哈希表与红黑树
Posted 光影键盘侠
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了哈希表与红黑树相关的知识,希望对你有一定的参考价值。
哈希表 & 红黑树
喜欢用C++的同学都应该知道map这个STL中的数据结构,也许也或多或少的用过unordered_map这个结构,包括set和unordered_set。那么他们之间到底有多少联系?它们是否是一样的东西呢?今天Sun君邀请了在某美国知名外企具有两年工作经验的Star君来给大家介绍一下它们。
为了展开下面的讨论,Sun君可以先回答大家上面的问题。以map为例,STL中的map和unordered_map并不是同样的数据结构实现的,它们在复杂度和性能上也是有很大的区别的。
其中map(set)是用红黑树来实现的,而unordered_map(unordered_set)则是由大家最熟悉的哈希表实现的。
map & 红黑树
map
01
map的定义
map的特性就是,所有的元素都会根据元素的key来自动排序。Map的所有元素都是pair,同时拥有value和key。Pair的第一个元素被视为key,而第二个元素则被视为value。以下是map的结构定义:
由于红黑树是一种平衡二叉搜索树,自动排序的效果很好,所有map即以红黑树为底层机制。由于map的各种操作接口,在红黑树中也都提供了,所以几乎所有的map操作,都只是转调用了红黑树的操作。
那么接下来我们就详细介绍一下红黑树的特征。
红黑树(RB-Tree)
笔者认为任何一家公司都不应将红黑树作为笔试或白板面试的考点,因为它的换孩子、认叔叔操作实在过于复杂,而死记硬背又毫无意义。但是,了解红黑树对理解自平衡树还是很有帮助的,所以这里还是简要介绍一下。
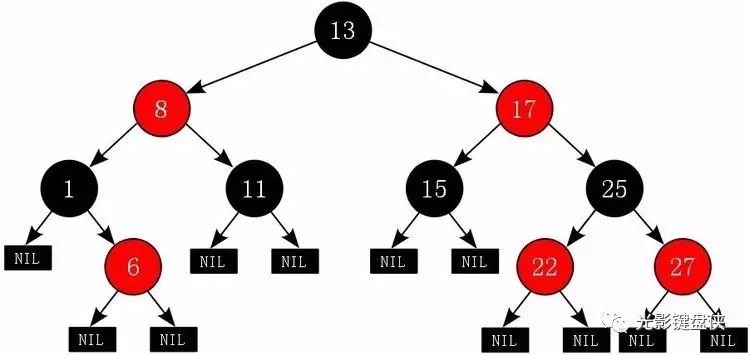
01
红黑树的定义
红黑树是一种特殊的二叉搜索树(Binary Search Tree, 简称BST)。和其他BST一样,它包含一系列可互相比较(Comparable)的数据,例如字符串、数字等,并允许通过中序遍历得到数据的排序。红黑树的叶结点(NIL结点)不包含数据,在实现中,一般让所有的叶结点指向同一个空结点即可。在搜索红黑树中的某个数据时,如果红黑树的高度最小(红黑树完全平衡),时间复杂度可以达到O(log(n))。
02
红黑树的特殊意义
红黑树可以让二叉搜索树保持“大致平衡”。我们可以很容易发现,在搜索一棵二叉树时,最坏情况是当所有结点都只有左/右孩子的情况。我们可以想象这样一种情况,当根结点是数据中最小的元素,根结点的右孩子是数据中第二小的元素,依次类推。这时二叉搜索树退化为一个链表,它的搜索时间将变为O(n)。
稍加引申,我们便可以发现,二叉搜索树表现最好的情况,是对于树中的任意一个结点出发向下,抵达树最底端叶结点的所有路径长度都相同,即树“完全平衡”。那么,让二叉树变得平衡便成为数据结构设计者的目标。AVL树作为一种严格平衡的树率先出现,但是它的插入和删除复杂度都要大于红黑树,因此更适用于不会发生改变的数据。红黑树则是在“平衡程度”、“插入删除复杂度”之间达到了一个平衡。
03
红黑树的实现
红黑树具有一些简单的性质:
每个结点不是红色就是黑色
根结点是黑色的
所有叶结点都是黑色的
如果一个结点是红色的,那么它的两个子结点一定是黑色的
对于所有结点来说,从该结点向下到任意叶结点的路径,其中包含的黑色结点数量必须相同。
这里引申两个定义:
对于根结点,它到所有叶结点的路径中黑色结点数量的最大值,叫做这个红黑树的黑高度。
对于某个结点来说,从根结点到它的路径中黑色结点的数量,叫做这个结点的黑深度。
红黑树的定义如何确保树的“大致平衡”?
