3天掌握Spark--搜狗日志统计分析联系
Posted 一只楠喃
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了3天掌握Spark--搜狗日志统计分析联系相关的知识,希望对你有一定的参考价值。
SogouQ日志分析
数据调研和业务分析
使用搜狗实验室提供【用户查询日志(SogouQ)】数据,使用Spark框架,将数据封装到RDD中进行业务数据处理分析。
- 1)、数据介绍:
搜索引擎查询日志库设计为包括约1个月(2008年6月)Sogou搜索引擎部分网页查询需求及用户点击情况的网页查询日志数据集合。
- 2)、数据格式
访问时间\\t用户ID\\t[查询词]\\t该URL在返回结果中的排名\\t用户点击的顺序号\\t用户点击的URL

3)、数据下载:分为三个数据集,大小不一样
迷你版(样例数据, 376KB):
http://download.labs.sogou.com/dl/sogoulabdown/SogouQ/SogouQ.mini.zip
精简版(1天数据,63MB):
http://download.labs.sogou.com/dl/sogoulabdown/SogouQ/SogouQ.reduced.zip
完整版(1.9GB):
http://www.sogou.com/labs/resource/ftp.php?dir=/Data/SogouQ/SogouQ.zip
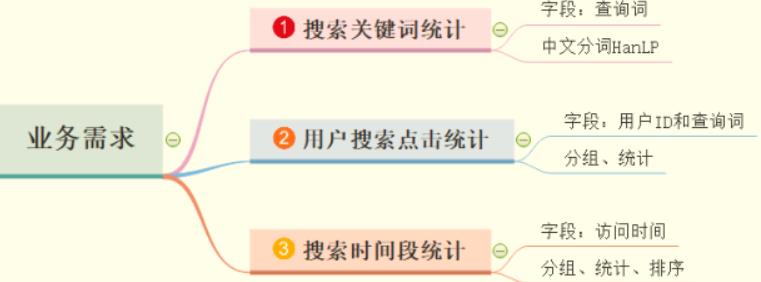
针对SougouQ查询日志数据,分析业务需求:
使用SparkContext读取日志数据,封装到RDD数据集中,调用Transformation函数和Action函数处
理分析,灵活掌握Scala语言编程。
HanLP 中文分词
使用比较流行好用中文分词:HanLP,面向生产环境的自然语言处理工具包,HanLP 是由一系列模型与算法组成的 Java 工具包,目标是普及自然语言处理在生产环境中的应用。
官方网站:http://www.hanlp.com/,添加Maven依赖
<!-- https://mvnrepository.com/artifact/com.hankcs/hanlp -->
<dependency>
<groupId>com.hankcs</groupId>
<artifactId>hanlp</artifactId>
<version>portable-1.7.7</version>
</dependency>
演示范例
object HanLpTest {
def main(args: Array[String]): Unit = {
// 入门Demo
val terms: util.List[Term] = HanLP.segment("杰克奥特曼全集视频")
println(terms)
import scala.collection.JavaConverters._
println(terms.asScala.map(term => term.word.trim))
// 标准分词
val terms1: util.List[Term] = StandardTokenizer.segment("放假++端午++重阳")
println(terms1.asScala.map(_.word.replaceAll("\\\\s+", "")))
}
}
数据封装SogouRecord
将每行日志数据封装到CaseClass样例类SogouRecord中,方便后续处理
/**
* 用户搜索点击网页记录Record
*
* @param queryTime 访问时间,格式为:HH:mm:ss
* @param userId 用户ID
* @param queryWords 查询词
* @param resultRank 该URL在返回结果中的排名
* @param clickRank 用户点击的顺序号
* @param clickUrl 用户点击的URL
*/
case class SogouRecord(
queryTime: String, //
userId: String, //
queryWords: String, //
resultRank: Int, //
clickRank: Int, //
clickUrl: String //
)
构建
SparkContext实例对象,读取本次SogouQ.sample数据,封装到SougoRecord中 。
// 在Spark 应用程序中,入口为:SparkContext,必须创建实例对象,加载数据和调度程序执行
val sc: SparkContext = {
// 创建SparkConf对象
val sparkConf: SparkConf = new SparkConf()
.setAppName(this.getClass.getSimpleName.stripSuffix("$"))
.setMaster("local[2]")
// 构建SparkContext实例对象
SparkContext.getOrCreate(sparkConf)
}
// TODO: 1. 从本地文件系统读取搜索日志数据
val rawLogsRDD: RDD[String] = sc.textFile("datas/sogou/SogouQ.sample", minPartitions = 2)
//println(s"First:\\n ${rawLogsRDD.first()}")
//println(s"Count: ${rawLogsRDD.count()}")
// TODO: 2. 解析数据(先过滤不合格的数据),封装样例类SogouRecord对象
val sogouLogsRDD: RDD[SogouRecord] = rawLogsRDD
// 过滤数据
.filter(log => null != log && log.trim.split("\\\\s+").length == 6)
// 解析日志,封装实例对象
.mapPartitions(iter => {
iter.map(log => {
// 安装分隔符划分数据
val split: Array[String] = log.trim.split("\\\\s+")
// 构建实例对象
SogouRecord(
split(0),
split(1), //
split(2).replaceAll("\\\\[", "").replace("]", ""),
split(3).toInt,
split(4).toInt,
split(5)
)
})
})
//println(s"Count = ${sogouLogsRDD.count()}")
//println(s"First: ${sogouLogsRDD.first()}")
补充知识点!!!
