什么是支持向量机?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了什么是支持向量机?相关的知识,希望对你有一定的参考价值。
什么是支持向量机?支持向量机基本概念 SVM算法是一种学习机制,是由Vapnik提出的旨在改善传统神经网络学习方法的理论弱点,最先从最优分
参考技术A 什么是支持向量机?支持向量机基本概念SVM算法是一种学习机制,是由Vapnik提出的旨在改善传统神经网络学习方法的理论弱点,最先从最优分类面问题提出了支持向量机网络。SVM学习算法根据有限的样本信息在模型的复杂性和学习能力之间寻求最佳折中,以期获得最好的泛化能力。SVM在形式上类似于多层前向网络,而且已被应用于模式识别、回归分析、数据挖掘等方面。
支持向量机这些特点是其他学习算法(如人工神经网络)所不及的。对于分类问题,单层前向网络可解决线性分类问题,多层前向网络可解决非线性分类问题。但这些网络仅仅能够解决问题,并不能保证得到的分类器是最优的;而基于统计学习理论的支持向量机方法能够从理论上实现对不同类别间的最优分类,通过寻找最坏的向量,即支持向量,达到最好的泛化能力。
SVM总的来说可以分为线性SVM和非线性SVM两类。线性SVM是以样本间的欧氏距离大小为依据来决定划分的结构的。非线性的SVM中以卷积核函数代替内积后,相当于定义了一种广义的趾离,以这种广义距离作为划分依据。
模糊支持向量机有两种理解:一种是针对多定义样本或漏分样本进行模糊后处理;另一种是在训练过程中引入模糊因子作用。
SVM在量化投资中的应用主要是进行金融时序数列的预测。根据基于支持向量机的时间序列预测模型,先由训练样本对模型进行训练和完备,然后将时间序列数据进行预测并输出预测结果。
本章介绍的第一个案例是一种基于最小二乘法的支持向最机的复杂金融数据时间序列预测方法,大大提高了求解问题的速度和收敛精度。相比于神经网络预测方法,该方法在大批量金融数据时间序列预测的训练时间、训练次数和预测误差上都有了明显提高,对复杂金融时间序列具有较好的预测效果。
第二个案例是利用SVM进行大盘拐点判断,由于使用单一技术指标对股价反转点进行预测存在较大的误差,所以使用多个技术指标组合进行相互验证就显得特别必要。SVM由于采用了结构风险最小化原则,能够较好地解决小样本非线性和高维数问题,因此通过构造一个包含多个技术指标组合的反转点判断向最,并使用SVM对技术指标组合向量进行数据挖掘,可以得到更加准确的股价反转点预测模型。
支持向量机基本概念
SVM算法是一种学习机制,是由Vapnik提出的旨在改善传统神经网络学习方法的理论弱点,最先从最优分类面问题提出了支持向量机网络。
SVM学习算法根据有限的样本信息在模型的复杂性和学习能力之间寻求最佳折中,以期获得最好的泛化能力。SVM在形式上类似于多层前向网络,而且己被应用于模式识别、回归分析、数据挖掘等方面。支持向量机方法能够克服多层前向网络的固有缺陷,它有以下几个优点:
(1)它是针对有限样本情况的。根据结构风险最小化原则,尽量提高学习机的泛化能力,即由有限的训练样本得到小的误差,能够保证对独立的测试集仍保持小的误差,其目标是得到现有信息下的最优解,而不仅仅是样本数趋于无穷大时的最优值。
(2)算法最终将转化成一个二次型寻优问题,从理论上说,得到的将是全局最优点。
(3)算法将实际问题通过非线性变换转换到高维的特征空间,在高维空间中构造线性判别函数来实现原空间中的非线性判别函数,这一特殊的性质能保证机器有较好的泛化能力,同时它巧妙地解决了维数灾难问题,使得其算法复杂度与样本维数无关。
6.支持向量机(SVM)什么是SVM支持向量机基本原理与思想基本原理课程中关于SVM介绍
6.支持向量机(SVM)
6.1.什么是SVM
6.2.支持向量机基本原理与思想
6.2.1.支持向量机
6.2.2.基本原理
6.3.课程中关于SVM介绍
6.支持向量机(SVM)
6.1.什么是SVM
以下转自:https://www.zhihu.com/question/21094489
支持向量机/support vector machine (SVM)。
可以从一个了解什么是SVM,以及要做的事情。
在很久以前的情人节,大侠要去救他的爱人,但魔鬼和他玩了一个游戏。
魔鬼在桌子上似乎有规律放了两种颜色的球,说:“你用一根棍分开它们?要求:尽量在放更多球之后,仍然适用。”

于是大侠这样放,干的不错?