首先,让我们想象一下,如果红黑树里只有黑色结点,那么这棵树是平衡树吗?当然是。假设树不平衡,也就是说,从某个结点向下,到所有叶结点的路径长度不同。那么这些路径中包含的结点数一定不同。由于所有结点都是黑色的,将不满足红黑树的性质5。所以一棵所有结点都是黑色的红黑树一定是严格平衡的。
那么,红色结点又是用来干什么的?对于一棵完全平衡,且所有结点都是黑色的红黑树,我们可不可以在一个黑色的父节点,和一个黑色的子结点之间,插入一个红色的结点呢?答案是可以的,因为它满足性质4。那么现在这棵树还平衡吗?答案是否定的。但是,它仍然符合红黑树的定义。
现在我们思考一下,最多可以插入多少个红色结点呢?我们知道,根据性质4,红色结点不能彼此相连,所以在一条路径上,我们最多可以插入和黑色结点数量相同的红色结点。由此,我们可以得到红黑树的另一条重要性质:
从红黑树的根结点到最远的叶结点的路径长度,不超过根结点到最近的叶结点路径长度的2倍
这一条性质确保了红黑树是“大致平衡”的,因此红黑树在最差情况下(即最短路径全是黑结点,最长路径是最短路径中插入和黑结点数量相同的红结点),仍然可以保障搜索的效率。
红黑树的插入、删除
红黑树的插入和删除要考虑多种情况(插入5种,删除6种),限于篇幅本文不加赘述,大家可以自行搜索资料进行学习。
红黑树的应用
红黑树在很多需要保证二叉搜索树性能的地方都有应用。
举两个典型的例子:
1)Java 8的HashMap使用红黑树代替链表解决哈希碰撞
2)Linux的Completely Fair Scheduler使用红黑树按照时间顺序存储任务
以上便是对红黑树的一个简要介绍,希望大家以后需要用到自平衡的二叉搜索树时,能够想到它。
unordered_map & 哈希表
unordered_map
01
unordered_map的定义
Unordered_map和map类似,都是key和value组成的,最大的不同就是,Unordered_map不会根据key的大小进行排序,所以它的内部元素是无需的。
unordered_map是由hashtable来实现的。所以unorderd_map是由hashtable来实现的,同样,它的所有操作借口也基本上都被hashtable提供了,所以unordered_map操作也只是转调用了hashtable的操作行为。
如果只是为了能够根据kay快速找到value,那么无论底层是RB-Tree还是hashtable,都可以达到任务。而如果需要自动排序的功能,则只能选择RB-Tree来实现。
那么接下来我们就详细介绍一下hashtable的特征。
Hashtable想必大家都很熟悉了,就是通过某个key找到对应的value,比较重要的部分就是hash function。
哈希函数(Hash Function)
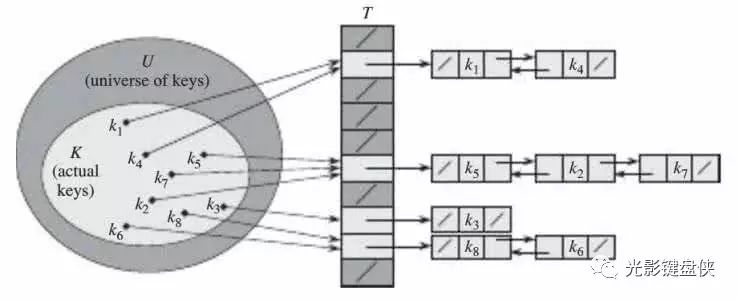
01
hash function的定义
哈希函数是一类函数的总称,它们都具有同样的性质:
将任意范围的输入集合映射到一个范围确定的输出集合
对于每一个输入值,其输出值是唯一的(这里输出值叫做哈希值hash value,或者摘要digest)
如果输出值不同,那么输入值一定不同
如果输出值相同,那么输入值不一定相同(这种情况叫做哈希碰撞hashcollision)
一个好的哈希函数应该让输出值的分布尽量均匀(或者说每个输出值被映射到的概率大致相同)
不可逆:从输出值很难逆推回输入值,除非进行暴力搜索
不连续:大多数情况下,我们希望哈希函数的连续性较差。也就是说,对于近似的输入值,输出值截然不同。
