简单易学的机器学习算法——基于密度的聚类算法DBSCAN
Posted liqu
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了简单易学的机器学习算法——基于密度的聚类算法DBSCAN相关的知识,希望对你有一定的参考价值。
一、基于密度的聚类算法的概述
最近在Science上的一篇基于密度的聚类算法《Clustering by fast search and find of density peaks》引起了大家的关注(在我的博文“论文中的机器学习算法——基于密度峰值的聚类算法”中也进行了中文的描述)。于是我就想了解下基于密度的聚类算法,熟悉下基于密度的聚类算法与基于距离的聚类算法,如K-Means算法之间的区别。
基于密度的聚类算法主要的目标是寻找被低密度区域分离的高密度区域。与基于距离的聚类算法不同的是,基于距离的聚类算法的聚类结果是球状的簇,而基于密度的聚类算法可以发现任意形状的聚类,这对于带有噪音点的数据起着重要的作用。
二、DBSCAN算法的原理
1、基本概念
DBSCAN(Density-Based Spatial Clustering of Application with Noise)是一种典型的基于密度的聚类算法,在DBSCAN算法中将数据点分为一下三类:
- 核心点。在半径Eps内含有超过MinPts数目的点
- 边界点。在半径Eps内点的数量小于MinPts,但是落在核心点的邻域内
- 噪音点。既不是核心点也不是边界点的点
一些其他的概念
- Eps邻域。简单来讲就是与点
的距离小于等于Eps的所有的点的集合,可以表示为
。
- 直接密度可达。如果
的Eps邻域内,则称对象
- 密度可达。对于对象链:
,
是从
关于Eps和MinPts直接密度可达的,则对象
是从对象
关于Eps和MinPts密度可达的。
2、算法流程

(流程)
三、实验仿真
在实验中使用了两个测试数据集,数据集的原始图像如下:

(数据集1)