正则表达式中\\s匹配任何空白字符,包括空格、制表符、换页符等等, 等价于[ \\f\\n\\r\\t\\v]
\\f -> 匹配一个换页
\\n -> 匹配一个换行符
\\r -> 匹配一个回车符
\\t -> 匹配一个制表符
\\v -> 匹配一个垂直制表符
而“\\s+”则表示匹配任意多个上面的字符。另因为反斜杠在Java里是转义字符,所以在Java里,我们要这么用“\\\\s+”.
那么问题来了,“\\\\s+”有啥使用场景呢?
注:
[\\s]表示,只要出现空白就匹配
[\\S]表示,非空白就匹配
搜索关键词统计
获取用户【查询词】,使用HanLP进行分词,按照单词分组聚合统计出现次数,类似WordCount程序,具体代码如下:
第一步、获取每条日志数据中【查询词queryWords】字段数据
第二步、使用HanLP对查询词进行中文分词
第三步、按照分词中单词进行词频统计,类似WordCount
// TODO: 3. 依据需求对数据进行分析
/*
需求一、搜索关键词统计,使用HanLP中文分词
- 第一步、获取每条日志数据中【查询词`queryWords`】字段数据
- 第二步、使用HanLP对查询词进行中文分词
- 第三步、按照分词中单词进行词频统计,类似WordCount
*/
val queryKeyWordsCountRDD: RDD[(String, Int)] = sogouLogsRDD
// 提取查询词字段的值
.flatMap { record =>
val query: String = record.queryWords
// 使用HanLP分词
val terms: util.List[Term] = HanLP.segment(query.trim)
// 转换为Scala中集合列表,对每个分词进行处理
terms.asScala.map(term => term.word.trim)
}
// 转换每个分词为二元组,表示分组出现一次
.map(word => (word, 1))
// 按照单词分组,统计次数
.reduceByKey((tmp, item) => tmp + item)
//queryKeyWordsCountRDD.take(10).foreach(println)
// TODO: 获取查询词Top10
queryKeyWordsCountRDD
.map(tuple => tuple.swap)
.sortByKey(ascending = false) // 降序排序
.take(10)
.foreach(println)
用户搜索点击统计
统计出每个用户每个搜索词点击网页的次数,可以作为搜索引擎搜索效果评价指标。先按照用户ID分组,再按照【查询词】分组,最后统计次数,求取最大次数、最小次数及平均次数。
/*
需求二、用户搜索次数统计
TODO: 统计每个用户对每个搜索词的点击次数,二维分组:先对用户分组,再对搜索词分组
SQL:
SELECT user_id, query_words, COUNT(1) AS total FROM records GROUP BY user_id, query_words
*/
val clickCountRDD: RDD[((String, String), Int)] = sogouLogsRDD
// 提取字段值
.map(record => (record.userId, record.queryWords) -> 1)
// 按照Key(先userId,再queryWords)分组,进行聚合统计
.reduceByKey(_ + _)
//clickCountRDD.take(50).foreach(println)
//TODO: 单独提取出每个用户搜索时次数,进行统计
val countRDD: RDD[Int] = clickCountRDD.map(tuple => tuple._2)
println(s"Max Click Count: ${countRDD.max()}")
println(s"Min Click Count: ${countRDD.min()}")
println(s"stats Click Count: ${countRDD.stats()}") // 数理统计
搜索时间段统计
按照【访问时间】字段获取【小时】,分组统计各个小时段用户查询搜索的数量,进一步观察用户喜欢在哪些时间段上网,使用搜狗引擎搜索。
/*
需求三、搜索时间段统计, 按照每个小时统计用户搜索次数
00:00:00 -> 00 提取出小时
*/
val hourCountRDD: RDD[(Int, Int)] = sogouLogsRDD
// 提取时间字段值
.map { record =>
val queryTime = record.queryTime
// 获取小时
val hour = queryTime.substring(0, 2)
// 返回二元组
(hour.toInt, 1)
}
// 按照小时分组,进行聚合统计
.foldByKey(0)(_ + _)
//hourCountRDD.foreach(println)
// TODO: 按照次数进行降序排序
hourCountRDD
.top(24)(Ordering.by(tuple => tuple._2))
.foreach(println)
以上是关于3天掌握Spark--搜狗日志统计分析联系的主要内容,如果未能解决你的问题,请参考以下文章
使用Spark进行搜狗日志分析实例——列出搜索不同关键词超过10个的用户及其搜索的关键词