然后魔鬼,又在桌上放了更多的球,似乎有一个球站错了阵营。
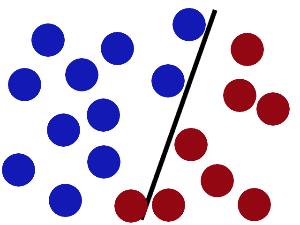
SVM就是试图把棍放在最佳位置,好让在棍的两边有尽可能大的间隙。
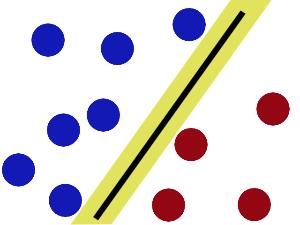
现在即使魔鬼放了更多的球,棍仍然是一个好的分界线。

然后,在SVM 工具箱中有另一个更加重要的 trick。 魔鬼看到大侠已经学会了一个trick,于是魔鬼给了大侠一个新的挑战。
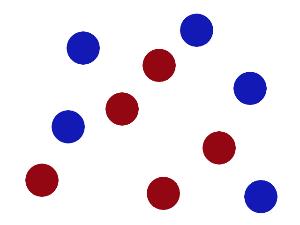
现在,大侠没有棍可以很好帮他分开两种球了,现在怎么办呢?当然像所有武侠片中一样大侠桌子一拍,球飞到空中。然后,凭借大侠的轻功,大侠抓起一张纸,插到了两种球的中间。
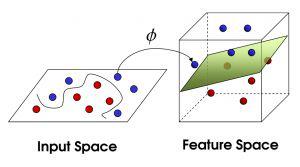
现在,从魔鬼的角度看这些球,这些球看起来像是被一条曲线分开了。
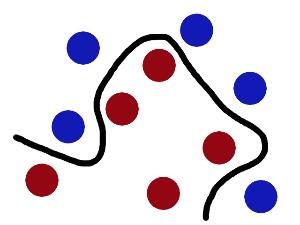
再之后,无聊的大人们,把这些球叫做**「data」,把棍子 叫做「classifier」, 最大间隙trick 叫做「optimization」, 拍桌子叫做「kernelling」, 那张纸叫做「hyperplane」**