(数据集2)
数据集1相对比较简单。显然我们可以发现数据集1共有两个类,数据集2有四个类,下面我们通过DBSCAN算法实现数据点的聚类:
MATLAB代码
主程序
- %% DBSCAN
- clear all;
- clc;
- %% 导入数据集
- % data = load(‘testData.txt‘);
- data = load(‘testData_2.txt‘);
- % 定义参数Eps和MinPts
- MinPts = 5;
- Eps = epsilon(data, MinPts);
- [m,n] = size(data);%得到数据的大小
- x = [(1:m)‘ data];
- [m,n] = size(x);%重新计算数据集的大小
- types = zeros(1,m);%用于区分核心点1,边界点0和噪音点-1
- dealed = zeros(m,1);%用于判断该点是否处理过,0表示未处理过
- dis = calDistance(x(:,2:n));
- number = 1;%用于标记类
- %% 对每一个点进行处理
- for i = 1:m
- %找到未处理的点
- if dealed(i) == 0
- xTemp = x(i,:);
- D = dis(i,:);%取得第i个点到其他所有点的距离
- ind = find(D<=Eps);%找到半径Eps内的所有点
- %% 区分点的类型
- %边界点
- if length(ind) > 1 && length(ind) < MinPts+1
- types(i) = 0;
- class(i) = 0;
- end
- %噪音点
- if length(ind) == 1
- types(i) = -1;
- class(i) = -1;
- dealed(i) = 1;
- end
- %核心点(此处是关键步骤)
- if length(ind) >= MinPts+1
- types(xTemp(1,1)) = 1;
- class(ind) = number;
- % 判断核心点是否密度可达
- while ~isempty(ind)
- yTemp = x(ind(1),:);
- dealed(ind(1)) = 1;
- ind(1) = [];
- D = dis(yTemp(1,1),:);%找到与ind(1)之间的距离
- ind_1 = find(D<=Eps);
- if length(ind_1)>1%处理非噪音点
- class(ind_1) = number;
- if length(ind_1) >= MinPts+1
- types(yTemp(1,1)) = 1;
- else
- types(yTemp(1,1)) = 0;
- end
- for j=1:length(ind_1)
- if dealed(ind_1(j)) == 0
- dealed(ind_1(j)) = 1;
- ind=[ind ind_1(j)];
- class(ind_1(j))=number;
- end
- end
- end
- end
- number = number + 1;
- end
- end
- end
- % 最后处理所有未分类的点为噪音点
- ind_2 = find(class==0);
- class(ind_2) = -1;
- types(ind_2) = -1;
- %% 画出最终的聚类图
- hold on
- for i = 1:m
- if class(i) == -1
- plot(data(i,1),data(i,2),‘.r‘);
- elseif class(i) == 1
- if types(i) == 1
- plot(data(i,1),data(i,2),‘+b‘);
- else
- plot(data(i,1),data(i,2),‘.b‘);
- end
- elseif class(i) == 2
- if types(i) == 1
- plot(data(i,1),data(i,2),‘+g‘);
- else
- plot(data(i,1),data(i,2),‘.g‘);
- end
- elseif class(i) == 3
- if types(i) == 1
- plot(data(i,1),data(i,2),‘+c‘);
- else
- plot(data(i,1),data(i,2),‘.c‘);
- end
- else
- if types(i) == 1
- plot(data(i,1),data(i,2),‘+k‘);
- else
- plot(data(i,1),data(i,2),‘.k‘);
- end
- end
- end
- hold off
距离计算函数
- %% 计算矩阵中点与点之间的距离
- function [ dis ] = calDistance( x )
- [m,n] = size(x);
- dis = zeros(m,m);
- for i = 1:m
- for j = i:m
- %计算点i和点j之间的欧式距离
- tmp =0;
- for k = 1:n
- tmp = tmp+(x(i,k)-x(j,k)).^2;
- end
- dis(i,j) = sqrt(tmp);
- dis(j,i) = dis(i,j);
- end
- end
- end
epsilon函数
- function [Eps]=epsilon(x,k)
- % Function: [Eps]=epsilon(x,k)
- %
- % Aim:
- % Analytical way of estimating neighborhood radius for DBSCAN
- %
- % Input:
- % x - data matrix (m,n); m-objects, n-variables
- % k - number of objects in a neighborhood of an object
- % (minimal number of objects considered as a cluster)
- [m,n]=size(x);
- Eps=((prod(max(x)-min(x))*k*gamma(.5*n+1))/(m*sqrt(pi.^n))).^(1/n);
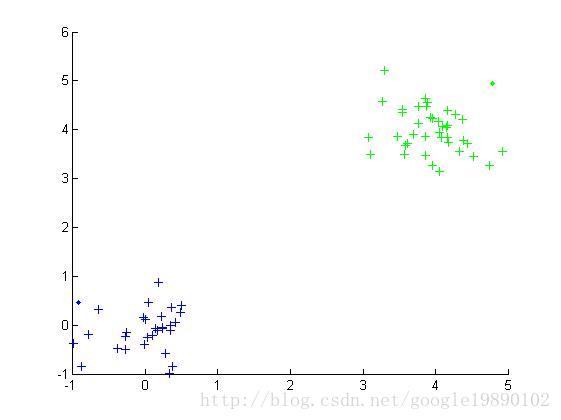
(数据集1的聚类结果)
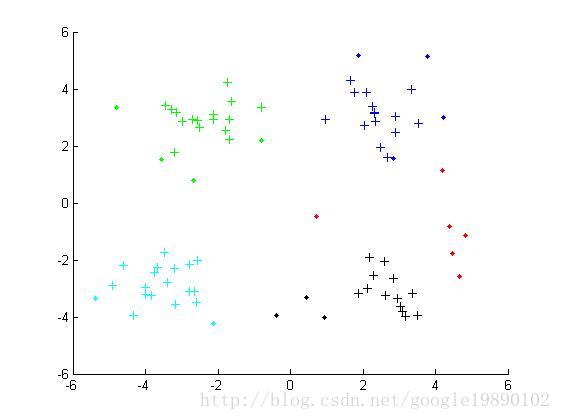
(数据集2的聚类结果)
在上面的结果中,红色的点代表的是噪音点,点代表的是边界点,十字代表的是核心点。不同的颜色代表着不同的类。
参考文献
[1] M. Ester, H. Kriegel, J. Sander, X. Xu, A density-based algorithm for discovering clusters in large spatial databases with noise, www.dbs.informatik.uni-muenchen.de/cgi-bin/papers?query=--CO
[2] M. Daszykowski, B. Walczak, D. L. Massart, Looking for Natural Patterns in Data. Part 1: Density Based Approach
[2] M. Daszykowski, B. Walczak, D. L. Massart, Looking for Natural Patterns in Data. Part 1: Density Based Approach
以上是关于简单易学的机器学习算法——基于密度的聚类算法DBSCAN的主要内容,如果未能解决你的问题,请参考以下文章