一个简单的哈希函数
说了这么多哈希函数的性质,不实际写一个有点说不过去,这里就介绍最常用的哈希函数之一,将一个字符串char[]映射为整型int的Java代码:
输入"hello world"即可得到它的哈希值:1923188771。
02
哈希函数的应用
保护明文密码
哈希函数不能用来加密,因为根据哈希函数的不可逆性,很难通过暴力搜索以外的方法将一个哈希值转换为原始输入值。但是,哈希函数确实在安全领域有很多应用。比如,著名的MD5算法,就曾经广泛被用于对明文密码进行哈希变换,并存储于数据库当中。这样,如果用户输入相同的密码,我们得到的哈希值是相同的,仍然可以进行验证。然而,如果数据库信息不幸泄露,黑客很难从哈希值中逆推用户的原始明文密码。实践中,黑客会使用彩虹表(Rainbowtable)加速破解过程,因此一般会使用加盐(salt)的方法提高破解难度,比如:MD5(MD5(password)+salt)。这里的salt是一个字符串常量,用来对密码进行混淆。
哈希表
哈希表几乎存在于所有的计算机系统中,它是一种经典的将O(n)查表操作简化为O(1)操作的方法。对于任意的输入值,我们可以使用哈希函数将其转换为对定长数组中某一元素的访问,从而极大地降低搜索难度。常见的哈希表实现有:C++STL中的unordered_map和unordered_set,以及Java中的HashSet和HashMap。聪明的同学一定会发现,如果发生了哈希碰撞,同一个数组下标可能包含多个元素。那么此时我们有两种常见的处理方法:一种是使用链表、红黑树等数据结构扩展一个数组下标的容量,使得在碰撞的情况下,我们仍然可以存储发生碰撞的元素。然而,当输入值数量逐渐增加而哈希表的容量不变,碰撞将变得更加常见,而哈希表的性能也会逐渐下降。此时,我们一般需要将哈希表的输出范围进行扩展(一般是原来的2倍),并对每个输入值进行重新映射,这个过程叫做重哈希。
文件指纹
哈希函数可以用来得到一个文件内容的哈希值,并用来防止文件内容被篡改,这要求哈希函数的几乎不会发生碰撞。这是因为,如果黑客想对文件进行篡改而希望它的哈希值不变,他必须找到一种方法,能够让篡改后的文件内容和原来的内容发生哈希碰撞。SHA-1曾经是一个广泛用于文件指纹的哈希函数,然而近期Google发现了一种针对SHA-1生成碰撞的方法,因此SHA-1现在被认为已经遭到破坏,但是不用担心,我们还有SHA-2,SHA-3。:)
Bloom filter
Bloom filter可能不是十分常见,但它十分有趣。这是一种用来快速确定一个输入值是否属于一个集合的方法。然而,它不是100%可靠的,也就是说,它可以判断输入值是否一定不属于集合A,或者很可能属于A,但是不能判断它是否一定属于A。说起来可能有点绕,但是它实际上体现的正是哈希函数的性质。bloomfilter等价于对所有集合A中的元素求哈希值并建立一个新的集合B。由于哈希碰撞的可能性,如果某一个元素的哈希值出现在B中,我们并不能判断它是否一定属于A。但是,如果它的哈希值没有出现在B中,则它一定不属于A。实践当中,一般会采用多个哈希函数求多个哈希值来减少碰撞带来的错误率。
哈希背后的思想其实和目录差不多,都是截取数据的一部分信息建立索引,因此哈希算法也叫做信息摘要算法。希望大家经过以上介绍,对它的应用有了一定的了解。
总结
由unordered_map和map引出了两种非常重要的数据结构,在面试中也常常被考到,也希望大家在做这一类题的时候,不能只是了解怎么用,还是应该多去理解其中的内涵。
欢迎关注
以上是关于哈希表与红黑树的主要内容,如果未能解决你的问题,请参考以下文章