6.2.支持向量机基本原理与思想
6.2.1.支持向量机
SVM即支持向量机(Support Vector Machine),是有监督学习算法的一种,用于解决数据挖掘或模式 识别领域中数据分类问题。
6.2.2.基本原理
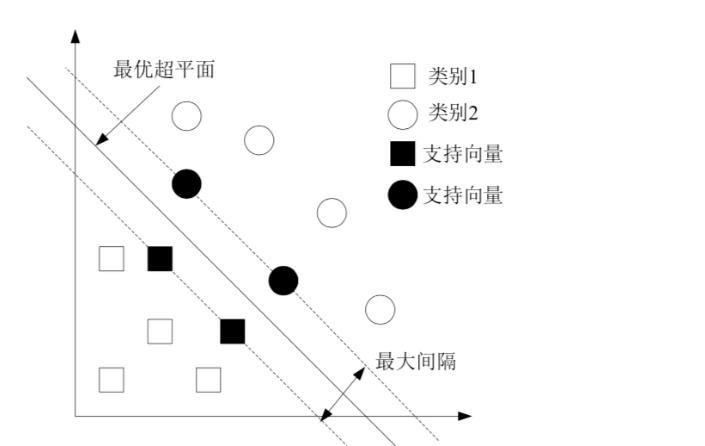
SVM算法 即寻找一个分类器使得超平面和最近的数据点之间的分类边缘(超平面和最近的数据点之间的 间隔被称为分类边缘)最大,对于SVM算法通常认为分类边缘越大,平面越优,通常定义具有“最大间隔”的决策面就是 SVM 要寻找的最优解。并且最优解对应两侧虚线要穿过的样本点,称为“支持向量”。其处理的基本思路为:把问题转化为一个凸二次规划 问题,可以用运筹学有关思想进行求解:
(1)目标函数
在线性SVM算法中,目标函数显然就是那个"分类间隔",使分类间隔最大。
(2)约束条件
即决策面,通常需要满足三个条件:
1)确定决策面使其正确分类。
2)决策面在间隔区域的中轴线。
3)如何确定支持向量因此求解SVM问题即转化为求解凸二次规划的最优化问题。
支持向量机:就是用来分割数据点那个分割面,他的位置是由支持向量确定的(如果支持 向量发生了变化,往往分割面的位置也会随之改变), 因此这个面就是一个支持向量确定的 分类器即支持向量机。
