则是只与特定集群有弱关联的离群点。
现有基于优化模块度的算法,会将这个例子分成两个集群:一个由顶点0到6组成,另一个由顶点7到13组成。它们没有隔离顶点6(一个桥节点,将其划分到在任何一个集群中都是有争议的)或顶点13(一个离群点,它只与网络有一个连接)。
SCAN算法使用顶点的邻域作为聚类标准,而不是只使用它们直接连接。顶点按照它们共同邻域的方式分组到集群中。再次参考上图中的示例:
因此通过SCAN最终目标是确定了两个集群,{0,1,2,3,4,5} 和 {7,8,9,10,11,12},并将顶点 13 作为离群点,将顶点6作为桥节点。
SCAN算法有以下特点将在以下详述:
三、详述
关注简单的、无向、未加权的图。设G = {V, E}为一个图,其中V为顶点集合,E是由不同的顶点(无序)组成的集合,称为边。
定义节点相似度为两个节点共同邻居的数目与两个节点邻居数目的几何平均数的比值(这里的邻居均包含节点自身)。

其中 Γ(x) 表示节点 x 及其相邻节点所组成的集合。
节点的 ϵ-邻居定义为与其相似度不小于 ϵ 的节点所组成的集合。
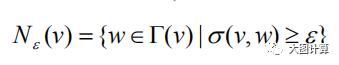
核节点是指ϵ-邻居的数目大于 μ 的节点。节点 w 是核节点 v 的 ϵ-邻居,那么称从 v 直接可达 w。
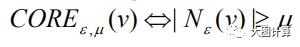
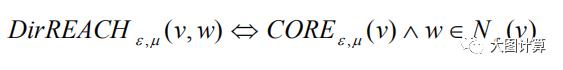
节点 v 可达 w ,当且仅当存在一个节点链 v_1,…,v_n∈V, v_1=v, v_n=w,使得 v_{i+1} 是从 v_i 直接可达的。
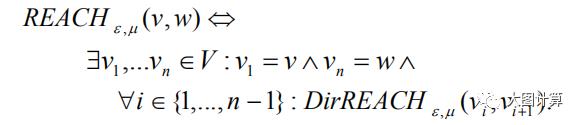
若核节点u可达节点v和节点w,则称节点v和节点w相连。
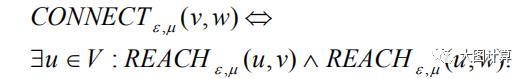
如果一个非空子图C中的所有节点是相连的,并且C是满足可达的最大子图,那么称C是一个相连聚类。
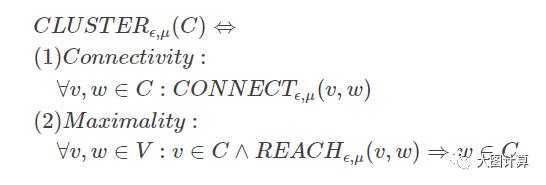
桥节点:与至少两个相连聚类相邻的孤立节点。
离群点:只与一个相连聚类相邻或不与任何相连聚类相邻的孤立节点。
引理一:如果 v 是一个核节点,那么从 v 可达的节点集是一个结构相连聚类。
引理二:C 是一个结构相连聚类, p 是 C 中的一个核节点。那么 C 等于从 p 结构可达的节点集。
算法伪代码如下:
在开始时,所有的顶点都被标记为非分类的。扫描算法对每个顶点进行分类,要么是集群的成员,要么是非成员。
对于尚未分类的每个顶点,扫描检查是否这个顶点的核心(STEP 1)。
如果顶点是核心,则从这个顶点拓展一个新的集群(STEP 2.1)。否则,顶点标注为非成员(STEP2.2)。
为了找到一个新的集群,从任意核心 v 搜索所有可达顶点。由于引理2,这足以找到包含顶点 v 的完整集群。
在STEP 2.2中,会生成一个新的集群ID,该ID将分配给STEP 2.2中找到的所有顶点。
SCAN首先将顶点 v 的所有其 ϵ-邻居放进队列中。对于队列中的每个顶点,它计算所有直接可达的顶点,并将那些仍未分类的顶点插入队列中。重复此操作,直到队列为空。
四、算法分析
对于给定的一个有m条边和n个顶点的图,SCAN首先通过检查图的每个顶点(STEP 1)来查找所有结构连接的群集(需要检索所有顶点的邻居)。图结构使用邻接表存储,其中每个顶点都有一个与之相邻的顶点的列表,邻域查询的成本与邻域的数量成正比,也就是查询顶点的程度。
因此,总代价是O(deg(v1)+deg(v2)+…deg(vn)),其中deg(vi), i = 1,2,…,n是顶点vi的度。总运行时间为O(m)。
如果边的数量未知,还可以根据顶点的数量推导出运行时间。在最坏的情况下,每个顶点连接到一个完整图的所有其他顶点。最坏的情况下,总代价是O(n(n-1))或O(n^2)。
然而,真实的网络通常具有更稀疏的程度分布。在下面的例子中,作者推导出一个平均情况的复杂度。网络的一种类型是随机图,即通过在顶点之间随机放置边来生成随机图。随机图已被广泛应用于各种类型的现实世界网络的模型,特别是在流行病学中。随机图的度具有泊松分布:
这表明大多数节点具有大致相同数量的链接,即接近E(k)=z的平均度。在随机图的情况下,扫描的复杂度为O(n)。
五、最近工作
SCAN算法直觉起源于DBSCAN这一超经典算法,在解决图聚类问题中是一种比较经典的算法,算法生命力也比较强,近三年ICDE、TKDE上都有基于此算法,使用密度对图进行聚类的研究。同时,在分布式环境、多核心、时序图中也有相应的研究。此问题还有研究价值,在未来应该还可以拓展到更多应用场景中。
以上是关于基于密度的图聚类算法 SCAN的主要内容,如果未能解决你的问题,请参考以下文章