线性可分数据的二值分类机理:系统随机产生一个超平面并移动它,直到训练集中属于不同类别的样本点正好位于该超平面的两侧。显然,这种机理能够解决线性分类问题,但不能够保证产生的超平面是最优的。支持向量机建立的分类超平面能够在保证分类精度的同时, 使超平面两侧的空白区域最大化,从而实现对线性可分问题的最优分类。
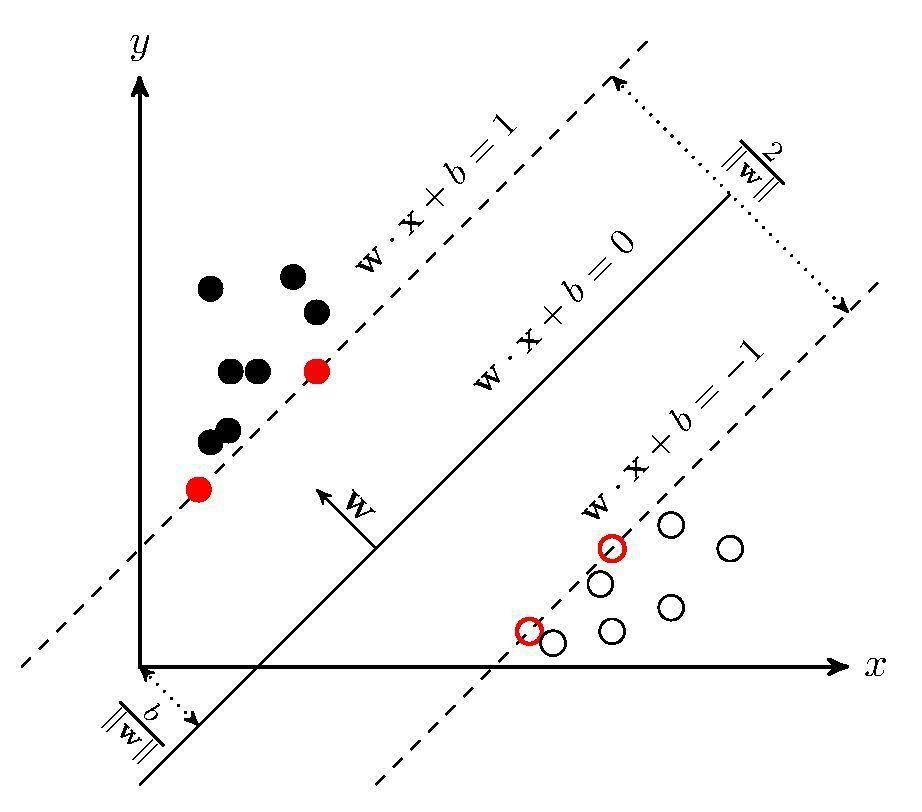
SVM的主要思想是:建立一个最优决策超平面,使得该平面两侧距平面最近的两类样 本之间的距离最大化,从而对分类问题提供良好的泛化力(推广能力)。
支持向量:则是指训练集中的某些训练点,这些点最靠近分类决策面,是最难分类的数据点。
SVM: 它是一种有监督(有导师)学习方法,即已知训练点的类别,求训练点和类别之间的对应关系,以便将训练集按照类别分开,或者是预测新的训练点所对应的类别。
6.3.课程中关于SVM介绍
Support Vector Machine
- 决策边界:选出来离雷区最远的(雷区就是边界上的点,要Large Margin)
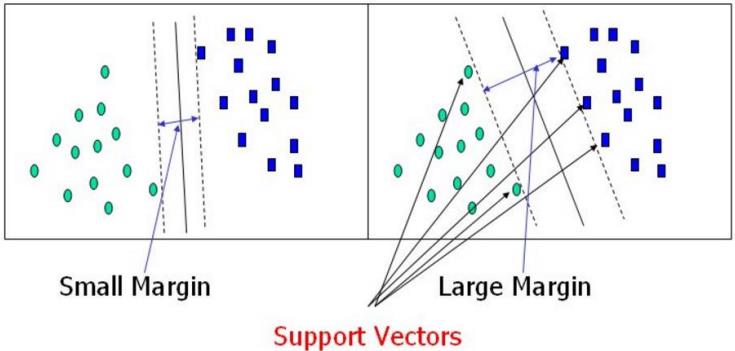
距离的计算
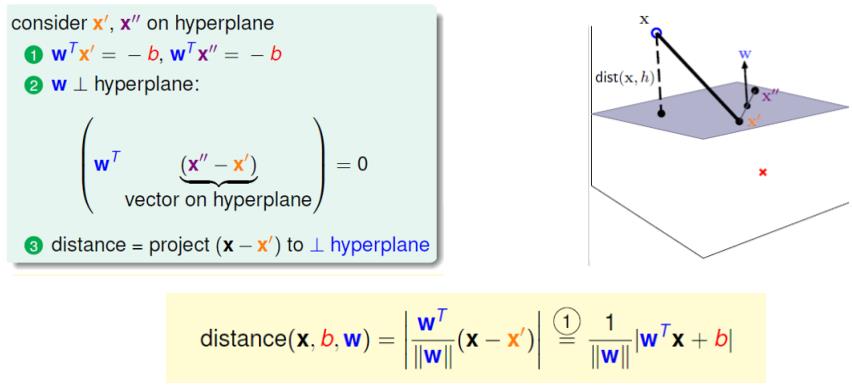






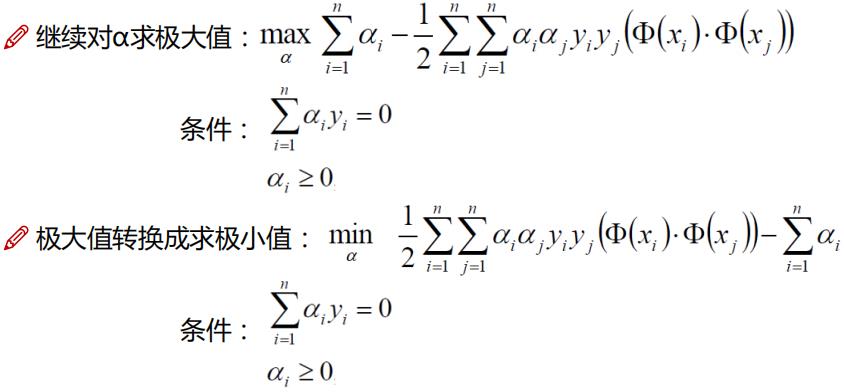
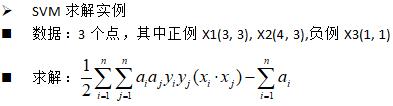
约束条件: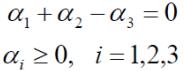
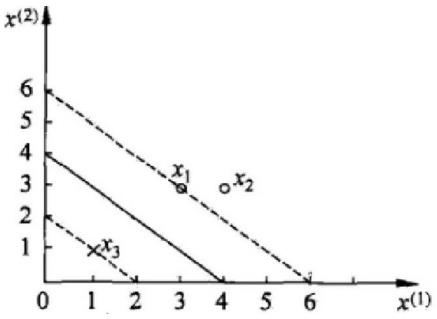
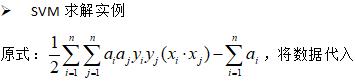
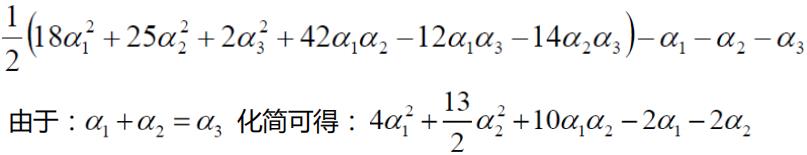


最小值在(0.25, 0, 0.25)处取得
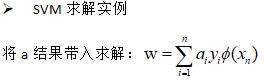
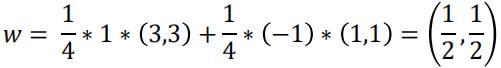
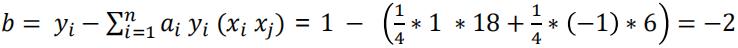
- 平面方程为:
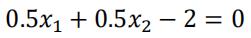
SVM求解实例
支持向量:真正发挥作用的数据点,a值不为0的点。
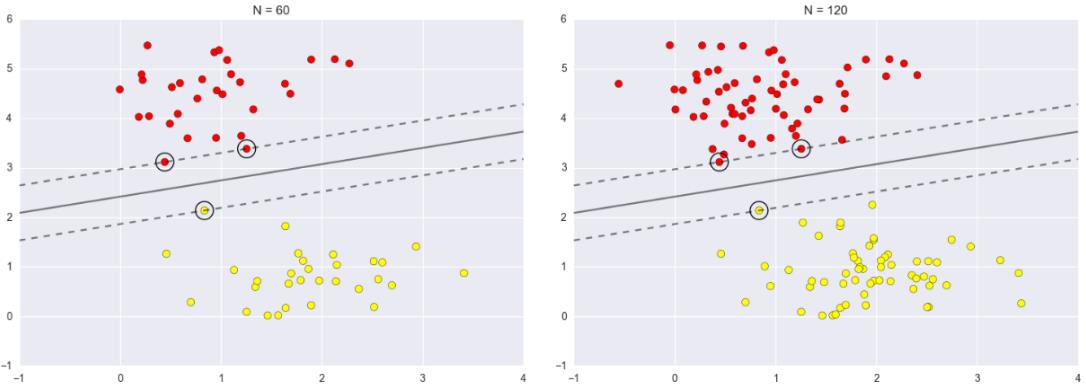
soft-margin
-
软间隔:有时候数据中有一些噪音点,如果考虑它们咱们的线就不太好了。
-
之前的方法要求要把两类点完全分得开,这个要求有点过于严格了,我们来放松一点!
-
为了解决该问题,引入松弛因子

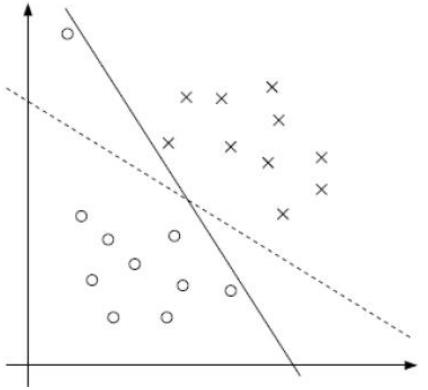
soft-margin -
新的目标函数:

-
当C趋近于很大时:意味着分类严格不能有错误。
当C趋近于很小时:意味着可以有更大的错误容忍 -
C是我们需要指定的一个参数!

Soft-margin -
拉格朗日乘子法:

低维不可分问题 -
核变换:既然低维的时候不可分,那我给它映射到高维呢?
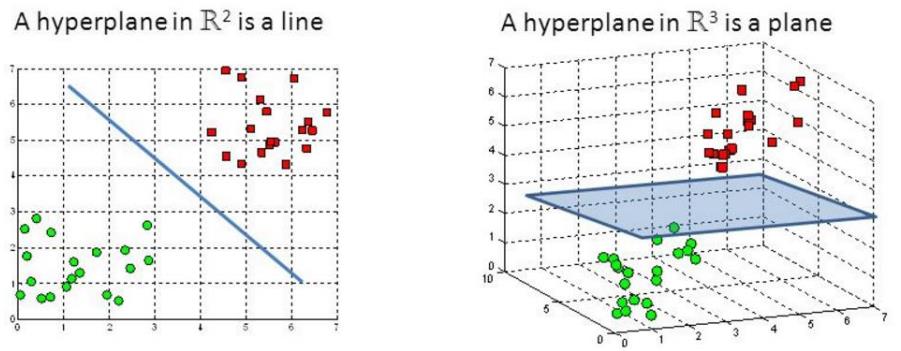
低维不可分问题 -
目标:找到一种变换的方法,也就是

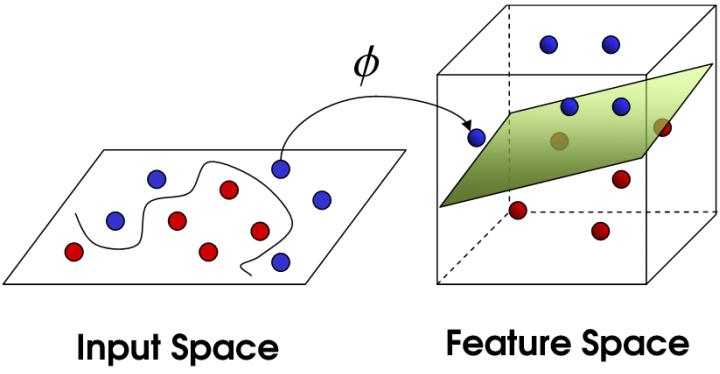
Support Vector Machine
高斯核函数:
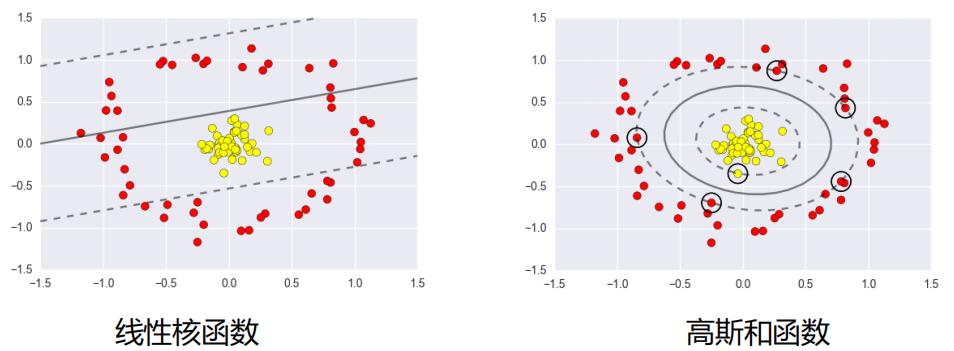
以上是关于什么是支持向量机?的主要内容,如果未能解决你的问题,请参考以下文章